在django项目中,我们在使用url时,会这样:
urlpatterns = [
url(r'^users', 'users.userview.get_users')
]
或者这样:
urlpatterns = [
url(r'^users', include(user_urls))
]
django url要做的就是基于这些正则表达式的匹配规则,找到与请求的url对应的view,func。
首先看下request请求进来后django路由url的入口,在django.core.handlers.base.get_response() 。
def get_response(self, request):
"Returns an HttpResponse object for the given HttpRequest"
…… ……
# 从settings中导入root_url名称,如'blog.urls'
urlconf = settings.ROOT_URLCONF
urlresolvers.set_urlconf(urlconf)
# 基于root_url构建一个RegexURLResolver实例
resolver = urlresolvers.RegexURLResolver('^/', urlconf)
…… ……
# 调用实例的resolve()方法匹配url对应的callback
resolver_match = resolver.resolve(request.path_info)
callback, callback_args, callback_kwargs = resolve_match
我们 大概可以看出url路由的基本流程和几个关键概念:
- settings.ROOT_UTLCONF是我们在settings中配置的根URL模块名称
- 匹配过程主要围绕RegexURLResolver类,通过正则表达式, url模块url_conf两个参数构造一个RegexURLResolver类实例,调用resolve()用来匹配请求的url,并返回匹配结果
下面会展开讲django url类结构,以及匹配的具体流程
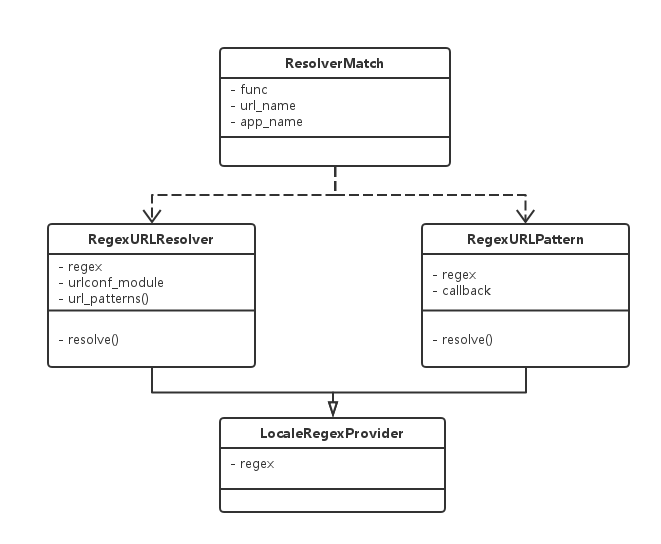
django URL 关键类结构
django URL的源码部分主要分为两个模块:
django.core.urlresolvers.py:包括django url的所有类结构
RegexURLPattern,RegexURLResolver,ResolverMatch以及url匹配逻辑。-
django.conf.urls.py:包括
url(),include(),pattern()三个主要方法,用于创建url相关类的实例。例如上面实例化一条url,相当于创建一个RegexURLPattern或RegexURLResolver对象
 django-url-class-example.png-17.5kB
django-url-class-example.png-17.5kB
RegexURLPattern:
包括属性regex(正则表达式), callback(正则表达式关联的view,func)
以及方法resolve(匹配传入的url对应的callback)
例如我们在url模块中实例化一个url,其实是调用django.conf.urls模块中的url()方法
url(r'^users', 'users.userview.get_users')
实例化一个url,其实是创建一个RegexURLPattern实例:
RegexURLPattern(r'^users', 'users.userview.get_users')
RegexURLResolver:
RegexURLResolver与RegexURLPattern的不同之处在于,RegexURLPattern可以理解为绑定regex和callback,而RegexURLResolver则是绑定regex与其他的RegexURLResolver或者RegexURLPattern。这是因为django支持url分层配置
如果我们这样实例化一个url:
url(r'^users', include(user_urls))
include方法代替了上面的'users.userview.get_users',表示正则表达式regex绑定到另一个urlconf,而不是view,func,这种情况下,相当于创建一个RegexURLResolver实例。
RegexURLResolver(r'^users', 'user_urls')
RegexURLResolver类包括属性regex(正则表达式), urlconf_module, url_patterns以及方法resolve
ResolverMatch:
由RegexURLPattern或RegexURLResolver返回匹配成功的结果, resolve()方法接收一个url,返回ResolverMatch对象
下面 结合实例,例如我们构建了一个django的blog,root_urlconf在app.urls:
urlpatterns = [
