最近用tensorflow复现了AlexNet,VGGNet,GoogleIncptionNet(V3),ResNet等经典的深度神经网络,整个过程下来还是很有收获的,也算是对神经网络这部分有了更深刻的理解。其实这些网络的整体流程和LeNet无外乎还是相似的,但是在复现这些经典网络的过程中,感受最明显的还是网络背后的设计精妙之处。下面并不会对各网络的细节及每层的参数设置来做具体描述,只讲讲自己对上述几个经典网络设计的一点粗浅理解:
一、AlexNet
2012年,Hinton(DL届的爷爷辈人物)的学生Alex Krizhevsky提出了深度卷积神经网络AlexNet,并以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至16.4%,相比第二名的成绩26.2%错误率有了巨大的提升。AlexNet可以说是神经网络在低谷期的第一次发声,确立了深度学习在计算机视觉的统治地位!
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要用到的新技术有:
成功使用了ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。
AlexNet全部使用最大池化Maxpool,避免平均池化Avgpool的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。(后面VGGNet的作者提出LRN层的作用并不大,所以现在的网络一般都不用LRN层)
使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。(看看NVIDIA的股票涨势就知道GPU在深度学习届有多火!!!)
二、VGGNet
VGGNet是牛津大学和google一起研发的深度卷积神经网络。相比之前state-of-the-art的网络结构,错误率大幅下降,取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。直到目前,VGGNet依然经常被用来提取图像特征。
VGGNet可以说是探索了卷积神经网络的深度与其性能之间的关系,将日后的这些网络都推向了更深的层次。
VGGNet包括这几个网络都遵循着一个相同的设计思路:越靠后的卷积核数量越多。
VGGNet的卷积层设计中一个特别好的trick:与其构建大的卷积核,不如换成几个很小的卷积核逐层提取,不仅参数可以减小,减轻过拟合,还增加了多层的非线性扩展能力。如3个3x3的卷积层串联的效果相当于1个7x7的卷积层,除此之外,3个串联的3x3卷积层,拥有比1个7x7的卷积层更少的参数量,只有后者的3x3x3/7x7=55%(蛋疼的不支持数学公式,凑合着看吧......)。最重要的是,3个3x3的卷积层拥有比一个7x7卷积层更多的非线性变换,使得CNN对特征的学习能力更强!
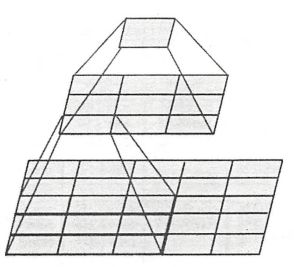
VGGNet的模型参数虽然比AlexNet多,但是反而需要较少的迭代次数就可以收敛,主要原因是更深的网络更小的卷积核带来的隐式的正则化效果。
三、GoogleInceptionNet
GoogleInceptionNet首次出现在ILSVRC 2014的比赛中(和VGGNet同年),就以较大的优势取得了第一名。
InceptionNet一个极深的卷积神经网络,拥有非常精妙的设计和构造,整个网络的结构和分支非常复杂,其中有许多设计CNN的思想和trick值得借鉴:
论文中提到了其网络模型的稀疏结构主要基于Hebbian原理:“神经反射活动的持续与反复会导致神经元连接稳定性的持久提升,当两个神经元细胞A和B距离很近时,并且A参与了对B重复/持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞。”
受Hebbian原理启发,如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关的节点聚类,并将聚类出来的每一小簇连接到一起。在普通的数据集中,这可能需要对神经元节点进行聚类,但是在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一个空间位置但是在不同通道的卷积核的输出结果相关性极高。因此,一个1x1的卷积就可以很自然的把这些相关性很高的在同一个空间位置但是不同通道的特征连接在一起!稍微大一点的卷积核所连接的节点相关性也很高,因此可以适当的使用增加特征的多样性!
InceptionNet还提出了另一方面的改造:引入了Factorization into small convolutions的思想,将一个较大的二维卷积核拆成两个较小的一维卷积,一方面节约了参数,加速运算并减轻过拟合,同时增加了一层非线性扩展模型表达能力。论文额中之处,这种非对称的卷积结构拆分,其结果比对称的拆为几个相同的小卷积核效果更明显!比如可以将
5x5的卷积核设计为两层1x5和5x1的卷积核,提取特征的效果好于两个3x3的卷积核;可以通过设计Inception Module用多个分支提取不同抽象程度的高阶特征来丰富网络的表达能力。如Inception v3的Inception Module中分支1一般是
1x1卷积(组合简单的特征抽象),分支2和3一般都是1x1卷积再接分解后的1xn和nx1卷积(组合比较复杂的特征),分支4一般是具有最大池化或平均池化,一共四种不同程度的特征抽象和变换来有选择的保留不同层次的高阶特征;从卷积网络的输入到输出,应该让图片尺寸逐渐减小,输出通道数逐渐增加,即让空间结构简化,将空间信息转化为高阶抽象的特征信息。每一个通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。但是要注意增加输出通道数带来的副作用就是计算量增大和过拟合!
在Inception V2的论文中提出了著名的Batch Normalization方法。BN是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提升。(具体关于Batch Normaliation的详细知识在这篇文章里)
四、ResNet
ResNet由微软研究院的何凯明(清华学霸,两次CVPR最佳论文)提出,通过使用Residual Unit成功训练152层深的神经网络,在ILSVRC 2015比赛中获得了冠军,取得3.57%的top-5错误率。
ResNet灵感解决了不断增加神经网络的深度时,会出现Degradation的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光是在测试集上误差增大,训练集本身误差也会增大!假设有一个比较浅的网络达到了饱和的准确率,那么在后面再加上几个y=x的全等映射层,起码误差不会增加。使用全等映射直接经前一层输出传到后面的思想,就是ResNet的核心意义。
假设某段神经网络的输入为x,期望输出为H(x),如果我们只届把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x)=H(x)-x。ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),指示输出和输入的差别H(x)-x,即残差。
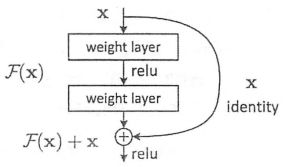
传统的卷积层或全连接层在传递信息时,或多或少会存在信息丢失/损耗等问题。ResNet在某种程度上解决了这个问题,通过直接将输入绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。