姓名:何承勇
学号:16050510005
原文链接:https://monkeylearn.com/blog/beginners-guide-text-vectorization/
转载自:http://www.jianshu.com/p/f5c7144810c6,有删改
【嵌牛导读】:深度学习的火热已经深度的影响着文本向量化的发展,各种技术概念的提出与实践应用,也使得文本向量化由原始阶段走向了自主学习阶段。
【嵌牛鼻子】:深度学习
【嵌牛提问】:哪些技术概念为文本向量化的发展提供了技术支持?以及文本向量化又会朝着一个怎样的结果发展?
【嵌牛正文】:
在自然语言处理(NLP)诞生之初,需要将文本转换成机器可以理解的东西。换句话说,就是将文本转换为有意义的数字向量(或数组)。但是在深度学习的时代,我们只需用一个词袋就可以达到上述操作的效果。
1、词袋
这种方法虽然功能强大但是其背后的理念很简单。首先,我们需要定义一个固定长度向量,其中每个条目和我们预定义的词典中的单词相对应。向量的大小等于字典的大小。然后,我们只需计算出字典里的每一个单词在文本中出现的次数,再将这个数字放在相应的向量项中,这样所得到的向量就表示一个文本。
例如,如果我们的字典包含单词{MonkeyLearn,is,the,not,great},我们想要向量化文本“MonkeyLearn is great”,我们将会有以下向量:(1,1,0,0, 1)。
为增强它的表现能力,你可以使用一些更先进的技术,如去除省略词,lemmatizingword,使用n-gram或使用TF-IDF,来代替计数。
但是这种方法即使使用n-gram,它也不会真正捕捉到文本的含义或单词出现的语境。
2、深度学习正在改变文本向量化
目前,深度学习已经接管了机器学习,它做了很多改变文本向量化方式的尝试,并找到更好的方式来表示文本。
为解决上述问题首先需要找到一种向量化单词(vectorize words)的方式,word2vec的实现为解决这个问题起到了很大的作用,也因此在2013年之后变得非常受欢迎。通过使用大量数据,可以让神经网络学习一些具有理想属性词的向量表示。例如,使用word2vec,您可以执行“king” - “man”+“woman”,结果会得到一个与向量“Queen”非常相似的向量。这看起来有点魔幻,但是通过这个博客,你将会发现这是有可能发生的。这些向量的每一个维度可以编码出该单词的不同属性,这对于执行和NLP相关的许多任务是有用的。例如,据此你可以描述出该单词是动词还是名词,或者该单词是否为复数形式。
下一步是获取整个句子的向量化,这对于文本分类非常有用。尽管如此这个问题还是没有完全解决,但是在过去几年里,像Skip-Thought Vectors类似技术的实现,在该方面还是取得了很大的进展。
3、转移学习
在机器学习领域,转移学习是指机器将在一个任务中得到的学习观念运用到另一个任务中的能力。对于你面临的每个新问题,你需要从头开始执行所有向量化,这是通过词袋方法进行文本向量化的过程中存在一个问题。
这个问题在人与人的交往中并不存在,我们知道某些词的含义可能随着不同的背景而改变,但是我们不需要每次遇到这个词都重复学习一遍。
而深度学习则具有能够在多个不同问题中使用的文本向量化的能力,不必一次又一次地重复学习。
4、Skip-Thought向量
在这个方向上有很多人研究,其中多伦多大学开发的Skip-Thoughts向量是最好的研究成果之一。在这里你可以了解到Theano这种算法是如何实现的。
