
前言
Netty 的解码器有很多种,比如基于长度的,基于分割符的,私有协议的。但是,总体的思路都是一致的。
拆包思路:当数据满足了 解码条件时,将其拆开。放到数组。然后发送到业务 handler 处理。
半包思路: 当读取的数据不够时,先存起来,直到满足解码条件后,放进数组。送到业务 handler 处理。
而实现这个逻辑的就是我们今天的主角:ByteToMessageDecoder。
看名字的意思是:将字节转换成消息的解码器。人如其名。而他本身也是一个入站 handler,所以,我们还是从他的 channelRead 方法入手。
1. channelRead 方法
精简过的代码如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 从对象池中取出一个List
CodecOutputList out = CodecOutputList.newInstance();
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
// 第一次解码
cumulation = data;// 累计
} else {
// 第二次解码,就将 data 向 cumulation 追加,并释放 data
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// 得到追加后的 cumulation 后,调用 decode 方法进行解码
// 解码过程中,调用 fireChannelRead 方法,主要目的是将累积区的内容 decode 到 数组中
callDecode(ctx, cumulation, out);
// 如果累计区没有可读字节了
if (cumulation != null && !cumulation.isReadable()) {
// 将次数归零
numReads = 0;
// 释放累计区
cumulation.release();
// 等待 gc
cumulation = null;
} // 如果超过了 16 次,就压缩累计区,主要是将已经读过的数据丢弃,将 readIndex 归零。
else if (++ numReads >= discardAfterReads) {
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
// 如果没有向数组插入过任何数据
decodeWasNull = !out.insertSinceRecycled();
// 循环数组,向后面的 handler 发送数据,如果数组是空,那不会调用
fireChannelRead(ctx, out, size);
// 将数组中的内容清空,将数组的数组的下标恢复至原来
out.recycle();
}
楼主已经在方法中写了注释,但还是说说主要的步骤:
- 从对象池中取出一个空的数组。
- 判断成员变量是否是第一次使用,(注意,既然使用了成员变量,所以这个 handler 不能是 handler 的。)将 unsafe 中传递来的数据写入到这个 cumulation 累积区中。
- 写到累积区后,调用子类的 decode 方法,尝试将累积区的内容解码,每成功解码一个,就调用后面节点的 channelRead 方法。若没有解码成功,什么都不做。
- 如果累积区没有未读数据了,就释放累积区。
- 如果还有未读数据,且解码超过了 16 次(默认),就对累积区进行压缩。将读取过的数据清空,也就是将 readIndex 设置为0.
- 设置 decodeWasNull 的值,如果上一次没有插入任何数据,这个值就是 ture。该值在 调用 channelReadComplete 方法的时候,会触发 read 方法(不是自动读取的话),尝试从 JDK 的通道中读取数据,并将之前的逻辑重来。主要应该是怕如果什么数据都没有插入,就执行 channelReadComplete 会遗漏数据。
- 调用 fireChannelRead 方法,将数组中的元素发送到后面的 handler 中。
- 将数组清空。并还给对象池。
下面来说说详细的步骤。
2. 从对象池中取出一个空的数组
代码:
@1
CodecOutputList out = CodecOutputList.newInstance();
@2
static CodecOutputList newInstance() {
return CODEC_OUTPUT_LISTS_POOL.get().getOrCreate();
}
@3
private static final FastThreadLocal CODEC_OUTPUT_LISTS_POOL =
new FastThreadLocal() {
@Override
protected CodecOutputLists initialValue() throws Exception {
// 16 CodecOutputList per Thread are cached.
return new CodecOutputLists(16);
}
};
@4
CodecOutputLists(int numElements) {
elements = new CodecOutputList[MathUtil.safeFindNextPositivePowerOfTwo(numElements)];
for (int i = 0; i < elements.length; ++i) {
// Size of 16 should be good enough for the majority of all users as an initial capacity.
elements[i] = new CodecOutputList(this, 16);
}
count = elements.length;
currentIdx = elements.length;
mask = elements.length - 1;
}
@5
private CodecOutputList(CodecOutputListRecycler recycler, int size) {
this.recycler = recycler;
array = new Object[size];
}
@6
public CodecOutputList getOrCreate() {
if (count == 0) {
// Return a new CodecOutputList which will not be cached. We use a size of 4 to keep the overhead
// low.
