娄骥(北京师范大学心理学院)卢莎(北京辅仁淑凡软件科技有限公司)
摘要:传统的测评方式由于量表的整体性、测评时间过长、测评理论的局限性等因素会影响测评的精确性和效率,已在大规模心理测评中逐步淘汰。研发精确、高效的测评工具已成为大规模心理测评的当务之急,通过以维度为单位组成测评问卷、应用IRT理论筛选高质量的测评题目、采用CAT的测评方法等途径对测评工具进行更新,即可在很大程度上提高测评效率。
关键词:大规模心理测评;传统测评的局限;高质量题目;测评方法
一、大规模心理测评适应现代测评的发展需求
随着心理学在国内的发展,心理学的两大分支:心理咨询和心理测评在国内得到了比较广泛的发展和应用。心理测评的应用主要体现在大规模心理测评和辅助心理咨询的过程中。大规模心理测评是由数千人、万人进行的心理测评,主要应用在心理健康管理和人才管理两个领域,例如,心理健康管理领域的学校心理普查、企业和医院的心理体检等方面;人才管理领域的人才选拨、人才晋升、特定人群的素质测评(如:学生的学业综合测评、领导干部素质测评)等方面。
1.全方位、多特质的心理测评
根据麦克利兰的素质冰山模型(1973),个体的心理素质包括可观察的 “冰山以上部分”,也就是外显的知识和技能,以及深藏内隐的“冰山以下部分”,也就是个体的动机、个性特点、自我概念和社会角色等。冰山以上的部分可通过技能测评等方式进行了解,而冰山以下的部分则需要借助心理测评工具才能够在短时间内被人了解,而此部分的内容远远要比冰上以上外显行为包含的内容更广。在现实的大规模心理测评时,就往往涉及到关于个体整体心理状态的全面测评,包含范围:心理健康管理一般包括基本心理健康状况筛查、个性态度、社会归属性、职业活力、压力应对方式等多个方面;人才管理一般包括个体基本的心理健康状况、岗位胜任能力、职业价值观、个性态度、职业兴趣等方面。而这些方面又可细化为更加具体的维度,例如,每个人从事某个职业的动机是不同的:追求成就、社会地位、管理支配、经济报酬、智力挖掘、人际关系、稳定等。可见,在大规模心理测评中往往要对人的很多特质进行全方位的综合测评。
2.心理测评的精确性
对上千人、万人进行大规模心理测评时,施测者没有二次机会了解受测者,因此需要测评能够更加精确的估计出受测者的特质,同时要能够很好的识别无效作答、随意作答、虚假作答等情况的受测者,以保证不会影响整体的测评结果。另外,在整个施测过程中的误差要减小,受测者的疲劳状态、测评程序的不稳定性等情况都会造成一定的测量误差,此时我们就很难评估受测者之间的个体差异。可见,大规模心理测评的精确性是至关重要的问题,需要研究者在开发高质量的施测题目、筛选有针对性的维度、严格控制整体的施测流程等方面加以考虑和控制。
面对大规模的施测样本,需要降低测评系统题目的曝光率,也就是说呈现给每个受测者的题目是不同的,一方面避免了受测者传播题目的作弊行为,另一方面保护测评系统的可持续使用。
3.心理测评的施测过程方便快捷
大规模心理测评中成千上万的受测者往往来自全国各地,有时很难集中施测,因此借助计算机互联网的方式进行施测是大规模心理测评的有利条件,不会受到地域、施测时间等方面的限制。
