新建工程
scrapy startproject fanfou
该工程的目录结构如下图所示:

fanfou.png
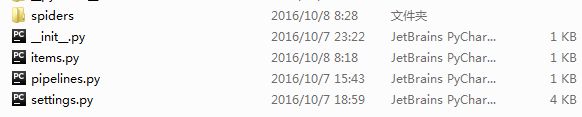
spiders.png
main.py 文件的内容如下:
# -*- coding:utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl fanfou".split())
这个文件与 scrapy.cfg 存放在同一目录下, 用于在 Pycharm 中调试和运行爬虫时使用, 如果 Pycharm 项目中没有这个文件的话, 会提示找不到模块 fanfou。
在 items.py 中设置要抓取的字段:
# -*- coding: utf-8 -*-
from scrapy.item import Item, Field
class FanfouItem(Item):
# define the fields for your item here like:
home_url = Field()
title = Field()
avatar = Field()
content = Field()
location = Field()
Spiders
#-*- coding:utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from scrapy.http import Request, FormRequest
from fanfou.items import FanfouItem
class FanfouSpider(CrawlSpider):
name ="fanfou"
# 重写爬虫类中的请求方法, 实现自定义请求
def start_requests(self):
# 这里请求饭否主页是为了获取登录用的 token
return [Request(url="http://fanfou.com/", method='get', callback = self.start_login)]
# 登录
def start_login(self, response):
print(" -> Start login...")
token = Selector(response).xpath('//form/p[@class="act"]/input[@name="token"]/@value').extract()[0]
print(" -> Token is %s" % token)
return [FormRequest(
url="http://fanfou.com/login",
formdata = {
'loginname': '[email protected]',
'loginpass': '*************',
'action': 'login',
'token': token,
'auto_login': 'on'
},
callback=self.after_login
)]
def after_login(self, response):
#print(response.body) # 打印返回的 html, 里面有我的个人信息, 说明登录成功了
# 登录成功后, 找出我关注的人的信息
print(" -> Login Successfully...")
return Request("http://fanfou.com/friends/luo", callback=self.parse_friends)
def parse_friends(self, response):
item = FanfouItem()
messages = Selector(response).xpath('//ol[@class="wa"]/li')
for li in messages:
item['home_url'] = li.xpath('a/@href').extract()[0] # 个人主页
item['title'] = li.xpath('a[@class="name"]/text()').extract()[0] # 姓名
item['avatar'] = li.xpath('a[@class="avatar"]/img/@src').extract()[0] # 头像地址
# 有些人没有发言
if li.xpath('p[@class="lastmsg"]'):
item['content'] = li.xpath('p[@class="lastmsg"]')[0].xpath('string(.)').extract()[0] # 发言
else:
item['content'] = ''
# 有些人的资料没有写"所在地", 需要判断
if li.xpath('p[@class="location"]'):
item['location'] = li.xpath('p[@class="location"]')[0].xpath('string(.)').extract()[0] # 地址
else:
item['location'] = ''
yield item
重写 start_requests 方法, 这是所有请求的入口, 这里从这个方法中预请求了一次饭否的主页, 是为了获取响应中的 token 字段的值, 这个值将用于登录。所以请求结束后就使用回调函数 start_login 来处理刚才的响应(response)。
登录时我们使用 FormRequest 这个能处理表单的类方法来处理表单数据。登录成功则调用回调函数 after_login, 在 after_login 中我们打印登录成功的提示, 然后请求我们真正需要的网址(前面都是做铺垫), 调用回调函数 parse_friends 来解析朋友们的信息。
最后输出为 csv 文件:
scrapy crawl fanfou -o info.csv
输出的 csv 文件有乱码问题, 用编辑器改正编码, 然后重新用 Excel 打开。
写入 Excel
安装 openpyxl 模块:
pip install openpyxl
在 pipelines.py 中做如下设置:
# -*- coding: utf-8 -*-
from openpyxl import Workbook
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class FanfouPipeline(object):
wb = Workbook()
ws = wb.active
ws.append(['主页', '名字', '头像', '发言','位置'])
def process_item(self, item, spider):
line = [item['home_url'], item['title'], item['avatar'], item['content'], item['location']]
self.ws.append(line)
self.wb.save('f.xlsx')
return item
在 setting.py 中打开 ITEM_PIPELINES 设置:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'fanfou.pipelines.FanfouPipeline': 200,
}
其它地方不用动, 你就得到了一个格式良好的 xlsx 文件。

xlsx.png