1.1 Druid 是什么
Druid 单词来源于西方古罗马的神话人物,中文常常翻译成德鲁伊。传说Druid 教士精通占卜,对祭祀礼仪一丝不苟,也擅长于天文历法、医药、天文和文学等。同时,Druid 也是执法者、吟游诗人和探险家的代名词。在著名游戏《暗黑破坏神》中,Druid 也是一个非常有战斗力的人物,法术出色。
本书介绍的Druid 是一个分布式的支持实时分析的数据存储系统(Data Store)。美国广告技术公司MetaMarkets 于2011 年创建了Druid 项目,并且于2012 年晚期开源了Druid 项目。Druid 设计之初的想法就是为分析而生,它在处理数据的规模、数据处理的实时性方面,比传统的OLAP 系统有了显著的性能改进,而且拥抱主流的开源生态,包括Hadoop 等。多年以来,Druid 一直是非常活跃的开源项目。
Druid 的官方网站是http://druid.io。
另外,阿里巴巴也曾创建过一个开源项目叫作Druid(简称阿里Druid),它是一个数据库连接池的项目。阿里Druid 和本书讨论的Druid 没有任何关系,它们解决完全不同的问题。
1.2 大数据分析和Druid
大数据一直是近年的热点话题,随着数据量的急速增长,数据处理的规模也从GB 级别增长到TB 级别,很多图像应用领域已经开始处理PB 级别的数据分析。大数据的核心目标是提升业务的竞争力,找到一些可以采取行动的洞察(Actionable Insight),数据分析就是其中的核心技术,包括数据收集、处理、建模和分析,最后找到改进业务的方案。
最近一两年,随着大数据分析需求的爆炸性增长,很多公司都经历过将以关系型商用数据库为基础的数据平台,转移到一些开源生态的大数据平台,例如Hadoop 或Spark 平台,以
可控的软硬件成本处理更大的数据量。Hadoop 设计之初就是为了批量处理大数据,但数据处理实时性经常是它的弱点。例如,很多时候一个MapReduce 脚本的执行,很难估计需要多
长时间才能完成,无法满足很多数据分析师所期望的秒级返回查询结果的分析需求。
为了解决数据实时性的问题,大部分公司都有一个经历,将数据分析变成更加实时的可交互方案。其中,涉及新软件的引入、数据流的改进等。数据分析的几种常见方法如图1-1所示。
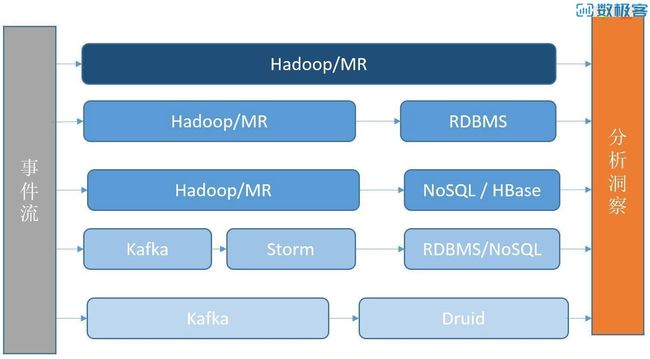
图1-1 数据分析的几种常见方法
整个数据分析的基础架构通常分为以下几类。
(1)使用Hadoop/Spark 的MR 分析。
(2)将Hadoop/Spark 的结果注入RDBMS 中提供实时分析。
(3)将结果注入到容量更大的NoSQL 中,例如HBase 等。
(4)将数据源进行流式处理,对接流式计算框架,如Storm,结果落在RDBMS/NoSQL 中。
(5)将数据源进行流式处理,对接分析数据库,例如Druid、Vertica 等。
1.3 Druid 的产生
1.3.1 MetaMarkets 简介
Druid 诞生于MetaMarkets 公司,简单介绍这家公司有助于更好地理解Druid 创建的背景。这家公司致力于为在线媒体公司提供数据分析服务,客户包括在线广告公司、在线游戏开发商和社交媒体等。目前,互联网广告越来越多地采用程序化交易的方式,因此广告交易数据量大大增多,数据分析需求和场景也非常多。MetaMarkets 在这方面经验丰富,帮助广告交易平台(Ad Exchange)、供应方平台(Supply Side Platform)和需求方平台(Demand Side?Platform)提供深度的数据分析服务。
广告程序化交易通常采用iAB(Interactive Advertising Bureau)的OpenRTB 标准,因此MetaMarkets 的服务能力很容易扩展到多家广告公司。根据MetaMarkets 数据,它们的数据分析平台的请求事件的峰值超过3 百万/秒。另外,广告分析对于实时查询的性能要求非常高,Druid 就是MetaMarkets 的核心数据处理平台,能够保证99% 的数据查询在1 秒内返回结果。
在广告程序化交易模式下,广告流量将会发送到多个广告平台(Ad Network)或DSP,DSP需要根据数据和算法决定对广告流量进行出价。在整个过程中,数据处理和分析能力就是广告平台的核心竞争力。
在这个业务背景下,MetaMarkets 的工程师在早期的数据分析平台的设计上,经过两个阶段的努力后,最终决定自主开发Druid 系统来满足业务需求。
第一阶段,基于RDBMS 的查询分析。
MetaMarkets 最开始使用了GreenPlum 社区版数据库,分析系统运行在亚马逊的云服务器上,机型为M1.Large.EC2 Box 。采用这种方式后,发现以下两个明显的问题。
很多全表扫描操作响应特别慢。例如,对于一个3300 万的数据,计算总行数需要3 秒时间。
