介绍
在探索CNN一段时间之后,我决定尝试计算机视觉中的另一个关键领域,物体检测。这个领域有几种流行的方法,包括Faster R-CNN,RetinaNet,YOLOv3,SSD等。我在本文中尝试了Faster R-CNN。在这里,我想总结一下我所学到的知识。
我使用的Faster R-CNN的Keras版本的原始代码是由yhenon编写的(资源链接:GitHub 。)他使用了PASCAL VOC 2007,2012和MS COCO数据集。对我来说,我刚从Google的Open Images Dataset V4中提取了三个类,“人物”,“汽车”和“手机” 。我应用了与他的工作不同的配置来适应我的数据集,并删除了无用的代码。顺便说一句,要在Google Colab上运行此功能(免费GPU计算长达12小时)。
首先,我假设您了解CNN的基本知识以及什么是对象检测。这是原始论文的链接,名为“ Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks ”。
我阅读了许多文章,解释了与Faster R-CNN相关的主题。他们对此有很好的理解和更好的解释。顺便说一句,如果您已经了解有关更快的R-CNN的详细信息并且对代码更加好奇,您可以跳过下面的部分并直接跳转到代码说明部分。这是我这个项目的GitHub链接。
阅读建议:
Faster R-CNN: Down the rabbit hole of modern object detection
Deep Learning for Object Detection: A Comprehensive Review
Review of Deep Learning Algorithms for Object Detection
Faster R-CNN
R-CNN (R。Girshick等人,2014)是Faster R-CNN的第一步。它使用搜索选择性(JRR Uijlings and al(2012))来找出感兴趣的区域并将它们传递给ConvNet。它试图通过将类似的像素和纹理组合成几个矩形框来找出可能是对象的区域。R-CNN论文使用了来自搜索选择的2,000个建议区域(矩形框)。然后,将这2,000个区域传递给预先训练的CNN模型。最后,将输出(特征映射)传递给SVM进行分类。计算预测的边界框(bbox)和标记数据(bbox)之间的回归。
[图片上传失败...(image-540d3f-1557240461220)]
](https://upload-images.jianshu.io/upload_images/17144-a7ed569e011bc75b.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
Fast R-CNN(R。Girshick(2015))向前迈进了一步。它不是将2,000倍的CNN应用于建议的区域,而是仅将原始图像传递给预先训练的CNN模型一次。基于前一步骤的输出特征映射计算搜索选择性算法。然后,ROI池层用于确保标准和预定义的输出大小。这些有效输出作为输入传递给完全连接的层。最后,使用两个输出向量来用softmax分类器预测观察对象,并使用线性回归量来调整边界框局部化。
Faster R-CNN(简称frcnn)比Fast R-CNN进一步发展。搜索选择性过程由区域提议网络(RPN)取代。顾名思义,RPN是一个提出地区的网络。例如,在从预训练模型(VGG-16)获取输出特征图之后,如果输入图像具有600x800x3尺寸,则输出特征图将是37x50x256尺寸。