url(r'^users/', include('users.urls'))
url(r'^blogs/', include('blogs.urls'))
]
在users.urls:
urlpatterns = [
url(r'^([0-9]+)', userview.detail),
url(r'^login', userview.login)
]
相当于构建了以下的结构
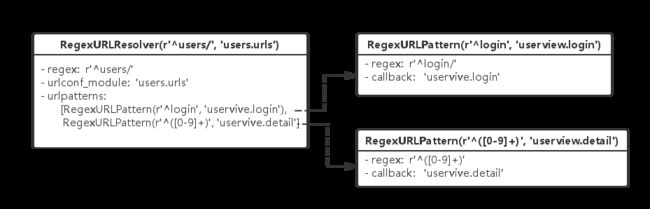
RegexURLResolver和RegexURLPattern中都有resolve方法,url的路由就是调用resolver和pattern的resolve方法,直到在pattern中匹配到相应的view,func
django URL 路由流程
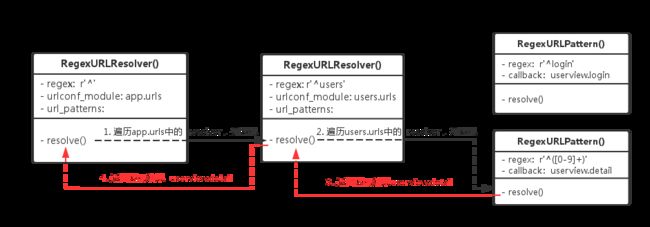
理解了上面的类结构以后,就能理解url的路由流程,其实就是一层层遍历这些结构化的url配置,直到 hit the target!
再来看看RegexURLResolver的resolve方法
def resolve(self, path):
path = force_text(path) # path may be a reverse_lazy object
tried = []
match = self.regex.search(path)
if match:
new_path = path[match.end():]
# 遍历下一层的所有url实例(可能是urlresolver或urlpattern)
for pattern in self.url_patterns:
try:
# 嵌套另一个urlresolver的resolve()或者urlpattern的resolve()
sub_match = pattern.resolve(new_path)
except Resolver404 as e:
sub_tried = e.args[0].get('tried')
if sub_tried is not None:
tried.extend([pattern] + t for t in sub_tried)
else:
tried.append([pattern])
else:
# 匹配成功
if sub_match:
sub_match_dict = dict(match.groupdict(), **self.default_kwargs)
sub_match_dict.update(sub_match.kwargs)
# 返回ResolverMatch实例
return ResolverMatch(
sub_match.func,
sub_match.args,
sub_match_dict,
sub_match.url_name,
self.app_name or sub_match.app_name,
[self.namespace] + sub_match.namespaces
)
tried.append([pattern])
raise Resolver404({'tried': tried, 'path': new_path})
raise Resolver404({'path': path})
整个匹配流程最关键的逻辑是嵌套其他urlresolver的resolve()或者urlpattern的resolve()。
RegexURLPattern中的resolve()逻辑比较简单,根据传入的url匹配,匹配成功就返回相应的callback。而RegexURLResolver也会匹配url,但会返回urlconf_module子模块的匹配结果,递归流程,直到找到叶子模块RegexURLPattern,然后将匹配结果层层返回。
结合上面给出的实例,我们需要找到'users/detail'对应的view,func
小结
之前在项目中遇到一个url路由问题,所以学习了一下django url源码,已经理解了主要的逻辑,但是发现一个小小问题。
RegexURLPattern的resolve()方法中匹配正则表达式和url时,使用re.search而不是re.match方法(search和match区别),search是从字符串的任意位置开始匹配,match必须从起始位置开始匹配。
如果users.urls中配置url改成:
url(r'([0-9]+)', userview.detail)
url(r'posts/([0-9]+)', userview.post_detail)
我想通过users/posts/1找到userview.post_detail,但其实会路由到userview.detail。如果在正则表达式中加入起始符号^就能避免这个问题。
但是问题是,为什么是用search而不是match,难道某些应用场景下允许忽略url前面某部分的路径,只匹配路径靠后的部分?users/extrapath/1同样能路由到userview.detail(应该是users/1)?
也许有人说,你傻啊,在前面加个起始符号^不就没问题了,可是既然需要加起始符号,为什么不直接用match呢?