return new CodecOutputList(NOOP_RECYCLER, 4);
}
--count;
int idx = (currentIdx - 1) & mask;
CodecOutputList list = elements[idx];
currentIdx = idx;
return list;
}
代码分为 1,2,3,4,5, 6 步骤。
- 静态方法调用。
- 从 FastThreadLocal 中取出一个 CodecOutputLists 对象,并从这个集合中再取出一个 List。也就是 List 中有 List。可以理解为双重数组。
- 调用 FastThreadLocal 的 initialValue 方法返回一个 CodecOutputLists 对象。
- 创建数组。数组大小默认16,循环填充 CodecOutputList 元素。设置 count,currentIdx ,mask 属性。
- 创建 CodecOutputList 对象,这个 recycler 就是他的父 CodecOutputLists,并创建一个默认 16 的空数组。
- 首次进入 count 不是0,应该是 16,随后将 count -1,并与运算出 Lists 中的下标,获取到下标的内容。也就是一个 List。在调用 recycle 方法还给对象池的时候,会将所有参数恢复。
由于这个 getOrCreate 方法会被一个线程的多个地方使用,因此 16 是个统计值。当 16 不够的时候,就会创建一个新的 List。也就是 count == 0 的逻辑。而 & mask 的操作就是一个取模的操作。
3. 写入累积区
代码如下:
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
这个 cumulator 默认是个 Cumulator 类型的 MERGE_CUMULATOR,该实例最主要的是从重写了 cumulate 方法:
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
final ByteBuf buffer;
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
buffer.writeBytes(in);
in.release();
return buffer;
}
};
可以看到该方法,主要是将 unsafe.read 传递过来的 ByteBuf 的内容写入到 cumulation 累积区中,然后释放掉旧的内容,由于这个变量是成员变量,因此可以多次调用 channelRead 方法写入。
同时这个方法也考虑到了扩容的问题,总的来说就是 copy。
当然,ByteToMessageDecoder 中还有一个 Cumulator 实例,称之为 COMPOSITE_CUMULATOR,混合累积。由于上个实例的 cumulate 方法是使用内存拷贝的,因此,这里提供了使用混合内存。相较于拷贝,性能会更好点,但同时也会更复杂。
4. decode 方法的作用
当数据追击到累积区之后,需要调用 decode 方法进行解码,代码如下:
@ 1
callDecode(ctx, cumulation, out);
@2
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List该方法主要逻辑:只要累积区还有未读数据,就循环进行读取。
调用 decodeRemovalReentryProtection 方法,内部调用了子类重写的 decode 方法,很明显,这里是个模板模式。decode 方法的逻辑就是将累积区的内容按照约定进行解码,如果成功解码,就添加到数组中。同时该方法也会检查该 handler 的状态,如果被移除出 pipeline 了,就将累积区的内容直接刷新到后面的 handler 中。
如果 Context 节点被移除了,直接结束循环。如果解码前的数组大小和解码后的数组大小相等,且累积区的可读字节数没有变化,说明此次读取什么都没做,就直接结束。如果字节数变化了,说明虽然数组没有增加,但确实在读取字节,就再继续读取。
如果上面的判断过了,说明数组读到数据了,但如果累积区的 readIndex 没有变化,则抛出异常,说明没有读取数据,但数组却增加了,子类的操作是不对的。
如果是个单次解码器,解码一次就直接结束了。
所以,这段代码的关键就是子类需要重写 decode 方法,将累积区的数据正确的解码并添加到数组中。每添加一次成功,就会调用 fireChannelRead 方法,将数组中的数据传递给后面的 handler。完成之后将数组的 size 设置为 0.
所以,如果你的业务 handler 在这个地方可能会被多次调用。也可能一次也不调用。取决于数组中的值。当然,如果解码 handler 被移除了,就会将累积区的所有数据刷到后面的 handler。
5. 剩下的逻辑
上面的逻辑就是解码器最主要的逻辑:
将 read 方法的数据读取到累积区,使用解码器解码累积区的数据,解码成功一个就放入到一个数组中,并将数组中的数据一次次的传递到后面的handler。
从上面的逻辑看,除非 handler 被移除,否则不会调用后面的 handler 方法,也就是说,只要不满足解码器的解码规则,就不会传递给后面的 handler。
再看看后面的逻辑,主要在 finally 块中:
- 如果累积区没有可读数据了,将计数器归零,并释放累积区。
- 如果不满足上面的条件,且计数器超过了 16 次,就压缩累积区的内容,压缩手段是删除已读的数据。将 readIndex 置为 0。还记得 ByteBuf 的指针结构吗?
