第5章 高级数据管理
5.1 一个数据处理难题
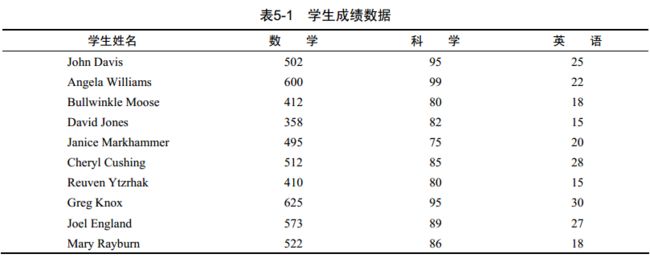
引入一个具体的数据处理问题,需将成绩表中的成绩转换为一个单一的成绩衡量指标,并评定为5个等级,列表按字母顺序排列。
上述的每个人物都可以利用R中的数值和字符处理函数完成。
5.2 数值和字符处理函数
本节综述R中作为数据处理基石的函数,他们分为数值(数学、统计、概率)函数和字符处理函数。
5.2.1 数学函数
数学函数简单用例:
| 函数 | 描述 |
|---|---|
| abs(x) | 绝对值 |
| sqrt(x) | 平方根 |
| ceiling(x) | 不小于x的最小整数 |
| floor(x) | 不大于x的最大整数 |
| trunc(x) | 向0取整 |
| round(x, digits=n) | x舍入为指定位小数 |
| signif(x, digits=n) | x舍入为指定的有效数字位数 |
| cos(x)、sin(x)、tan(x) | 余弦、正弦和正切 |
| acos(x)、asin(x)、atan(x) | 反余弦、反正弦和反正切 |
| cosh(x)、sinh(x)、tanh(x) | 双曲余弦、双曲正弦和双曲正切 |
| acosh(x)、asinh(x)、atanh(x) | 反双曲余弦、反双曲正弦和反双曲正切 |
| log(x, base=n) | 对x取以n为底的对数 |
| log(x) | 自然对数 |
| exp(x) | 指数函数 |
数据变换是这些函数的一个主要用途。在分析之前将存在明显偏倚的变量取对数。数学函数也被用作公式中的一部分,用于绘图函数和在输出结果之前对数值做格式化。
5.2.2 统计函数
常用的统计函数如表5-3所示,其中许多函数都拥有可以影响输出结果的可选参数。
y <- mean(x) 提供对象元素x的算数平均数 z <- mean(x, trim=0.05, na.rm=TRUE) 结尾平均数,丢弃最大最小的5%及缺失值

代码清单5-1 均值和标准差的计算
> x <- c(1,2,3,4,5,6,7,8)
> mean(x)
[1] 4.5
> sd(x) #标准差
[1] 2.44949
> n <- length(x)
> meanx <- sum(x)/n
> css <- sum((x-meanx)^2)
> meanx
[1] 4.5
> n
[1] 8
R中公式的写法和类似MATLAB的矩阵运算语言有着许多共同之处。(附录E中具体关注解决矩阵代数问题的方法)
数据的标准化
默认情况下,函数scale( )对矩阵或数据框的指定列进行均值为0、标准差为1的标准化:
newdata <- scale(mydata)
要对每一列进行任意均值和标准差的标准化,可以使用如下代码:
newdata <- scale(mydata) * SD + M
其中,SD为想要的标准差,M为想要的均值。
对指定列进行标准化:
newdata <- transform(mydata, var = scale(myvar) * 10 + 50)
上面语句将变量myvar标准化为均值50、标准差10的变量。
scale( )只能作用于数值型的列。
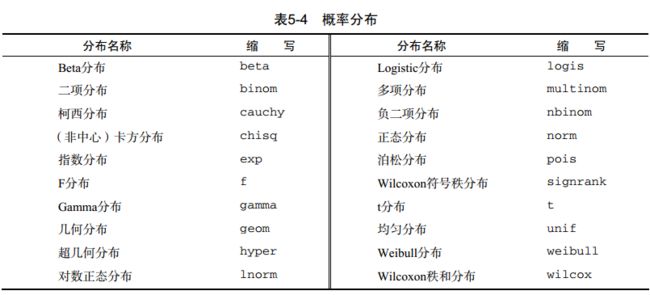
5.2.3 概率函数
概率函数属于统计类,但它们非常独特。概率函数通常用来生成特征已知的模拟数据,以及在用户编写的统计函数中计算概率值。
在R中,概率函数形如:
[dpqr]disrtibution_abbreviation( )
其中第一个字母表示其所指分布的某一方面:d=密度分布(density),p=分布函数(distribution function),q=分位数函数(quantile function),r=生成随机数(随即偏差)。
常用的概率函数如表:
正态分布有关函数示例(如果不指定均值标准差,默认假定为标准正态分布):
> x <- pretty(c(-3, 3), 30)
> #将区间分为30个子区间
> y <- dnorm(x)
> #x的密度函数
> plot(x, y, type="l", xlab="NormalDeviate", ylab="Density", yaxs="i")
> #绘制x,y图像,type=l即线条,x标签,y标签,y轴内在刻度
> pnorm(1.96)
> z=1.96左侧正太曲线下方面积
[1] 0.9750021
> qnorm(.9, mean=500, sd=100)
> #均值500,标准差100的正态分布0.9分为点出数值
[1] 628.1552
> rnorm(50, mean=50, sd=10)
> #生成50个均值50标准差10的生态随机数
