新框架ES-MAML:基于进化策略、简易的元学习方法

作者 | Xingyou Song、Wenbo Gao、Yuxiang Yang、Krzysztof Choromanski、Aldo Pacchiano、Yunhao Tang
译者 | TroyChang
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】现有的MAML算法都是基于策略梯度的,在试图利用随机策略的反向传播估计二阶导数时遇到了很大的困难。
本文为大家介绍一个新框架ES-MAML,这是一个基于进化策略,解决与模型无关的元学习(model agnostic meta learning,MAML)问题的新框架。

在这篇论文中展示了如何将ES应用于MAML,从而获得一种避免二阶导数估计问题的算法,并且在概念上简单且易于实现。此外,ES- maml可以处理新型的非平滑自适应算子,其他改进ES方法性能和估计的技术也变得适用。本文通过实验证明ES-MAML与现有方法相比是有竞争力的,并且通常在较少的查询下产生更好的适应性。
论文地址:https://arxiv.org/pdf/1910.01215.pdf
引言
元学习是机器学习的一种范式,其目的是开发能够快速适应新任务和数据的模型和训练算法。这篇论文的重点是元学习中的强化学习(Reinforcement Learning, RL),其中数据效率是至关重要的,因为收集新的样本往往需要昂贵的模拟或与现实世界的互动。RL元学习的一个流行技术是模型无关元学习(MAML),这是一种训练代理(元策略)的模型,可以通过在新环境中执行一个(或几个)梯度更新来快速适应新的和未知的任务。
虽然MAML在许多应用方面表现很好,但是实现和运行MAML仍然是很难。一个主要是它的复杂性,MAML是需要估算强化学习中奖励函数的二阶导数,这对于随机策略的反向传播来说是很难实现的。另一个就是策略梯度方法固有的过拟合性。为解决这些问题,本文提出了一种进化策略的MAML,ES-MAML有以下4个优点:
1、不需要估计任何二阶导数。这避免了在随机策略上用反向传播法估计二阶导数所引起的许多麻烦。
2、比梯度策略简单很多,因为没有ES没有不使用反向传播,所以ES也只能在cpu上运行。
3、具有高度的灵活性,含有不同的适应操作符。
4、ES可以使用确定性策略,保证准确性。还可以使用其他紧凑策略。
关于第(4)点,ES算法的一个特点是在参数空间中进行探索。策略梯度方法的主要动机是通过随机操作与环境的交互作用,而ES则是由具有昂贵查询模型的高维参数空间的优化驱动的。在MAML的背景下,“探索”和“任务识别”的概念因此被转移到参数空间而不是动作空间。这种区别对算法的稳定性起着至关重要的作用。一个直接的含义是,我们可以使用确定性策略,不像策略梯度是基于随机策略。另一个不同之处在于,ES只使用总奖励,而不使用每一集的状态-动作对。虽然这似乎是一个弱点,因为使用的信息较少,但在实践中发现,这似乎会导致更稳定的训练概况。
ES-MAML算法
ES-MAML主要在MAML算法上改进了两个地方:元学习训练算法和自适应算子的效率。
MAML目标:

MAML算法要解决的主要问题就是估算
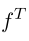 里面的Hessian矩阵。在原始Monte Carlo ES梯度算法上,利用Gaussian平滑机制,再通过联合估计抽样和评估优化算法。我们称为零阶ES-MAML。
里面的Hessian矩阵。在原始Monte Carlo ES梯度算法上,利用Gaussian平滑机制,再通过联合估计抽样和评估优化算法。我们称为零阶ES-MAML。