这个算法的想法如下:我们可以通过使用一个试图预测一个单词的周围单词的神经网络来获得一个向量表示,然后以同样的方式用一个神经网络预测句子周围的句子。为了得到更好地效果,他们需要在BookCorpus数据集中(这是一些作者编写的尚未发表的免费书)找到大量连续的文本数据。
在他们的论文中,他们表明这些句子向量可以用作非常强大的文本表示。我们将在文本分类问题中尝试这一点,看看它是否值得在现实世界中使用它。
5、一个小例子
接下来我们打算使用本文中给出的Scikit-Learn和skip-thoughts算法(使用Theano)将Skip-Thoughts和Bag of Words进行比较。我们使用航空情报数据集作为实验对象、用精度作为评估分类结果的指标。首先我们需要加载数据,并我们将数据集分为两个,然后进行训练和测试:

现在我们将定义一个向量化分类,稍后将在scikit-learn管道中使用:
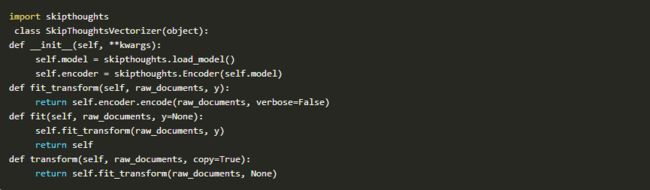
我们将定义三个scikit-learn管道。一个使用我们的(Skip Thoughts Vectorizer),另一个使用TF-IDF袋子的n-gram方法,另外一个使用两者的组合。在他们三个中,我们将使用一个非常简单的Logistic回归模型对我们的数据进行分类。
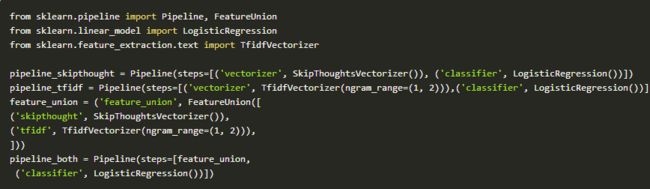
最后,我们将对这三条管道用不同大小的数据集对模型进行多次训练,并将它们分开进行测试。我们看看通过用大量的数据训练是否会影响算法的准确性。
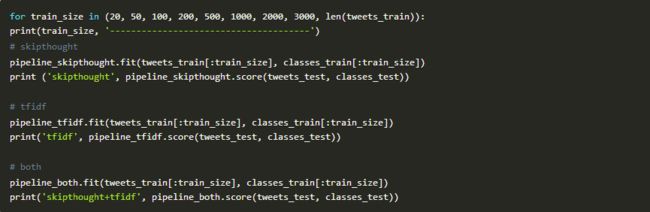
通过下面的图表,我们可以看到在模型运行中精度随着更多数据的加入而出现增长的现象。
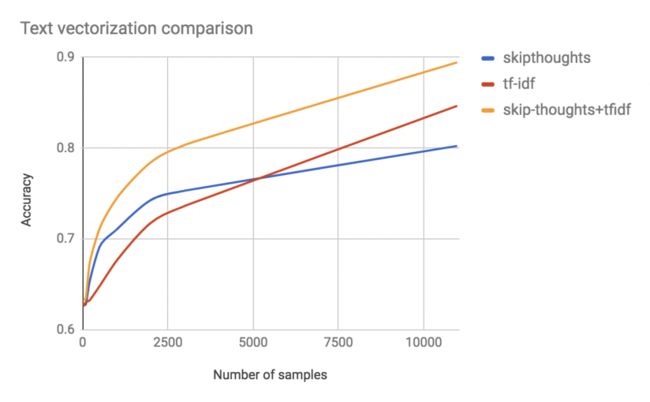
6、结果
当可以训练的数据不多(从0到5000个样本)时,由于Skip-Thoughts方法已经有了一些关于单词含义的信息,因此它能利用这些信息提供出比n-grams袋更好的分类结果。由此可以看出,在这项任务中我们利用转移学习,有效地提高了我们的结果。
从另一方面来说,n-grams袋的方法能够更好的“理解”这个数据集特定的信息,虽然有一些关于单词含义的信息可以用来做分类,但是相对的数据集本身,具体信息更有用。因此,当给出完整的训练数据集时,n-grams袋要比另一种方法做的好。
由此可以看到,Skip-Thoughts和n-grams袋在训练数据集信息上具有互补的作用。Skip-Thoughts方法是对于单词含义的一般认识,而n-grams袋中具有更多数据集的特定信息。将这两种方法结合起来,能够提高模型的准确性。
7、文本向量化的未来
转移学习是一个活跃的研究领域,很多大学和公司都在尝试在文本向量化中做出新的成果。最近的一些研究包括Salesforce CoVe,他们已经成功的将机器在翻译任务期间学习的信息构建成文本向量,用于完成之后的分类或问答等任务。
Facebook的InferSent使用类似的方法。但是,他们是运用一个神经网络来学习如何对斯坦福自然语言推理(SNLI)语料库进行分类,这样做的同时,他们也得到了很好的文本向量化的结果。
在不久的将来,我们可能真的会找到一种让机器“理解”人类语言的方法,这将颠覆我们的生活方式。但在那之前,我们还有很长的路要走。
原文作者:阿里云云栖社区