[1] 23.66748 52.43212 53.21935 58.84984 63.26850 54.71151 41.81567 60.25580
[9] 63.20254 34.84691 46.95288 63.48646 41.25891 62.02514 44.44631 53.92199
[17] 54.36465 42.30987 60.51695 37.25501 67.47271 50.31629 54.09745 55.35897
[25] 53.21422 39.01114 45.11428 45.16801 56.25568 59.25460 40.02548 58.91883
[33] 42.82648 55.30438 60.45868 45.78615 53.85954 46.58986 66.70875 53.10939
[41] 62.81892 49.30664 61.84514 47.87149 38.49104 58.56616 57.36526 41.90065
[49] 44.75941 41.09071
- 设定随机数种子
在每次生成伪随机数的时候,函数都会使用一个不同的种子,因此也会产生不同的结果。可以通过函数set.seed( )显式指定这个种子,让结果可以重现(reproducible)。代码清单5-2给出了示例,这里的函数runif( )用来生成0到1区间上服从均匀分布的伪随机数。
代码清单5-2 生成服从正太分布的伪随机数
> runif(5)
[1] 0.70155411 0.85210056 0.48671535 0.18585490 0.09385773
> #runif()生成0到1区间上服从均匀分布的伪随机数
> runif(5)
[1] 0.17732966 0.56423384 0.23674773 0.65050771 0.03126517
> set.seed(1234)
> #设定种子
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
> runif(5)
[1] 0.640310605 0.009495756 0.232550506 0.666083758 0.514251141
> set.seed(1234)
> 选择种子
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
通过手动设定种子,可以重现结果,有助于创建在未来取用的,可与他人分享的示例。
- 生成多元正态数据
在模拟研究和蒙特卡洛方法中,经常需要获取来自给定均值向量和协方差阵的多元正态分布的数据。MASS包中的mvrnorm( )函数让这个问题变得很容易。其调用格式为:
mvrnorm(n, mean, sigma)
其中n是想要的样本大小,mean为均值向量,而signma是方差--协方差矩阵(或相关矩阵)。在代码清单5-3中,将从一个参数如下所示的三元正态分布中抽取500个观测。

代码清单5-3 生成服从多元正态分布的数据
> library(MASS)
> options(digits=3)
> #设定全局小数的有效位数为3
> set.seed(1234)
> #设定随机种子
> mean <- c(230.7, 146.7, 3.6)
> #均值向量
> sigma <- matrix(c(15360.8, 6721.2, -47.1, 6721.2, 4700.9, -16.5, -47.1, -16.5, 0.3), nrow=3, ncol=3)
> 协方差矩阵
> mydata <- mvrnorm(500, mean, sigma)
> #500个随机数
> mydata <- as.data.frame(mydata)
> #矩阵转化为数据框
> names(mydata) <- c("y", "x1", "x2")
> #变量命名
> dim(mydata)
> #查看mydata维数,500个观测,3个变量
[1] 500 3
> head(mydata, n=10)
> #列出mydata前10个变量
y x1 x2
1 98.8 41.3 3.43
2 244.5 205.2 3.80
3 375.7 186.7 2.51
4 -59.2 11.2 4.71
5 313.0 111.0 3.45
6 288.8 185.1 2.72
7 134.8 165.0 4.39
8 171.7 97.4 3.64
9 167.2 101.0 3.50
10 121.1 94.5 4.10
代码清单5-3中设定了一个随机数种子,结果可以重现。指定了均值向量和方差-协方差矩阵,并生成500个伪随机观测。
