第八课:案例分析 - 泰坦尼克数据
本节课将重点分析泰坦尼克号沉船事故,我们将探索是什么因素决定了最后是否生还。
我们将前面课程所学过的知识点融会贯通,举一反三。
新增知识点:
缺失值处理:pandas中的fillna()方法数据透视表:pandas中的pivot_table函数
3、分析哪些因素会决定生还概率
上节课列出来的因素包括舱位/性别/年龄,和它们的组合情况,对生还概率的影响。
我们的步骤是这样的:
Step1 : 数值统计计算:分组运算 df.groupby( )
数据透视表 df.pivot_table( )
Step2 : 可视化图表:seaborn.FacetGrid( ).map( ) 绘图
Step3 :结论
舱位和性别是两个分类变量,而年龄是数值变量,对于数值变量,将会使用Pandas的函数,将这样一个连续性的变量离散化,从而把它变成一个分类变量,以便进一步分析。
3-1 舱位与生还概率
计算每个舱位的生还概率

用 Pclass进行分类,然后使用聚合函数mean 的方法,就得到不同舱位生还的概率。
通过这个统计可以得出,头等舱的生还概率最大,有63%,生还率随舱位的降低而递减。同学们纷纷得出结论:我们一定要学好Python努力赚钱坐头等舱啊!不要连小命都危险重重啊!
接下来我们看看今天学习的新知识点,用不同的方法得出同样结果,替代掉groupby:

参数values指定的是要计算的值,这里是生还情况 Survived。
index 指的是这张将要生成的表的索引结构,也表示使用 Pclass 舱位数据来进行分类 。
加上聚合函数 aggfunc,这里使用 numpy 中的平均值 mean,来按照舱位数据进行分类,求 Survived 这一列的平均值。
两种方法得到同样的结果。这是得到的数据,接下来要看的是,基于数据的基础,绘制可视化图形,便于观察分析。
绘制舱位和生还概率的条形图
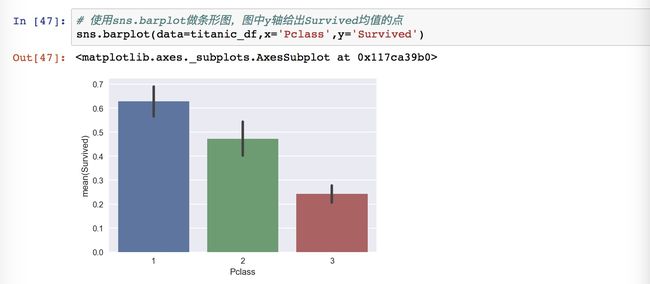
我们使用的是barplot函数,传递的数据是原始数据,然后设置横坐标和纵坐标。条形图的横坐标是1/2/3表示三个舱位,纵坐标是Survived这列的平均值,按照舱位进行分类之后的均值。
我们这里观察可以发现,seaborn非常适合做统计图表,因为能直接显示纵坐标的均值。图中有三根竖线,其实y轴给的是Survived均值的点估计,竖线表示95%置信区间的范围,也就是说,这个均值有可能95%的情况落在这个范围中。要是我们不需要这个置信区间,也可以设置掉,用ci=None。
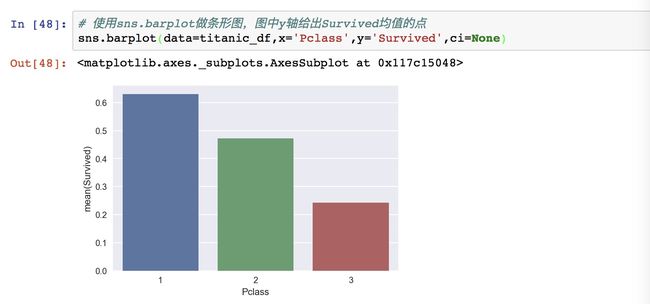
其实这里我不是很明白“点估计”和“置信区间(音译)”到底是什么,但是看起来好像没有其他知识点重要,忽略掉吧。
结论:头等舱的生还概率最大,其次是二等舱,三等舱的概率最小。
3-2 性别与生还概率
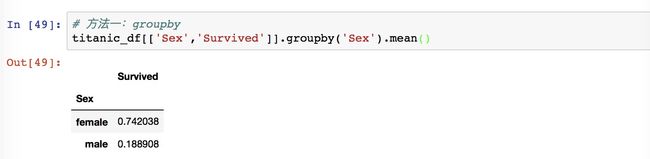
首先我们用groupby将数据按性别分组,然后求得生还概率。

values 代表要计算的列,是 Survived 这一列。按 Sex 性别进行分类,使得结果数据中的行索引是 Sex,然后使用 numpy 中的 mean 函数来求得均值。
两种方法求得同样的结果:男性生还率是18.9%,女性是74.2%。女性生还的概率远远高出男性的。
然后我们绘制图表来显示结果:
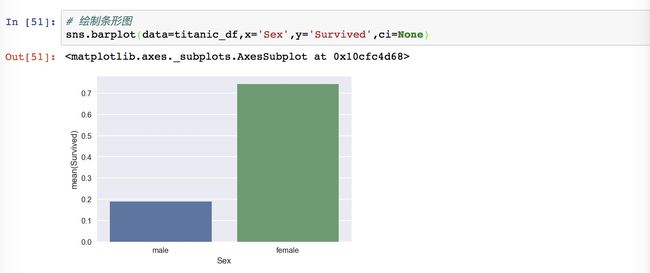
这就是图表和数字的差距啊!!!可视化!什么叫可视化!!!一下就能看出来明显的对比!
