本文首发于微信公众号《与有三学AI》
[caffe解读] caffe从数学公式到代码实现1-导论
我这个系列caffe代码解读跟大部分人的思路不一样,一般读caffe代码思路是按照caffe的层级结构来,blob到layer到net各自分层来读,但我想提供一个另外的思路,从数学公式到代码实现。
从每一个文件背后具体的数学含义来读,这对于我们非数学系或者数学基础不是很好的工程人员来说,是比较适合的。
那么,我会采取什么样的形式呢,就是,layer definition,caffe layer,caffe test layer的格式,举个例子来说,比如softmax,那我就打算从softmax的数学定义,caffe softmax层的实现,caffe softmax test layer的实现。一定要加上test layer,因为当我们自己实现某些类时,往往需要梯度反向求导,这时候最好自己写test来验证自己的代码是否正确。
好了,下面就开始吧。当然,现在这是第一篇,所以我们还是不可避免先打下基础,先要阅读下面的内容,对caffe的代码有基本的了解。这是include/caffe下面的代码list。
blob.hpp
caffe.hpp
common.hpp
data_transformer.hpp
filler.hpp
internal_thread.hpp
layer.hpp
layer_factory.hpp
net.hpp
parallel.hpp
sgd_solvers.hpp
solver.hpp
solver_factory.hpp
syncedmem.hpp
一个一个来。
1 blob.hpp&cpp
blob是caffe中的基础数据单元,一个blob是一个四维张量,(N,C,H,W),N是batch size大小,C是channel,H,W分别是图像宽高,由于caffe擅长于做图像,所以这个定义天然适合图像。故一个256*256的rgb图像,blob size是(1,3,256,256)。
blob.hpp,需要注意的就是下面的变量和函数

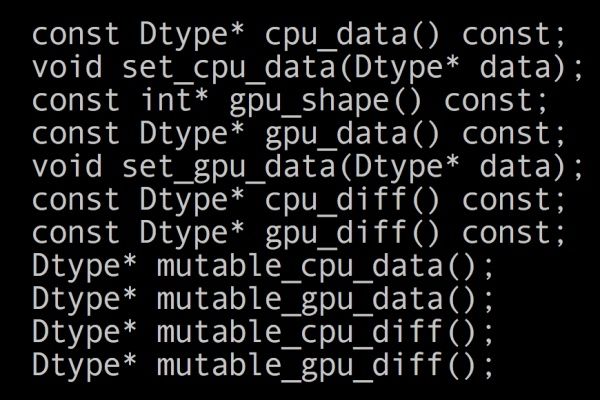
其中data_存储数据,diff_存储梯度,shape_分别是blob_的尺度,count_是所有数据数目,即N*C*H*W。
以后要访问这些数据,就会用到下面的函数,其中cpu_data是只读,mutable_cpt_data是可写,gpu类似。
上面还有一个疑问,那就是初次见到SyncedMemory类会不知道它是做什么的,它主要负责在GPU或者CPU上分配内存以及保持数据的同步作用。
可参考下面资料。
http://blog.csdn.net/xizero00/article/details/51001206
http://www.cnblogs.com/korbin/p/5606770.html
由于展开是另一个篇幅,因此我们不过多停留在此,知道blob是通过这样的方式存取即可。
2 caffe.hpp,common.hpp,internal_thread.hpp, parallel.hpp, syncedmem.hpp,solver_factory.hpp,layer_factory.hpp,sgd_solvers.hpp
把这几个放这里,是因为其中一些是gpu编程和内存等较为底层的编程的,看起来比较费劲,我们一般的应用其实也不需要对此有太深了解,大家会用即可。另外还有sovler这个类大家仔细读读即可。
caffe.hpp包含其他基础hpp。
internal_thread.hpp,与线程有关的变量函数。
parallel.hpp,与并行有关的变量函数。
syncedmem.hpp,内存分配和Caffe的底层数据的切换
solver_factory.hpp,layer_factory.hpp,顾名思义,分别是caffe solver的工厂类模板定义和普通layer的模板定义。
举例拿sovler来多说几句,solver_factory.hpp,其中solver指的是优化方法,由于caffe优化采用的就是梯度下降的方法,包括SGD,NesterovSolver,RMSPropSolver,AdamSolver等通通都定义在sgd_solvers.hpp中。
工厂设计模型,简单了解如下
http://developer.51cto.com/art/201107/277728.htm
http://alanse7en.github.io/caffedai-ma-jie-xi-4/
深入了解需要自己去看,从代码的角度来看就是解决重复造轮子的问题,减少重复代码,在caffe的面试中经常会问到噢。
看下它的代码,重要变量两个
typedef Solver* (*Creator)(const
SolverParameter&);
typedef std::map
CreatorRegistry;
重要函数两个个,
static CreatorRegistry& Registry() { static CreatorRegistry*
g_registry_ = new CreatorRegistry();
return *g_registry_;
}
static Solver* CreateSolver(const
SolverParameter& param) {
const string& type = param.type();
CreatorRegistry& registry = Registry();
CHECK_EQ(registry.count(type), 1) << "Unknown solver type: " << type
<< " (known types: " << SolverTypeListString() << ")";
return registry[type](param);