R中的概率函数允许生成模拟数据,这些数据是从服从已知特征的概率分布中抽样而得的。
5.2.4 字符处理函数
数学和统计函数是用来处理数值型数据的,而字符处理函数可以从文本数据中抽取信息,或者打印输出和生成报告重设文本的格式。
一些最有用的字符处理函数:
-
nchar(x)
计算x中的字符数量 -
substr(x, start, stop)
提取或替换一个i额字符串向量中的子串 -
grep(patten, x, ignore,.case=FALSE, fixed=FALSE)
在x中搜索某种模式,fixed=FALSE,则pattern为一个正则表达式。若fixed=TRUE,则pattern为一个文本字符串,返回值为匹配的下标。grep("A", c("b", "A", "c"), fixed=TRUE)返回值为2 -
sub(patten, replacement, x, ignore.case=FALSE, fixed=FALSE)
在x中搜索pattern,并以文本replacement将其替换。若fixed=FALSE,则pattern为正则表达式。若fixed=TRUE,则pattern为文本字符串。sub("\s", ".", "Hello There")返回值为Hello.There。 -
strsplit(x, split, fixed=FALSE)
在split处分割字符向量x中的元素。若fixed=FALSE,则pattern为一个正则表达式。若fixed=TRUE,则pattern为一个文本字符串
y <- strplit("abc", "")将返回一个含有1个成分,3个元素的列表,内容为"a" "b" "c" -
paste(..., sep=" ")
连接字符串,分隔符为sep
paste("x", 1:3, sep="")返回值为c("x1", "x2", "x3")
paste("x", 1:3, sep="M")返回值为c("xM1", "xM2", "xM3")
paste("Today is", date()) [1] "Today is Wed Feb 22 19:58:31 2017" - toupper(x)
大写转换 - tolower(x)
小写转换
fixed=FALSE默认。
5.2.5 其他实用函数
-
length(x)
对象的长度
x <- c(2, 3, 6, 9) length(x) 返回值为4 -
seq(from, to, by)
生成一个序列
indices <- seq(1, 10, 2) 返回 c(1, 3, 5, 7, 9) -
rep(x, n)
将x重复n次 -
cut(x, n)
将连续型变量x分割为有着n个水平的因子,使用选项ordered_result = TRUE以创建一个有序型因子 -
pretty(x, n)
创建美观的分割点。通过选取n+1个等间距的取整值,将一个连续型变量分割为n个区间。 -
cat(..., file = "myfile", append=FALSE)
连接...中的对象,并将其输出到屏幕上或文件中
5.2.6 将函数应用于矩阵和数据框
R函数的诸多有趣特性之一,就是它们可以应用到一系列的数据对象上,包括标量、向量、矩阵、数组和数据框。下面提供一个示例:
代码清单5-4 将函数应用于数据对象
> a <- 5
> sqrt(a) #开方
[1] 2.236068
> b <- c(1.243, 5.654, 2.99)
> round(b) #四舍五入为指定位数
[1] 1 6 3
> round(b, digits=2)
[1] 1.24 5.65 2.99
> c <- matrix(runif(12), nrow=3) #生成矩阵
> c
[,1] [,2] [,3] [,4]
[1,] 0.3606903 0.6280706 0.2775527 0.07298383
[2,] 0.3026980 0.9936740 0.2052848 0.88960263
[3,] 0.4595408 0.8816083 0.6905827 0.02618769
> log(c) #自然对数
[,1] [,2] [,3] [,4]
[1,] -1.0197355 -0.46510269 -1.2817443 -2.6175173
[2,] -1.1950197 -0.00634606 -1.5833572 -0.1169804
[3,] -0.7775277 -0.12600744 -0.3702196 -3.6424658
> mean(c) #求平均
[1] 0.482373
上例中,mean( )求得的是整个矩阵全部元素平均值。如果希望得到各行各列均值,使用apply( )函数。使用格式:
apply(x, MARGIN, FUN, ...)