另外,针对儿童的测评课借助计算机的方式实现文字、语音、图画、录像等多种方式的结合,生动趣味性的测评方式更能吸引儿童的注意力;并且,统一的说明语、演示流程、施测流程等方面能够很好的消除主试对儿童测评结果的影响,最大化的减小测评误差,提高测评的精确性。
二、大规模心理测评的现状
目前关于大规模心理测评的需求有很多,但是其理论基础、实现方式等方面有诸多的局限性阻碍了大规模测评的发展和应用。主要体现在以下几个方面:
1.心理测评的效率低、资源浪费
在进行大规模心理测评时往往要对受测者施测多套经典量表,以全面的评估个体的心理发展状况。但此种情况存在诸多的局限:
在使用多套量表施测的情况下,受测者必须完成每个量表的所有题目之后才可对结果进行一一比较和解释,题目的曝光率很高,而且不同量表的评价标准不一,量表之间不能比较;
多套量表施测则意味着题量大、作答时间长,受测者往往会因此出现不良情绪,影响作答效率。宽窄网的研究人员曾对三万人的施测过程进行研究,结果发现,大约在测评进行20分钟时,15%的受测者会出现疲劳、烦躁等不良情绪,测评进行30分钟时,24%的受测者会出现不良情绪,从而出现随意作答、不作答等情况,造成测评的效率低。
另外,多套量表施测有时会有部分维度重复,甚至是不需要施测的维度,就会造成测评资源的重复和浪费,而且还会影响后期的数据录入和清理,又会有大量的时间、人工成本的浪费。
2.经典测量理论的局限
经典量表按照固定的顺序施测全部题目、综合所有的题目得出常模和评价,其理论基础为经典测量理论(CTT)。其假设包括:个体的心理特征具有稳定不变性,每个个体做测评时的误差都是随机的,测评分数就是个人的稳定的心理特征和测评误差之和,因此测量的目的在于减少测量误差,而能够较为准确的得出个体的心理特征值。在此理论的基础上建立了信度、效度、难度、区分度等指标用来评价测评量表的质量。
但CTT理论有其局限性:受测者的能力是通过单纯得分的累加得出的,而没有考虑题目难度、区分度等因素;测量误差不精确,因为每个人的测评误差大小不一,其测量的精确性有待提高;测量统计指标的制定依赖抽样的变动,抽样偏差、抽样样本大小等因素均会影响测评的指标;受测者的能力与难度指标含义不同,无法相互解释;量表以固定的题目和顺序呈现,计分方式等不统一,因此非同一份量表的受测者无法比较。CTT理论的种种局限性导致测评量表的精确性、测评效率很容易受到影响。
三、大规模心理测评的发展方向
1.以维度为单位重组测评工具
大规模心理测评要求全方位的评估受测者的心理特质,需要研发更具有针对性、精确性的测评工具。
打破测评以量表为单位的观念,编制以维度为单位的测评工具。以维度的方式进行组卷,需要对维度进行不同层次的划分。不同层次的维度之间保持独立性,相同层次的维度可保持一定的相关性,例如:社会支持和职业活力属于两个独立的层次,两者之间需要有很好的独立性;而抑郁和焦虑是心理健康方面的两个相同层次的维度,应具有较低程度的相关。每个不同层次的维度均是测量个体的单一心理特质,这样就可以根据受测者的特点和需求有针对性的筛选测评维度,不会导致出现多余的测评维度。
2.引进先进的测评理论和方法
CTT理论作为测量的经典理论,已经暴露出诸多的局限,需要我们引进新的测量理论来进行更加精确的测量。
(1)项目反应理论(IRT)
IRT是针对CTT理论的不足而发展起来的测量理论,目的在于以更加精确的方法检测题目的质量,并且以最小的测量误差编制量表。