37x50中的每个点都被视为锚点。我们需要为每个锚定义特定的比率和大小(三种比例为1:1,1:2,2:1,原始图像中的三种尺寸为128128,256256,212*212)。
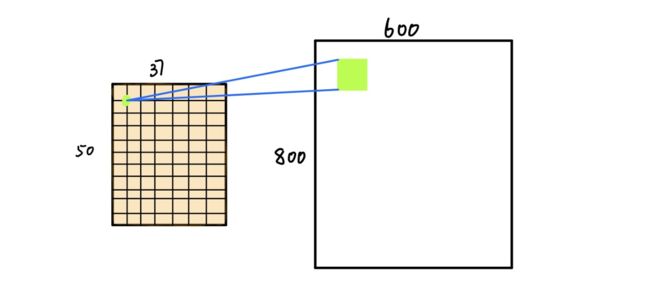
接下来,RPN连接到具有3x3滤波器,1个填充,512个输出通道的Conv层。输出连接到两个1x1卷积层进行分类和盒子回归(请注意,此处的分类是确定盒子是否为对象)
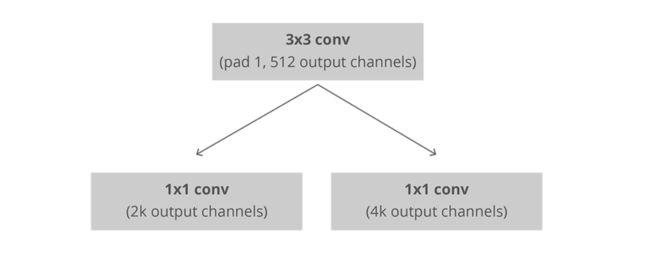
在这种情况下,每个锚在原始图像中具有3x3 = 9个对应的框,这意味着原始图像中有37x50x9 = 16650个框。我们只选择这些16650盒子中的256个作为迷你批次,其中包含128个前景(pos)和128个背景(neg)。同时,[non-maximum suppression](https://www.youtube.com/watch?v=A46HZGR5fMw)应用以确保建议的区域没有重叠。
完成上述步骤后,RPN完成。然后我们进入frcnn的第二阶段。与快速R-CNN类似,ROI池用于这些提议的区域(ROI)。输出为7x7x512。然后,我们用一些完全连接的层压平该层。最后一步是softmax函数,用于分类和线性回归以修复框的位置。

代码说明
第1部分:从Google的Open Images Dataset v4(Bounding Boxes)中提取自定义类的注释
下载并加载三个.csv文件
在官方网站上,您可以class-descriptions-boxable.csv通过单击下面图像底部的红色框来下载Class Names。然后转到Download from Figure Eight并下载其他两个文件。
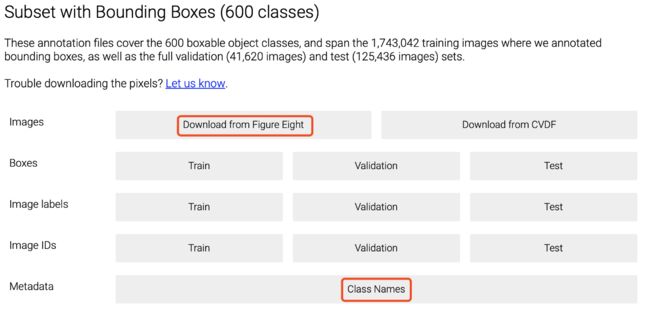
在图八的网站,我下载了train-annotaion-bbox.csv,并train-images-boxable.csv像下面的图片。
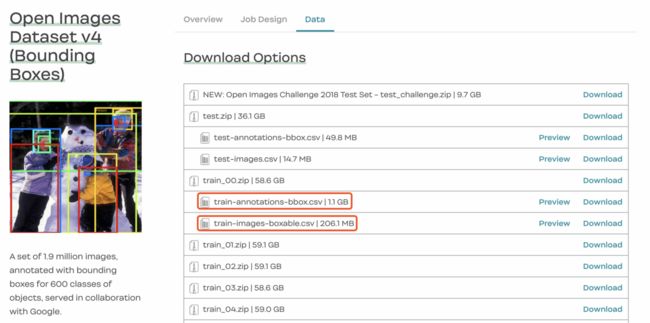
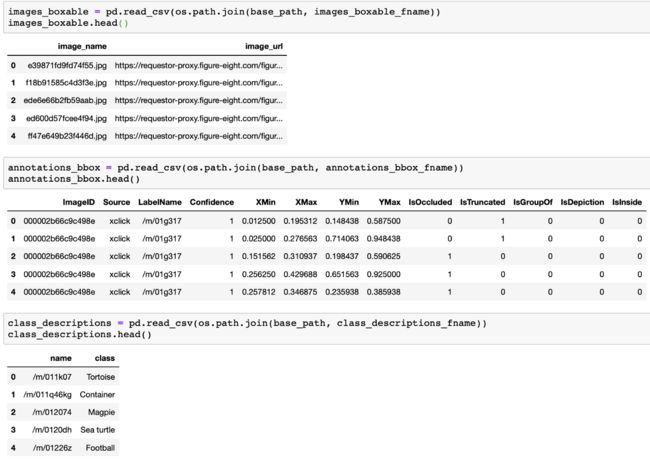
下载后,让我们看一下这些文件里面的内容。train-images-boxable.csv包含可装箱图像名称及其URL链接。class-descriptions-boxable.csv包含与其LabelName类对应的类名。train-annotations-bbox.csv有更多的信息。每个行train-annotations-bbox.csv包含一个图像的一个边界框(简称bbox)坐标,它还有这个bbox的LabelName和当前图像的ID(ImageID +'。jpg'= Image_name)。XMin, YMin是这个bbox的左上角,XMax, YMax是这个bbox的右下角。请注意,这些坐标值是标准化的,如果需要,应根据实际坐标计算。
获取整个数据集的子集
包含600个类的Open Images Dataset V4的整个数据集对我来说太大了。因此,我分别为“三个班级”,“人物”,“移动电话”和“汽车”提取了1,000张图像。
下载这3,000张图像后,我将有用的注释信息保存在.txt文件中。每行的格式如下:file_path,x1,y1,x2,y2,class_name(两个值之间没有空格只是逗号)其中file_path是此图像的绝对文件路径,(x1,y1)和(x2,y2)表示原始图像的左上角和右下角的实际坐标,class_name是当前边界框的类名。我使用80%的图像进行训练,使用20%的图像进行测试。预期的训练图像和测试图像的数量应该是3x800 - > 2400和3x200 - > 600.但是,可能会有一些重叠的图像同时出现在两个或三个类别中。例如,图像可能是在街上行走的人,街上有几辆车。所以训练图像的bbox数量是7236,