其中,x为数据对象,MARGIN为下标,FUN是指定的函数。MARGIN=1表示行,MARGIN=2表示列。
代码清单5-5 将一个函数应用到矩阵的所有行(列)
> mydata <- matrix(rnorm(30), nrow=6)
> #生成数据
> mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 1.9874573 1.5496173 1.3044198 0.7512133 -0.4750425
[2,] -0.4001353 -0.3707196 -0.9728988 1.1036000 -0.2219802
[3,] 0.2981038 -1.2892632 0.2413237 1.5964866 -2.5008578
[4,] -0.2973963 0.4338252 -0.6773301 -0.7330371 0.1311788
[5,] -0.9786852 -0.8694846 -0.6010975 0.1946987 -1.0905071
[6,] 0.4546217 -2.0744591 -0.2488879 0.4865725 1.8413957
> apply(mydata, 1, mean)
> #每行求平均
[1] 1.02353304 -0.17242677 -0.33084139 -0.22855191 -0.66901514 0.09184859
> apply(mydata, 2, mean)
> #每列求平均
[1] 0.1773277 -0.4367473 -0.1590785 0.5665890 -0.3859689
> apply(mydata, 2, mean, trim=0.2)
> #每列结尾平均,删去两端20%
[1] 0.01379848 -0.52391056 -0.32149794 0.63402112 -0.41408776
5.3 数据处理难题的一套解决方案
5.1节中提出的问题,在此给出解决方案。
代码清单5-6 示例的一种解决方案
> #设定全局数字有效位数
> Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
+ "David Jones", "Janice Markhammer", "Cheryl Cushing",
+ "Reuven Ytzrhak", "Greg Knox", "Joel England",
+ "Mary Rayburn")
> Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
> Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
> English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
> #输入数据
> roster <- data.frame(Student, Math, Science, English, stringsAsFactors=FALSE)
> #生成数据框,最后FALSE使R不要将字符串识别位属性数据。
> z <- scale(roster[, 2:4])
> #对roster数据框中2至4列中心化(减均值)而后标准化(除以标准差)
> z
Math Science English
[1,] 0.013 1.078 0.587
[2,] 1.143 1.591 0.037
[3,] -1.026 -0.847 -0.697
[4,] -1.649 -0.590 -1.247
[5,] -0.068 -1.489 -0.330
[6,] 0.128 -0.205 1.137
[7,] -1.049 -0.847 -1.247
[8,] 1.432 1.078 1.504
[9,] 0.832 0.308 0.954
[10,] 0.243 -0.077 -0.697
attr(,"scaled:center")
Math Science English
501 87 22
attr(,"scaled:scale")
Math Science English
86.7 7.8 5.5
> score <- apply(z, 1, mean)
> #计算各行均值
> roster <- cbind(roster, score)
> #合并为一个数据框
> roster
Student Math Science English score
1 John Davis 502 95 25 0.56
2 Angela Williams 600 99 22 0.92
3 Bullwinkle Moose 412 80 18 -0.86
4 David Jones 358 82 15 -1.16
5 Janice Markhammer 495 75 20 -0.63
6 Cheryl Cushing 512 85 28 0.35
7 Reuven Ytzrhak 410 80 15 -1.05
8 Greg Knox 625 95 30 1.34
9 Joel England 573 89 27 0.70
10 Mary Rayburn 522 86 18 -0.18
> y <- quantile(roster$score, c(.8, .6, .4, .2))
> #求score四个分为点
> y
80% 60% 40% 20%
0.74 0.44 -0.36 -0.89
> roster$grade[score >= y[1]] <- "A"
> #使用逻辑运算符将百分位排名重编码为类别型成绩变量
> roster$grade[score < y[1] & score >= y[2]] <- "B"
> roster$grade[score < y[2] & score >= y[3]] <- "C"
> roster$grade[score < y[3] & score >= y[4]] <- "D"