结论:女性幸存概率远远大于男性!
3-3 综合考虑舱位和性别的因素,与生还概率的关系
首先计算不同舱位不同性别的人的生还概率,和上面一样,有两种方法。

groupby 这里有两个变量,所以用列表的形式(也就是中括号),将变量传递给 groupby。同样,为了计算生还概率,用 mean 的方法来求得每一组的生还概率。
我们看到输出有两个索引,一个是舱位,一个是性别。可以看到在头等舱和二等舱的生还率中,女性的概率非常高,都超过了90%,三等舱的女性生还率只有50%,这个差距也是很大的。不管在哪个舱位来说,女性的生还概率还是远高于男性的。
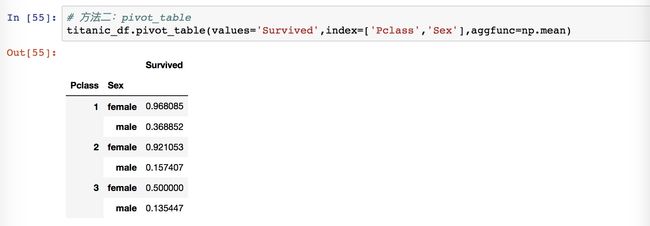
这里的 values 还是 Survived。这里的 index 就有点不同了,因为这里是两个因素,最后的结果是一个二重的索引,所以此处也要像上面一样弄成一个列表,表示将两个数据同时传递给 index,然后设置聚合的函数是 numpy 的均值。
这上面是 pivot_table 用二重索引的方法进行输出,其实 pivot_table 还有另外一种方法可以显示结果的:
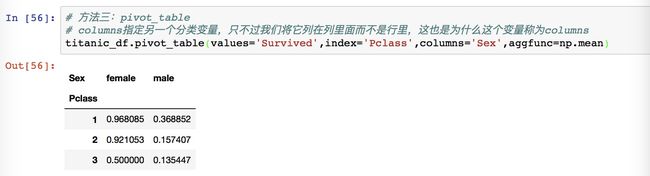
这里设置的 index 代表行索引是舱位。columns='Sex' 设置的是这个数据的列索引是性别,分为女性和男性。这里就体现了pivot_table 和 groupby 方法的差异了,pivot_table 表现得更灵活,它可以自由地设定表格的格式。
有了数据,我们来绘制图表。
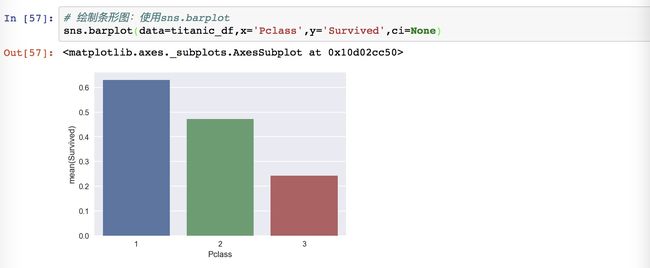
这个图是按照第一种情况下按不同生还概率绘制的直方图。
下图将展示用性别 Sex 进行分组的直方图,用的是 hue 方法,得到的是同时考虑舱位和性别两个数据的数据图了。
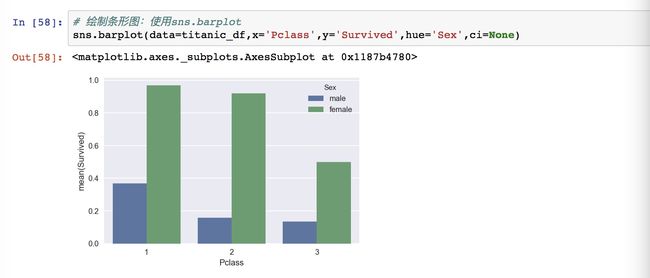
