翻译/编辑/部分原创 Vivian Ouyang 原作者:Sunil Ray
在机器学习中,很多时候你会挣扎于怎么提高模型的准确率。在这种时刻,数据探索的一些方法将帮助你解决这个问题。这个指导将帮助你理解数据探索中的主要技术。请记住你输入的变量的数据质量决定了你模型输出量的质量。所以当你的商业问题提出来以后,你需要花费很多时间在数据准备和探究上面,一般来说,数据清理,探究和准备大概占据了一个项目70%的时间。下面是准备,理解,清理你用于建立预测模型的数据的几个步骤,我会一个一个来介绍
1.变量确定
2.单变量分析
3.双变量分析
4.处理缺失值
5.处理离群值
6.变量转换
7.变量创建
首先上部会介绍1,2,3,4四个部分。
变量确定
首先,你需要确认你的输入变量(预测指标)和你的输出变量(目标变量)是什么,接着,你需要确认数据的种类和分类。下面用一个简单的例子来说明,假设现在我们想要预测学生是否玩板球(cricket),现在我们需要确定输入变量,输出目标变量,以及每一个变量的分类和种类,下面是部分原数据
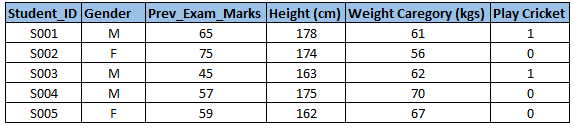
Student_ID:学生编号
Gender:性别(F-女,M-男)
Pre_EXAM_Marks:之前的考试分数
Height(cm):身高(厘米)
WeightCaregory(kgs):体重(千克)
Play Cricket:玩板球(1:玩板球,0:不玩板球)
下面这个图是以上变量的分类和种类图

从上图可以看到,输入变量(预测变量Predictor)是性别,之前的考试分数,身高,体重。而输出值(目标变量Target)是是否玩板球。学生编号和性别是字符变量(Character),是否玩板球,之前的考试分数,身高,体重是数字变量(Numeric)。从连续和非连续来分类的话,性别和是否玩板球是非连续变量(Categorical),之前考试的分数,身高和体重是连续变量(Continuous)
单变量分析
在这个步骤,我们需要一个变量一个变量的去做分析,单变量分析的方法取决于你需要分析的变量是连续的还是非连续的。
连续型变量(Continuous Variable):对于连续型变量我们需要知道这个变量的中心(central tendency)和展布(spread or dispersion),下面是描述变量中心还有展布的指标量,以及用什么图来进行可视化。

中心:平均值,中位数,众数,最小值,最大值
展布分布:范围,四分位数,内距(四分位距),方差,标准差,偏态与峰度
可视化方法:直方图(最右的图),箱线图(中间一个图)
非连续型变量(Categorical Variable):对于非连续型变量,我们使用频率表来显示每一个分类的分布,同时我们也可以计算每一个分类的百分比。一般可以使用条形图或者箱线图来可视化
双变量分析
双变量分析是用来找出两个变量之间的关系,我们寻找两个变量间有显著水平的相关联和非相关联性。双变量分析可以是非连续型变量和非连续型变量,非连续型变量和连续型变量还有连续型变量和连续型变量。下面我们将一个一个情形来说明。
连续型变量和连续型变量:对于两个连续型变量,一般可视化我们使用散点图。散点图很好的显示了两个变量的关系,这个关系可以是线性也可以是非线性的。

上面的六个图,左上是很强的正相关,意思是指当其中一个变量增加时,另外一个变量增加,上面正中间的是中等强的正相关,右上是没有相关性,左下是中等强的负相关,意思是指当其中一个变量增加时,另外一个变量减少,下面正中间是很强的负相关,右下是非线性的相关。一般散点图只是显示了两连续变量之间的关系,但是并没有显示关系的强度大小。所以我们使用一个指标相关(Correlation)来显示关系强度的大小,相关的大小可以从-1到+1。其中“-1”指的是完美的负线性相关,“+1”指的是完美的正线性相关,“0”指的是没有线性相关(但是可能有非线性的关系)。计算相关的公式如下
相关=变量X和Y的协方差/变量X的方差和变量Y的方差乘积的平方根
如果使用Excel,可以用CORREL()来计算两个变量的相关。如果使用SAS可以使用PROC CORR来计算相关,如果用R,可以使用cor.test()来计算相关。如果用Python,可以使用numpy.corrcoef()来计算。下面是用EXCEL计算相关的例子,X和Y的相关系数是0.65。

非连续变量和非连续型变量:
双向表(two-way table):我们可以用一个双向表来分析两个非连续变量的关系,双向表的行代表一个非线性变量的分类,列代表另一个非线性变量的分量,然后每个小格(cell)可以显示数目还有所占的百分比(双向表是下面最左边的表)。