> roster$grade[score < y[4]] <- "F"
> roster
Student Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhammer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
> name <- strsplit((roster$Student), " ")
> #以空格为界,把名字分开
> name
[[1]]
[1] "John" "Davis"
[[2]]
[1] "Angela" "Williams"
[[3]]
[1] "Bullwinkle" "Moose"
[[4]]
[1] "David" "Jones"
[[5]]
[1] "Janice" "Markhammer"
[[6]]
[1] "Cheryl" "Cushing"
[[7]]
[1] "Reuven" "Ytzrhak"
[[8]]
[1] "Greg" "Knox"
[[9]]
[1] "Joel" "England"
[[10]]
[1] "Mary" "Rayburn"
> Firstname <- sapply(name, "[", 1)
> #提取name中的第一个元素,“[”表示提取对象一部分
> Lastname <- sapply(name, "[", 2)
> roster <- cbind(Firstname, Lastname, roster[,-1])
> #合并名、姓。删除原来的名字,逗号选择所有行,-1删除第一列
> roster
Firstname Lastname Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhammer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
> roster[order(Lastname, Firstname), ]
> 按照名字进行排序
Firstname Lastname Math Science English score grade
6 Cheryl Cushing 512 85 28 0.35 C
1 John Davis 502 95 25 0.56 B
9 Joel England 573 89 27 0.70 B
4 David Jones 358 82 15 -1.16 F
8 Greg Knox 625 95 30 1.34 A
5 Janice Markhammer 495 75 20 -0.63 D
3 Bullwinkle Moose 412 80 18 -0.86 D
10 Mary Rayburn 522 86 18 -0.18 C
2 Angela Williams 600 99 22 0.92 A
7 Reuven Ytzrhak 410 80 15 -1.05 F
5.4 控制流
控制流可使R程序按照特定顺序实行语句。
R拥有一般现代编程语言中都有的标准控制结构。首先是条件执行的结构,接下来是用于循环执行的结构。介绍一些概念:
- 语句(statement)是一条单独的R语句或一组复合语句;
- 条件(cond)是一条最终被解析为真(TRUE)或假(FALSE)的表达式;
- 表达式(expe)是一条数值或字符串的求值语句;
- 序列(seq)是一个数值或字符串序列、
5.4.1 重复和循环
循环结构重复地执行一个或一系列语句,直到某个条件不为真为止。循环结构包括for和while结构。
- for结构
for循环重复地执行一个语句,直到某个变量的值不再包含在序列seq中为止。语法为:
for (var in seq) statement
在下例中:
for (i in 1:10) print("Hello")
单词Hello被输出10次。
- while结构
while循环重复地执行一个语句,直到条件不为真为止。语法为:
while (cond) statement
作为第二个例子,代码:
i <- 10
while (i >0) {print("Hello") ; i <- i - 1}
单词Hello输出10次。
while较其他循环结构更危险,可能会不停循环。在处理大数据集中的行和列时,R中的循环可能比较低效费时。只要可能最好联用R中的内建存储/字符串处理函数和apply族函数。
5.4.2 条件执行
条件执行结构中,一条或一组语句仅在满足一个指定条件时执行。条件执行结构包括if-else、ifelse和switch。
- if-else结构
控制结构if-else在某个给定条件为真时执行语句。也可以同时在条件为假时执行另外的语句。语法为:
if (cond) statement
if (cond) statement1 else statement2
示例如下:
if (is.character(grade)) grade <- as.factor(grade)
if (!is.factor(grade)) grade <- as.factor(grade) else print("Grade already is a factro")
- ifelse结构
ifelse结构是if-else结构比较紧凑的向量化版本,其语法为:
ifelse(cond, statement1, statement2)
若cond为TRUE,则执行第一个语句;若cond为FALSE,则执行第二个语句。示例如下:
ifelse (score > 0.5, print("Passed"), print("Failed"))
outcome <- ifelse (score > 0.5, "Passed", "Failed")
在程序的行为是二元时,或者希望结构的输入和输出均为向量室,使用ifelse。
- switch结构
switch根据一个表达式的值选择语句执行。语法为:
switch(expr, ...)