第2部分:更快的R-CNN代码
我将解释代码中的一些主要功能。每个函数的完整注释都写在.jpynb笔记本中。请注意,我将调整大小的图像保持为300以便更快地进行训练,而不是我在第1部分中解释的600。
重建VGG-16的结构并加载预先训练的模型(nn_base)

准备训练数据和训练标签(get_anchor_gt)
输入数据来自annotation.txt文件,该文件包含一堆带有边界框信息的图像。我们需要使用RPN方法来创建提议的bbox。
此函数中的参数
all_img_data:list(filepath,width,height,list(bboxes))
C:config
img_length_calc_function:根据输入图像大小
模式计算最终图层的特征图(基本模型)大小的函数:'train'或'test “; '火车'模式需要增强
返回此函数中的值
x_img:调整大小和缩放后的图像数据(最小尺寸= 300px)
Y:[y_rpn_cls,y_rpn_regr]
img_data_aug:增强图像数据(带增强的原始图像)
debug_img:显示调试图像
num_pos:显示正锚点的数量用于调试
计算每个图像的rpn(calc_rpn)
如果要素图的形状为18x25 = 450且锚尺寸= 9,则有450x9 = 4050个潜在锚点。每个锚点的初始状态为“否定”。然后,如果IOU> 0.7,我们将锚设置为正。如果IOU> 0.3且<0.7,则它是模糊的并且不包括在目标中。一个问题是RPN有更多的负面而不是正面区域,因此我们关闭了一些负面区域。我们还将正区域和负区域的总数限制为256. y_is_box_valid表示此锚点是否具有对象。y_rpn_overlap表示此锚点是否与地面实况边界框重叠。
对于'正'锚,y_is_box_valid= 1,y_rpn_overlap= 1。
对于'中性'锚点,y_is_box_valid= 0,y_rpn_overlap= 0。
对于'负'锚,y_is_box_valid= 1,y_rpn_overlap= 0。
此函数中的参数
C:config
img_data:增强图像数据
宽度:原始图像宽度(例如600)
高度:原始图像高度(例如800)
resized_width:根据C.im_size调整大小的图像宽度(例如300)
resized_height:调整大小后的图像高度到C.im_size(例如400)
img_length_calc_function:根据输入图像大小计算最终图层的特征图(基本模型)大小的函数
返回此函数中的值
y_rpn_cls:list(num_bboxes,y_is_box_valid + y_rpn_overlap)
y_is_box_valid:0或1(0表示该框无效,1表示该框有效)
y_rpn_overlap:0或1(0表示该框不是对象, 1表示框是一个对象)
y_rpn_regr:list(num_bboxes,4 * y_rpn_overlap + y_rpn_regr)
y_rpn_regr:x1,y1,x2,y2 bunding boxes coordinates
形状y_rpn_cls为(1,18,25,18)。18x25是特征地图大小。特征映射中的每个点都有9个锚点,每个锚点的值分别为2 y_is_box_valid和y_rpn_overlap。所以第四个形状18是9x2。