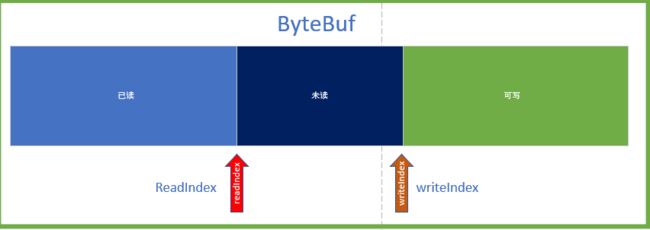
这样就能节省一些内存了,但这会引起一些内存复制的过程,以性能损耗为前提的。
- 记录 decodeWasNull 属性,这个值的决定来自于你有没有成功的向数组中插入数据,如果插入了,它就是 fasle,没有插入,他就是 true。这个值的作用在于,当 channelRead 方法结束的时候,执行该 decoder 的 channelReadComplete 方法(如果你没有重写的话),会判断这个值:

如果是 true,则会判断 autoRead 属性,如果是 false 的话,那么 Netty 认为还有数据没有读到,不然数组为什么一直是空的?就主动调用 read 方法从 Socket 读取。
- 调用 fireChannelRead 方法,尝试将数组中的数据发送到后面的 handler。为什么要这么做。按道理,到这一步的时候,数组不可能是空,为什么这里还要这么谨慎的再发送一次?
答:如果是单次解码器,就需要发送了,因此单词解码器是不会再 callDecode 方法中发送的。
- 最后,将数组还给对象池。并清空数组内容。
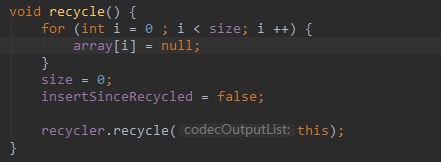
最后一行的 recycler.recycle(this),有两种结果,如果是 CodecOutputLists 的 recycle 方法,内容如下:
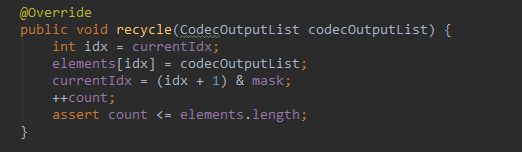
恢复数组下标,对 count ++,表示有对象可用了。
还有第二种,当 16 个数组不够用了,就需要创建一个新的,在 getOrCreate 方法体现。而构造函数中的 recycler 是一个空对象。我们看看这个对象:

当调用 recycle 方法的时候,什么都不做。等待 GC 回收。因为这不是个对象池的引用。
好,到这里,关于 ByteToMessageDecoder 解码器的主要功能就解读完了。
5. 总结
可以说,ByteToMessageDecoder 是解码器的核心所做,Netty 在这里使用了模板模式,留给子类扩展的方法就是 decode 方法。
主要逻辑就是将所有的数据全部放入累积区,子类从累积区取出数据进行解码后放入到一个 数组中,ByteToMessageDecoder 会循环数组调用后面的 handler 方法,将数据一帧帧的发送到业务 handler 。完成这个的解码逻辑。
使用这种方式,无论是粘包还是拆包,都可以完美的实现。
还有一些小细节:
- 比如解码器可以单次的。
- 如果解码一直不成功,那么数据就一直无法到达后面的 handler。除非该解码器从 pipeline 移除。
- 像其他的 Netty 模块一样,这里也使用了对象池的概念,数组存放在线程安全的 ThreadLocal 中,默认 16 个,当不够时,就创建新的,用完即被 GC 回收。
- 当数组从未成功添加数据,且程序没有开启 autoRead ,就主动调用 read 方法。尝试读取数据。
Netty 所有的解码器,都可以在此类上扩展,一切取决于 decode 的实现。只要遵守 ByteToMessageDecoder 的约定即可。
good luck!!!!