其中的...表示与expr的各种可能输出值绑定的语句。通过观察代码清单5-7中的代码,理解switch工作原理。
代码清单5-7 一个switch示例
> feelings <- c("sad", "afraid")
> for (i in feelings)
+ print(
+ switch(i,
+ happy = "I am glad you are happy",
+ afraid = "There is nothing to fear",
+ sad = "Cheer up"
+ )
+ )
[1] "Cheer up"
[1] "There is nothing to fear"
5.5 用户自编函数
R允许用户自行添加函数。一个函数的结构看起来大致如此:
myfunction <- function(arg1, arg2, ...){statements return(object) }
函数中的对象只在函数内部使用。返回对象的数据类型是任意的,从标量到列表皆可。
假设需要一个函数,计算数据对象的集中趋势和散布情况。此函数应当 可以选择性地给出参数统计量(均值和标准差)和非参数统计量(中位数和绝对中位差)。结果以一个含名称列表的形式给出。
代码清单5-8 mystats( ):一个由用户编写的描述性统计量计算函数
> mystats <- function(x, parametric=TRUE, print=FALSE) {
+ if (parametric) {
+ center <- mean(x); spread <- sd(x)
+ } else {
+ center <- median(x); spread <- mad(x)
+ }
+ if (print & ! parametric) {
+ cat("Mean=", center, "\n", "SD=", spread, "\n")
+ } else if (print & !parametric) {
+ cat("Median=", center, "\n", "MAD=", spread, "\n")
+ }
+ result <- list(center=center, spread=spread)
+ return(result)
+ }
> set.seed(1234)
> x <- rnorm(500)
> y <- mystats(x)
> y <- mystats(x, parametric=FALSE, print=TRUE)
Mean= -0.02070734
SD= 1.000984
下面是一个使用了switch结构的用户自编函数,此函数可以让用户选择输出当天日期的格式。在函数声明中为参数指定的值将作为默认值。在函数mydate( )中,如果未指定type,则long将为默认的日期格式:
> mydate <- function(type="long") {
+ switch(type,
+ long = format(Sys.time(), "%A %B %d %Y"),
+ short = format(Sys.time(), "%m-%d-%y"),
+ cat(type, "is not a recognized type \n")
+ )
+ }
> mydate("long")
[1] "星期四 二月 23 2017"
> mydate("short")
[1] "02-23-17"
> mydate("medium")
medium is not a recognized type
函数cat( )仅会在输入的日期格式不匹配“long”或“short”时执行。使用一个表达式来捕获错误输入的参数值通常是个好主意。
有若干函数可以用来为函数添加错误捕获和纠正功能。函数warning( )可以生成错误提示信息,message( )生成诊断信息,stop( )停止当前表达式的执行并提示错误。
5.6 整合与重构
R中提供了许多用来整合(aggregate)和重塑(reshape)数据的强大方法。整合数据往往将多组观测替换为根据这些观测计算的描述性统计变量。重塑数据时会通过修改数据的结构(行和列)来决定数据的组织方式。
接下来的例子使用R基本安装中的数据框mtcars。
5.6.1 转置
转置(反转行和列),使用函数t( )完成。