堆积柱图(Stacked Column Chart):这个其实就是双向表的可视化(上面右边两个表)
卡方检验(Chi-square Test):这个检验是用来检验变量关系的显著性。主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。它会反馈用卡方分布计算的p值,当p=0的时候,这两个变量是相互依赖的(dependent),当p=1的时候,可以理解为这两个变量独立(independent),当p值小于0.05的时候,意味着有95%的信心这两个变量的依赖性是显著的。卡方检验的统计量是
其中O表示实际观察到的频数,而E表示当这两个变量独立的时候,双向表中每个cell的理论频数。
非连续变量和连续型变量:
对于探索连续变量和非连续变量的关系,对于可视化,我们可以画非连续变量每一个分类的箱线图(boxplot)。而如果想用统计方法来检验它们之间的关系是否显著,可以使用Z检验,t检验或者方差分析(ANOVA)。一般Z检验用于样本比较大的情况,检验的是两组之间的均值是否有显著不同。t检验一般用于样本比较小的情况(每一组都小于30),检验的也是两组之间均值是否有显著不同。而ANOVA是用来检验多于两组的时候, 多个组的均值是否有不同。
缺失值处理
在数据清理中,我们经常会遇到很差的数据,会有很多缺失值,如果训练数据中有缺失值的话会让训练出来的模型有偏差或者不够拟合数据。缺失值出现的原因也有很多种,它们一般出现在两个阶段
数据抓取:在抓取数据过程中,因为没有符合抓取的指导或者要求,而造成的一种缺失,这种缺失比较容易被发现并且很快的改正
数据收集:在数据收集阶段的缺失比较难改正,因为有大概四种不同的情况
完全随机缺失(Missing Completely at Random):这种情况是指对每一个观测值,缺失的概率是一样的。打个比方,比如现在需要一群人上报自己的收入,对于每一个上报者,在上报之前先丢硬币,如果是正面就上报收入,如果是反面就隐瞒收入。因此对每个观测值都有一半的机会缺失或者不缺失。
随机缺失(Missing at Random):随机缺失是指缺失值是任意缺失的但是对不同的输入变量和分组,缺失值的比例是不同的。比如当我们想收集女性的年龄时,女性比起男性会有更多的缺失值(很好理解,女性一般不太喜欢被访问年龄)。
缺失依赖于未观测到的自变量 (Missing that depends on unobserved predictors):
当缺失值不是任意随机的,而是和某些我们没有观测到的值有关。打个比方,比如在医药研究中,如果一种治疗方法引起了病人身体的不适应,那么病人有很大的概率会提前从这个研究中退出导致最后他/她的观测值是缺失的,这种缺失不是任意的而是和身体不适应相关的。
缺失值依赖于缺失值本身 (Missing that depends o the missing value itself):
当缺失的概率直接和缺失值本身有关的时候。比如,一般很高收入和很低收入的人不太喜欢被访问收入多少,因此收入会有缺失值。
处理缺失值的方法
a. 删除:表删除(List-wise Deletion)和对删除(Pair-wise)
通常的数据表中,行代表样本,列代表不同的变量。在列表删除中,只要一行有任何一个变量的值有缺失,我们就删除一整行的信息。简单是这个方法的主要优势,但是很大的劣势也是这样严格的删除会导致样本量的减少。在成对删除中,我们对每一个变量就用它不缺失的样本数进行逐个分析,这种方法尽量的保留了样本个数,但是不好的是对每一个变量你所使用的样本个数也不一样。两种删除方法如下图例子所示,左边是表删除,而右边是对删除,你可以看到左下图任何一行有缺失就会被划掉删除,而右下表,对性别(gender),劳动力(manpower),销售(sales)变量每一个分别删除缺失值,而不是一行全部划掉。
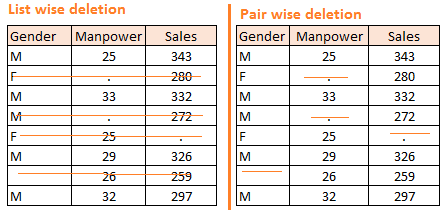
主要备注:删除的方法只能用于完全随机缺失(Missing Completely at Random)的情况,随意删除不随机的缺失值会使数据产生bias。
b. 均值(mean)/众数(mode)/中位数(median)替换法
替换法是用估计的值去替换缺失值的方法。这个方法的目的是利用已知的可以定义的不缺失的数据去帮助估计缺失的数据。均值/众数/中位数这三个都是经常被广泛使用的方法。这种替换法一般也有两大类:
第一种就是一半的替换,就是我们计算缺失的变量剩下不缺失的数据的均值,众数或者中位数来替换缺失值。例如上图那个例子,对劳动力那一个变量的缺失值,我们计算不缺失的劳动力的数据得到28.33,然后用这个值来替换缺失值。
第二种就是相似替换,比如在上图那个例子里的劳动力,我们分别计算不缺失的男和女的劳动力平均值,分别是男29.75而女25,因此对于男,缺失的劳动力就用29.5替代,而对于女,缺失的劳动力就用25替代。
c.预测模型
用预测模型来估算缺失值也是一种理论比较成熟的方法。一般我们会把数据集分为两个部分,一个部分完全没有缺失值,而另一个部分含有缺失值。没有缺失值的数据集作为我们的训练数据集来得到预测模型,而有缺失值的数据集作为检验数据集,而缺失的变量就作为要预测的目标输出量。下一步,我们用训练集生成一个预测模型,用其他的变量来预测缺失的变量,然后把预测模型用到检验数据集来得到缺失部分的预测值。我们可以使用回归,方差分析,逻辑回归或者其他的机器学习的方法去做预测模型。
不过这个方法也有明显的缺点,如果缺失的变量与其他的变量没有什么关系,这个预测将会不准确。
d. 最近邻居法(KNN)
在这个替换方法中,我们用缺失值周围的离它最近或者是最相似的其他变量来估算。一般两个变量的相似度是有距离来决定的。距离的定义可以有多种。这个方法的优点就是缺失值是连续的或者非连续的变量都可以替换。不需要对每一个缺失的变量生成预测模型。数据变量间的关系也都被考虑进去了。而缺点是对于很大的数据集,这个方法很耗时,因为它会搜索所有的相似变量,而且k值的选择(就是缺失值周围选k个点)也是很重要的,高的k值会让几乎和缺失变量不相关的变量包含进来,而低的k值都会把很相关的变量可能排除出去。
下部我将介绍5,6,7步骤,也就是离群值处理,特征工程里面的变量转换和创建。Continued~
资源来源:https://www.analyticsvidhya.com/