形状y_rpn_regr为(1,18,25,72)。18x25是特征地图大小。在特征图中的每个点具有9个锚和每个锚具有用于4个值tx,ty,tw和th分别。请注意,这4个值都有自己的y_is_box_valid和y_rpn_overlap。因此第四形状72是9x4x2。
从RPN计算感兴趣的区域(rpn_to_roi)
此函数中的参数(num_anchors = 9)
rpn_layer:rpn分类
形状的输出图层 (1,feature_map.height,feature_map.width,num_anchors
)如果调整大小的图像为400宽度且300
regr_layer,则可能是(1,18,25,9):
rpn 回归形状的输出图层(1,feature_map.height,feature_map.width,num_anchors * 4
)如果调整大小的图像是400宽度和300
C,可能是(1,18,25,36):config
use_regr:使用bbox
rpn max_boxes中的回归:非最大抑制的最大bbox数(NMS)
overlap_thresh:如果你在NMS中大于此阈值,则删除该框
返回此函数
结果中的值:非max-suppression(shape =(300,4 ))
框中的框:bbox的坐标(在要素图上)
对于来自上述步骤的4050个锚点,我们需要提取max_boxes(代码中的300个)框数作为感兴趣区域并将它们传递给分类器层(frcnn的第二阶段)。在该函数中,我们首先删除超出原始图像的框。然后,我们使用具有0.7阈值的非最大抑制。

RoIPooling图层和分类器图层(RoiPoolingConv,classifier_layer)
RoIPooling层是通过max pooling将roi处理为特定大小输出的函数。每个输入roi被分成一些子单元,并且我们将max pooling应用于每个子单元。子单元的数量应该是输出形状的尺寸。

分类器层是整个模型的最后一层,位于RoIPooling层的后面。它用于预测每个输入锚点的类名称及其边界框的回归。
此函数中的参数
base_layers:vgg
input_rois:(1,num_rois,4)rois列表,带有排序(x,y,w,h)
num_rois:一次处理的rois数(此处为4)
返回此函数
列表中的值(out_class,out_regr)
out_class:分类器层输出
out_regr:回归层输出
首先,汇集层是扁平的。
然后,接着是两个完全连接的层和0.5个丢失。
最后,有两个输出层。
out_class:softmax激活函数,用于对对象的类名进行分类
out_regr:线性激活函数,用于bboxes坐标回归
数据集
同样,我的数据集是从Google的Open Images Dataset V4中提取的。选择“Car”,“Person”和“Mobile Phone”三个班级。每个类包含大约1000个图像。“Car”,“Mobile Phone”和“Person”的边界框数分别为2383,1108和3745。
参数
已调整大小(im_size)的值为300。
锚的数量是9。
最大非最大抑制数为300。
在模型中处理的RoI数量是4(我没有尝试过更大的尺寸,这可能会加快计算速度但需要更多内存)
Adam用于优化,学习率为1e-5。如果我们应用原始论文的解决方案,它可能会有所不同。对于60k小批量,他们使用的学习率为0.001,对于PASCAL VOC数据集中的下一个20k小批量,他们的学习率为0.0001。
对于图像增强,我打开horizontal_flips,vertical_flips和90度旋转。