代码清单5-9 数据集的转置
> cars <- mtcars[1:5, 1:4]
> #提取mtcars数据框前5行,4列
> cars
mpg cyl disp hp
Mazda RX4 21.0 6 160 110
Mazda RX4 Wag 21.0 6 160 110
Datsun 710 22.8 4 108 93
Hornet 4 Drive 21.4 6 258 110
Hornet Sportabout 18.7 8 360 175
> t(cars)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 22.8 21.4 18.7
cyl 6 6 4.0 6.0 8.0
disp 160 160 108.0 258.0 360.0
hp 110 110 93.0 110.0 175.0
5.6.2 整合数据
在R中使用一个或多个by变量(一个变量名组成的列表)和一个预先定义好的函数来折叠(collapse)数据是比较容易的。调用格式:
aggregate (x, by, FUN)
x是待折叠的数据对象,by是变量名组成的列表,这些标量将被去掉已形成新的观测,FUN是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。
代码清单5-10 整合数据
> options(digits=3)
> #全局有效数字限定3位
> attach(mtcars)
> #绑定数据框
> aggdata <- aggregate(mtcars, by=list(cyl, gear), FUN=mean, na.rm=TRUE)
> #统计折叠cyl和gear。对其他变量求均值
> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
使用aggregate( )函数时,by中的变量必须在一个列表中(即使只有一个变量)。可以在列表中为各组声明自定义名称,例如by=list(Group.cyl=cyl)
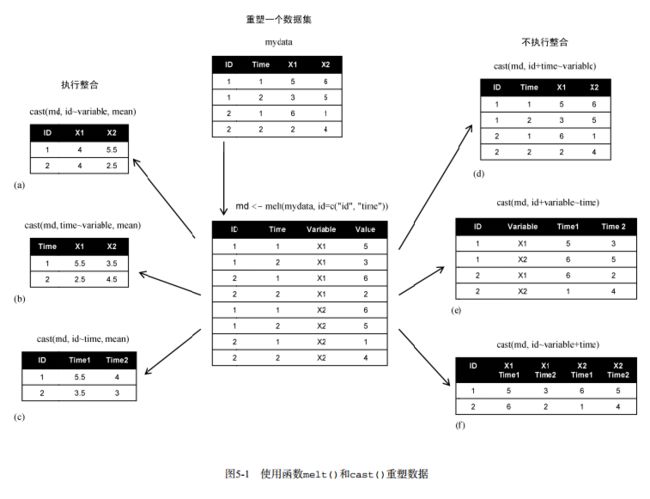
5.6.3 reshape包
reshape包是一套重构和整合数据集的万能工具。第一次使用需安装(install.packages("reshape"))。
首先先将数据“融合”(melt),使每行是一个唯一的标识符-变量组合。然后将数据“重铸”(cast)为想要的任何形状。
- 融合
数据集的融合是将他们重构为这样一种格式:每个测量变量独占一行,行中带有唯一确定这一个测量所需的标识符标量。
> mydata <- read.table(header=TRUE, sep=" ", text="
+ ID Time X1 X2
+ 1 1 5 6
+ 1 2 3 5
+ 2 1 6 1
+ 2 2 2 4
+ ")
> mydata
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> # melt data
> md <- melt(mydata, id=c("ID", "Time"))
> melt
function (data, ...)
UseMethod("melt", data)
> md
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
仔细观察区别。
- 重铸
cast( )函数读取已融合的数据,并使用提供的公式和一个(可选的)用于整合数据的函数将其重塑。调用格式为:
newdata <- cast(md, formula, FUN)
其中md为已融合数据,formula描述了最后的结果形式,FUN是数据整合函数。接受的公式形如:
rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
rowvar1定义了要划掉的变量集合,以确定各行内容,colvar1定义了要划掉的、确定各列内容的变量集合。
5.7 小结
本章总结了数十种用于处理数据的数学、统计和概率函数。函数可以应用到范围广泛的数据对象上,其中包括向量、矩阵和数据框。还介绍了控制流结构的使用方法:用循环重复执行某些语句,或用分支在满足某些特定条件时执行另外的语句。
——2017.2.23
——工作室510