}
其中需要注意的是,SolverParameter是一个配置参数不说,CreatorRegistry就是我们以后自定义层需要知道的,需要知道registry是一个map,存储的就是字符串以及对应的以函数指针形式存储的Creator类型的函数,而注册都会在cpp中进行,以后详解。
common.hpp,是一些与io有关的函数与变量,cpu与gpu模式设定变量Brew
mode_;函数set_mode,setDevice,以及与随机数有关的函数变量shared_ptr
random_generator_;
3 datatransform.hpp
这是很重要的一个文件,当我们自定义数据层的时候会用到,它的作用就是从磁盘中读取数据塞进caffe定义的变量内存中。从它的头文件就可以看出,它依赖于blob,common,以及caffe.pb.h
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/proto/caffe.pb.h"
caffe.pb.h中就包含了序列化的变量。
datatransform.hpp中的变量如下:
shared_ptr rng_;
Phase phase_;
Blob data_mean_;
vector mean_values_;
可见存储了常见的mean_value。
datatransform.hpp中的的核心是重载的transform函数,它可以按照不同的输入来载入数据,我们平常在caffe内部做的随机crop,flip等等操作都在这里完成,具体大家可以去研究源码,静下心看非常简单。
void Transform(const vector
void Transform(const vector
transformed_blob);
void Transform(const cv::Mat& cv_img, Blob
4 filler.hpp
它没有对应的cpp,所有实现都在hpp中,因为很简单,它就是对权重初始化的,其中包含,constantfiller,Gaussianfiller,XavierFiller,MSRAFiller等等,相信大家都比较熟了。
5 solver.hpp
这就是caffe 迭代求解优化的函数定义,其中重要变量loss就在这里,这就是训练caffe时显示出的loss的来源
vector losses_;
Dtype smoothed_loss_;
SolverParameter param_;
迭代优化的函数,
virtual void Solve(const char* resume_file = NULL);
inline void Solve(const string resume_file) { Solve(resume_file.c_str()); }
void Step(int iters);
6 layer.hpp
这就是一个层的定义了,想必大家很有兴趣,那具体都有什么呢?
我们首先看变量,
LayerParameter layer_param_;
vector
然后看重要函数
LayerSetUp,用于layer初始化,一般是定义一些shape,初始化一些变量。
virtual void LayerSetUp(const vector
Forward,Backward的cpu和gpu版本,除了数据层外始终成对存在的前向和反向函数,forward是基于bottom计算top,backward则是基于top计算bottom,很好理解。
virtual void Forward_cpu(const vector
virtual void Forward_gpu(const vector
Fackward_cpu(bottom,top);
}
virtual void Backward_cpu(const vector
const vector& propagate_down, const vector
virtual void Backward_gpu(const vector
Backward_cpu(top, propagate_down, bottom);
}
7 net.hpp
这是最大的一个hpp了,也是最高层的,就是整个网络的定义。
看看重要变量:
vector > shared_ptr
vector
layers_就是所有层,layer_names_;存储了名字,以后在我们inference的时候会需要经常用到。
vector
vector
上面是每一层学习率的参数,在我们想要固定某些层不让其学习,或者调整不同层的学习率时,会非常重要。其实还有很多重要变量如,
vector
Phase phase_;
都是经常接触的,不一一描述了大家自己看代码。
下面是一个重载的重要函数,
void CopyTrainedLayersFrom(const
NetParameter& param);
void CopyTrainedLayersFrom(const string
trained_filename);
void CopyTrainedLayersFromBinaryProto(const string
trained_filename);
void CopyTrainedLayersFromHDF5(const string
trained_filename);
它是重要的初始化网络的方法,可以实现不同形式输入的初始化,在inference时会经常使用的。
好了,基础就这么多,并没有非常细致的讲述而只是对重要内容进行介绍,在开始下面的文章之前,一定要熟读上面的这些hpp和对应cpp文件,对它有什么是什么,熟练于胸。
更多请移步
1,我的gitchat达人课
龙鹏的达人课
2,AI技术公众号,《与有三学AI》
[caffe解读] caffe从数学公式到代码实现2-基础函数类
3,以及摄影号,《有三工作室》
冯小刚说,“他懂我”