环境
谷歌的Colab采用特斯拉K80 GPU加速进行训练。
训练时间
我选择的每个纪元的长度是1000.请注意,每个批处理只处理一个图像。我训练的时期总数是114.每个时期在这种环境下花费大约700秒,这意味着训练的总时间大约是22小时。如果您像我一样使用Colab的GPU,则需要重新连接服务器并在自动断开连接时加载权重以进行继续训练,因为每个会话都有时间限制。
结果
我们将两个损失函数应用于RPN模型和分类器模型。正如我们之前提到的,RPN模型有两个输出。一个用于分类它是否是一个对象而另一个是用于边界框的坐标回归。从下图中,我们可以看到它在前20个时期学得非常快。然后,分类器层变慢,而回归层仍然继续下降。其原因可能是我们训练的早期阶段对象的准确性已经很高,但与此同时,边界框坐标的准确性仍然很低,需要更多的学习时间。

类似的学习过程在分类器模型中显示。与bboxes回归的两个图相比,它们显示出类似的趋势,甚至类似的损失值。我认为这是因为它们预测了非常相似的值,并且它们的层结构略有不同。与两个用于分类的图相比,我们可以看到预测对象比预测bbox的类名更容易。

这个总损失是上面四个损失的总和。它有下降的趋势。但是,mAP(平均平均精度)不会随着损失的减少而增加。当时期数为60时,mAP为0.15.当时期数为87时,mAP为0.19。当时期数为114时,mAP为0.13。我认为这是因为训练图像数量少,导致过度拟合模型。
我们可以调整的其他事情
适用于较短的训练过程。我选择300作为im_size调整大小的图像而不是原始代码中的600(和原始文件)。所以我选择较小的anchor_size[64,128,256]而不是[128,256,512]。
我选择VGG-16作为我的基础模型,因为它具有更简单的结构。但是,像ResNet-50这样的模型可能会有更好的结果,因为它在图像分类方面具有更好的性能。
模型中有许多阈值。我使用它们中的大多数作为原始代码。rpn_max_overlap=0.7并且rpn_min_overla=0.3是区分每个锚点的“正面”,“中性”和“负面”的范围。overlap_thresh=0.7是非最大抑制的阈值。
测试图像
在笔记本中,我将训练过程和测试过程分为两部分。在运行测试.ipynb笔记本之前,请重置所有运行时,如下所示。也许你需要在运行测试笔记本时关闭训练笔记本,因为内存使用几乎没有限制。

最后
为了获得乐趣,您可以创建自己的数据集,该数据集未包含在Google的Open Images Dataset V4中并对其进行训练。对于我在本文中使用的封面图片,他们是由中国制作的三位porcoelainous僧侣。我只是根据他们的脸型来命名它们(不确定那个困了)。它们不包含在Open Images Dataset V4中。所以我使用RectLabel来自己注释。我用了大约3个小时的时间将46个图像(包括' Apple Pen ',' Lipbalm ',' Scissor ',' Sleepy Monk ',' Upset Monk '和' Happy Monk ')拖入6个等级的地面真相盒中。为了anchor_scaling_size,我选择[32,64,128,256]因为Lipbalm通常在图像中很小。找到这些小方形唇膏。我为较强的模型添加了较小的锚尺寸。考虑到Apple Pen长而薄,anchor_ratio可以使用1:3和3:1甚至1:4和4:1,但我还没试过。训练时间不长,表现也不错。我想这是因为相对简单的背景和简单的场景。实际上,我发现更难的部分不是注释这个数据集,而是考虑如何拍摄它们以使数据集更加健壮。
更多信息扫描二维码关注