算法2
在零阶ES-MAML中加入自适应算子,就成了我们提出的基于梯度自适应的零阶ES-MAML,如算法3。

算法3
实验
MAML算法的性能可以通过多种方式进行评估。一项重要的方式是最终元策略的性能:该算法是否可以持续产生具有良好适应性的元策略。在RL设置中,元策略的适应性还取决于所使用查询次数的数量K:即适应运算符U(.,T).所使用的部署数量。元训练的速度也很重要,可以通过以下几种方式进行衡量:元策略更新的次数,挂钟时间和用于元训练的推进次数。在本节中,我们将介绍从数据效率(K)和元训练时间方面评估ES-MAML和PG-MAML各个方面的实验。
在RL设置中,如果应用ES方法,所使用的信息量会急剧减少。准确地说,ES只使用一个事件的累积奖励,而策略梯度使用每个状态-动作对。因此,我们可能会直观地认为,ES应该具有更糟糕的抽样复杂性,因为它对相同数量的滚动使用更少的信息。然而,在实践中,ES似乎经常匹配甚至超过策略梯度方法。有几种解释被提出:在PG的情况下,特别是像PPO这样的算法,网络必须优化多个额外的代理目标,如熵加值和值函数,以及超参数,如TD-步骤数。此外,有人认为,ES对延迟奖励、行动频率低和长期视野更有抵抗力。在传统的RL中,ES的这些优点也转移到了MAML中,我们在本节中对此进行了实证说明。ES可能会在挂钟时间方面带来额外的优势(即使训练所需的滚数与PG相当),因为它不需要反向传播,并且可以在cpu上并行化。
作者将ES-MAML与PG-MAML做对比验,在数据效率(K)和元训练时间等方面上比较算法性能。图1演示了ES-MAML在四角基准上的行为表现。实验是在奖励非常稀疏的环境中进行的,其中元策略必须表现出具有探索性的行为。为此我们引入了“四角基准”,以证明PG-MAML算法的弱点,一个2D方块上的代理会因为移动到方块上选定的一个角落而获得奖励,但只有当它足够接近目标角落时才会观察奖励,从而使奖励变得稀疏。在图1中,我们演示了ES-MAML在四个角问题上的行为。当K = 20时,算法3的基本版本能够通过找到目标角正确地探索和自适应任务。此外,它不需要任何修改来鼓励探索,不像PG-MAML。我们进一步使用K = 10.5,导致性能下降。
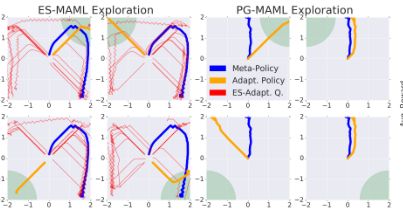
图1
对于实际的应用程序,我们可能会被限制使用较少的查询K,这在以前的MAML工作中已经得到了典型的证明。因此,比较ES-MAML与PG-MAML在适应度非常低的K方面的差异是很有意义的。一种可能的情况是,低K可能会特别损害ES,因为它只使用累积奖励;如果K = 5,则ES自适应梯度只能利用5个值。相比之下,PG-MAML使用K·H状态动作对,因此对于K = 5、H = 200, PG-MAML仍然有1000条可用信息。
然而,我们通过实验发现,即使在低k环境中,标准ES-MAML(算法3)仍然与PG-MAML具有竞争力。在图2中,我们比较了ES-MAML和PG-MAML在四种环境(半豹、游泳者、Walker2d、Ant)和两种模型架构上的前进-后退和目标-速度任务。一般来说,PG-MAML在目标-速度任务上的表现优于ES-MAML,而ES-MAML在前向-后向任务上的表现与ES-MAML相似,甚至更好。此外,我们观察到,对于低K, PG-MAML可能是高度不稳定的(请注意宽的误差条),一些轨迹会灾难性地失败,而ES-MAML相对稳定。在实际应用中,这是一个重要的考虑因素,因为灾难性故障的风险是不受欢迎的。

图2
总结
本文提出了一种基于ES算法的MAML新框架。ES-MAML方法避免了Hessian估计问题,后者需要在PG-MAML中进行复杂修改,并且易于实现。ES- MAML在选择适应操作符方面很灵活,并且可以通过对ES的一般改进以及更奇特的适应操作符进行增强。特别是,ES-MAML可以与非平滑的适应操作配对,通过实验发现,这可以产生更好的探索行为,并在稀疏奖励的环境中,该算子可以获得更好的性能。ES-MAML在使用线性或紧凑的确定性策略时表现良好,如果状态动态可能不稳定,则采用这种策略是一种优势。
(*本文为 AI科技大本营编译文章,请微信联系 1092722531)
◆
彩蛋~ ◆
1024程序员节超值特惠限时秒杀!活动时间:2019年10月24日00:00-24:00凡在此活动期间购买大会单人票,即送价值298元的CSDN VIP年卡!
(VIP年卡特权:全站免广告+600个资源免积分下载+学院千门课程免费看+购课9折)

推荐阅读
你点的每个“在看”,我都认真当成了AI