IRT理论针对单个题目进行数据分析,而不是针对每位受测者,因此每个题目均需要有大量的数据做支撑;每个题目经过数据分析均会有对应的项目反应特征曲线,反映出此题目的区分度、难度、猜测系数等检测题目质量的指标,题目编制者即可根据这些指标来判断此题目的质量。例如,某题目应用IRT理论中的双参数模型计算得出的项目反应曲线如图1所示,此题目的区分度a为1.804,b为0.568,均在接受范围。
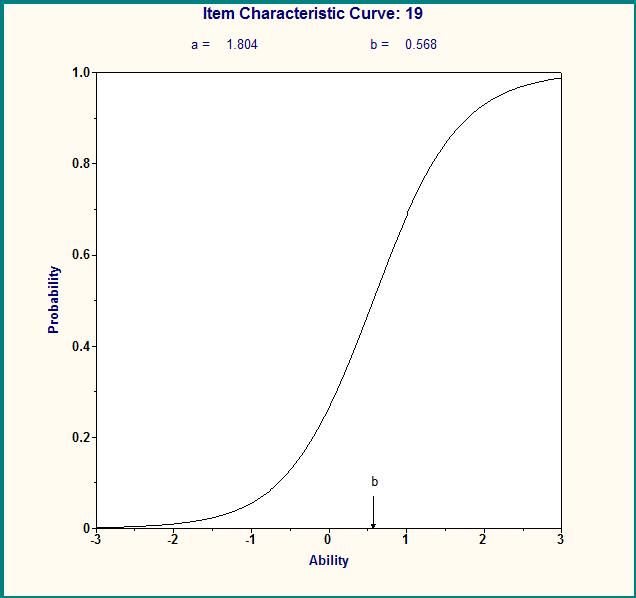
图1 某题目的项目特征曲线图
另外,IRT可做到既对每个题目单独进行分析,也会对整套问卷进行整体分析(测量信度、模型拟合度等)。并且,IRT理论对整套量表的评价分析要全面、准确的多,郭庆科等(2005)的研究发现其信度指标比CTT的信度指标更加准确合理。
(2)计算机自适应测评(CAT)
CAT测验是在IRT理论的基础上进行的计算机化施测过程,目的在于根据受测者的能力水平反复在测评题库中抽选与受测者能力接近的题目,最终对其进行精确的估计,真正实现对受测者的“量体裁衣”。
CAT测验建立在大量的测评题库、用IRT理论进行题目分析的基础之上。一方面,要求在每个维度上有大量题目组成的题库;另一方面,此题库中包含等级呈正态分布的题目,并且每个等级下的题目均要求具有等值性。满足此两个条件后就可以进行具体施测了,系统会根据受测者对某个题目的反应初步估计出其能力,然后挑选更难/容易的题目给受测者,反复循环此过程,达到测量误差最小或者固定题目数的时候自动停止测评,此时受测者的能力即为正确作答的最难题目所对应的能力。此种方式能够动态的逐步精确受测者的能力。例如:儿童智力成分测评系统的设计框架图示及施测过程如下:
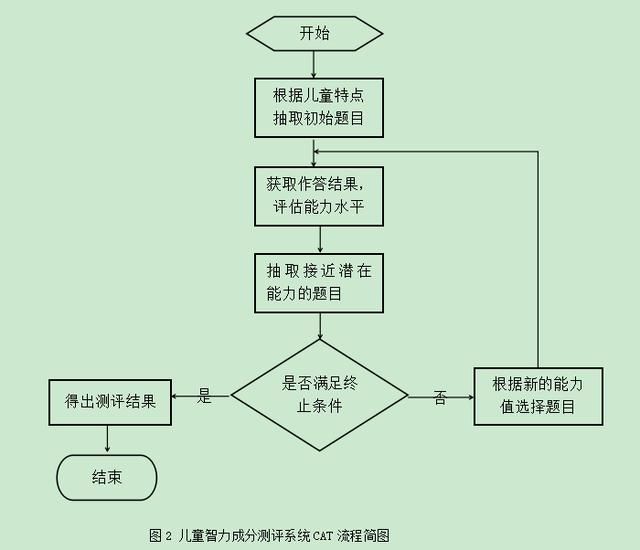
图2 儿童智力成分测评系统CAT流程简图
结合图2可知此系统的整体施测过程包含以下几步:第一步,儿童登陆测评系统,填写个人的基本信息,开始测评;第二步,系统会根据儿童的年龄、性别等信息,在大量的题库中抽取出初始题目,要求儿童作答;第三步,根据儿童对题目的作答情况,评估儿童的能力水平;第四步,根据上一题对儿童能力的评估情况抽选更接近儿童潜在能力水平的题目;第五步,重复三四步的过程,一直到达到终止条件,即可得出测评结果,结束测评。此时,儿童所能作答的最难题目即可反映出儿童的潜在能力水平。
IRT和CAT的应用可以达到以下目的:a.可以使题目质量更好,每个题目均经过详细的检测和分析,包含的信息量较多;b.根据受测者的能力自动在题库中选择相应等级的题目,用较少的(部分)题目即可精确的评定受测者的能力;c.不同的受测者测评时使用不同等级、不同信息量的题目,这样受测者只可看到自己作答的测评,无法猜测别人的测评题目,题库中题目的曝光率较低,可以有效的保护测评系统的重复使用性;d.CAT测验需使用计算机才能进行,比纸质测评更加节省人力和物力;另外,如果与网络相结合,即可克服了心理测评的地域局限性、时间性等因素,实施起来也会更加方便快捷。
3.提高题目质量
当测评题目编制后,需要对测评题目进行系统的分析,以确定此题目具有较高的质量。分析过程包括如下几步:
(1)通过专家判断、典型被试判断等方式确定在题目的内容上能够反映出所要测评的心理特质的内涵;分析题目的选项是否分布均匀,以确保不会出现许多受测者选择同一个选项或某一个选项不会有人选择的现象;另外,需要确定题目的表述清晰、语义单一无歧义等。
(2)题目载荷较高,具有单维性。以维度为单位进行心理测评,需要不同的维度之间具有较低的相关,确保此维度测量的单一特质,而不是其他相关较高的心理特质;在单维性的基础上挑选题目载荷较高,也就是对维度总分贡献率较高的题目。
(3)使用IRT理论对维度的每一个题目进行分析,挑选质量较高的题目。根据每个题的特点,例如:记分等级、选项特点、测验类型、测评误差等影响因素选择对应的分析模型(单参数模型、双参数模型、三参数模型、其他参数模型),以分析每个题目的信息量(难度、区分度、猜测度、测量误差)。
(4)量表的理论模型与数据的拟合度好,并且具有较高的信度。以心理特质的理论模型为基础编制量表、收集数据,因此需要检验量表数据与心理特质的理论模型是否拟合,具有较高拟合度时则说明理论模型、量表、数据具有高度的一致性。另外,良好的信度是保证量表可靠性的重要指标。
4.优化测评施测体系
当我们有高质量的施测题目、先进的施测方法时,需要借助现代化的计算机互联网帮助我们进行最优化的测评。
(1)计算机化测评。针对CAT测验的要求,所有题目采用计算机施测的方式,在每个维度上随机动态的抽取有针对性、相匹配的题目进行施测,用较少的题目进行测评,从而做到快速方便、精确的评估受测者的能力水平。
(2)网络化测评。此测评过程相比较于传统经典量表纸质或计算机施测更加方便快捷。首先,施测过程不会受受测者地域、时间等方面的限制,更加节省人力物力。其次,网上收集数据的过程不仅方便快捷,而且只有受测者做完测评就可以及时的收集到所需的数据,具有很高的实时性。最后,网上收集数据的过程可以借助计算机帮助我们记录更多的受测者信息,数据可批量导出,省去了后期进行数据录入的工作,并进行一定程度的数据清理工作,为数据分析节省了人力。
四、总结
针对大规模心理测评的特点和需求,传统经典量表已经难以满足,面对此考验,必须研究新的测评理论和应用先进的测评方法。
无论是何种测验,编制高质量的测验题目至关重要。运用IRT理论对题目进行质量分析和筛选相比较于CTT理论更加精确和详细。CAT测验的实施能够保证测验的精确性、高效性。另外,以维度为单位进行测评重组的方式能够一定程度的克服传统经典量表维度重复、题量大、评价标准不一导致不同量表没有可比性的问题。最后,结合计算机互联网的方式进行测评是现在大规模测评的有效支持。
参考文献
[1]郭庆科.情感能力测验的编制与项目反应理论的应用[D].北京师范大学,2003.
[2]朱宁宁,张厚粲.CTT与IRT方法对人格测验结果处理的比较研究[J].心理学探险.2003,23(3):48-51.
[3]谢敏,刘娟.提高大规模教育测评效果的途径之一:简化测评工具[J].心理技术与应用.2014,2:28-31.
[4]漆书青,戴海琦,丁树良.现代教育与心理测量学原理[M].高等教育出版社.
[6]郭庆科,陈英敏,孟庆茂.自陈量表式测验应用IRT的可行性[J].心理学报.2005,37(2):275-279.