在这个图中就很明显可以看出,不管在哪个舱位中,女性的生还率都远远大于男性。随着舱位的下降,生还率也在降低。
除了直方图,我们还可以绘制折线图。设置的参数内容和上面的直方图barplot是一样的。
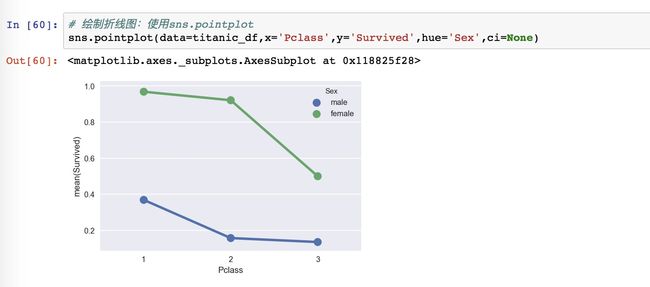
这个绘图函数自动帮我们进行了均值的计算,这个可以观察此处的Y轴。
这两个图(直方图,折线图)表达的结果是一样的,只是表现形式不一样。
结论:在各个舱位中,女性的生还概率都远大于男性。一二等舱的女性生还率接近,且远大于三等舱。一等舱的男性生还率大于二三等舱,二三等舱的男性生还率接近。
作业8-2:
分别使用 groupby 和 pivot_table, 计算在不同舱位中男女乘客的人数。(提示,使用count)
来来来,这次展示一下我做(抄)的作业:
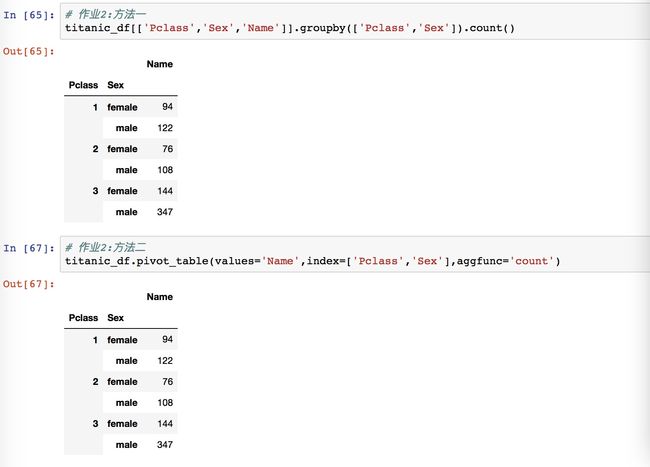
上面老师讲了那么久生还概率,做作业的时候看到乘客,我就还是想生还的数据,再想想审题不对啊,然后看 PassengerID,有点蒙圈。自己操作的最后一步是舱位和性别,没有 Name,得出的结果只有两个数,一个是男性一个女性的数字,没有舱位的分类。所以其实我自己的操作是错误的,上图才是正确演示。
输出没有错误提醒的时候,我是轻易放过去的,到了方法二,就被卡住了。前面老师讲了挺多次 values=‘Name’ 的意思,但是这里我不知道 values 要赋值什么呢?然后就不假思索去作业区偷看同学们的答案了:竟然是 Name!为什么我不知道还有这一列数据!?后面的 aggfunc='count' 竟然是要引号引起来的!这怎么是一个字符串呢,我的理解就是一个操作性的词汇啊,有魔法的那种,因为前面的例子是 aggfunc=np.mean 啊,这里的 mean 是没有引号的!
好吧,这节课特别长,加料全家桶。。。后面还有三小节的内容,将会在一篇文章汇总,不然第八课一节课就5篇文章也太夸张了。