所有列的处理方式相同。这意味着时间、维度、指标不做任何区分。因此在使用这些数据的时候,需要管理哪些是维度列,哪些是指标列。
对于第二个问题,可能只是增加了少量的系统管理成本,但是第一个问题对于分析平台确实是致命的。开发人员不得不通过一些预先计算(Pre-Caculate)或者缓存(Cache)机制,提高系统的使用性能。为了解决第一个问题,开发人员也尝试优化数据库的性能,或采用其他的数据库,例如MySQL、InfoBright 和PostgresSQL,但是情况并没有任何明显改善。
第二阶段,预计算结果放入NoSQL 中。
经过第一阶段的尝试,开发人员得出一个结论:常规的关系型数据库管理系统(RDBMS)并不能满足实时大规模数据分析的性能需求。因此,他们在第二阶段的工作中,将NoSQL 作为数据落地时的存储,利用NoSQL 的高性能、可扩展特性解决数据分析的实时问题。开发人员借鉴了Twitter 的RainBIrd 类似的设计,开发了一套高性能的计数服务系统。RainBIrd 是一款基于Zookeeper、Cassandra、Scribe 和?ri? 等技术的分布式实时统计系统,用于高性能的计数,支持获取最大值、最小值和平均值等功能,其中Cassandra 用于存储数据内容。
MetaMarkets 也采用类似的理念设计了一套系统,该系统将所需要分析的指标,通过计数器的方法预先计算出来,并且放在NoSQL 中,为数据分析提供实时能力。这种方法在维度比较少的时候,计算量不大,将数据放在NoSQL 中,访问速度很快。但是,随着维度的增加,预计算的计算量越来越大,当维度达到11 个时,计算时间甚至超过了24 小时。在后面的性能优化过程中,开发人员不得不限制预计算的维度,例如规定不能超过5 个维度,只预先计算最重要的维度。但是,随着业务的发展,维度还在不断继续增加,计算量再次成为瓶颈。在最后的项目反思会中,大家都明确体会到这种方案的局限性,意识到当时做的决定是错误的。总结了这次失败的本质:RainBIrd 这一类的高性能的计数器设计,并不适合通用数据分析的需求,特别是不能支持从不同角度或维度进行灵活的数据分析。
1.3.2 失败总结
在经历两次深刻的失败后,MetaMarkets 决定创建一个分布式的内存OLAP 系统,用于解决以下两个核心问题。
RDBMS 的查询太慢。
支持灵活的查询分析能力。
就这样,Druid 项目诞生了。
1.4 Druid 的三个设计原则
在设计之初,开发人员确定了三个设计原则(Design Principle)。
(1)快速查询(Fast Query):部分数据的聚合(Partial Aggregate)+内存化(In-Memory)+索引(Index)。
(2)水平扩展能力(Horizontal ScalaBIlity):分布式数据(Distributed Data)+ 并行化查询(Parallelizable Query)。
(3)实时分析(Realtime Analytics):不可变的过去,只追加的未来(Immutable Past,Append-Only Future)。
1.4.1 快速查询(Fast Query)
对于数据分析场景,大部分情况下,我们只关心一定粒度聚合的数据,而非每一行原始数据的细节情况。因此,数据聚合粒度可以是1 分钟、5 分钟、1 小时或1 天等。部分数据聚合(Partial Aggregate)给Druid 争取了很大的性能优化空间。数据内存化也是提高查询速度的杀手锏。内存和硬盘的访问速度相差近百倍,但内存的大小是非常有限的,因此在内存使用方面要精细设计,比如Druid 里面使用了BItmap 和各种压缩技术。
另外,为了支持Drill-Down 某些维度,Druid 维护了一些倒排索引。这种方式可以加快AND 和OR 等计算操作。
1.4.2 水平扩展能力(Horizontal ScalaBIlity)
Druid 查询性能在很大程度上依赖于内存的优化使用。数据可以分布在多个节点的内存中,因此当数据增长的时候,可以通过简单增加机器的方式进行扩容。为了保持平衡,Druid按照时间范围把聚合数据进行分区处理。对于高基数的维度,只按照时间切分有时候是不够的(Druid 的每个Segment 不超过2000 万行),故Druid 还支持对Segment 进一步分区。
历史Segment 数据可以保存在深度存储系统中,存储系统可以是本地磁盘、HDFS 或远程的云服务。如果某些节点出现故障,则可借助Zookeeper 协调其他节点重新构造数据。
Druid 的查询模块能够感知和处理集群的状态变化,查询总是在有效的集群架构中进行。集群上的查询可以进行灵活的水平扩展。Druid 内置提供了一些容易并行化的聚合操作,例如Count、Mean、Variance 和其他查询统计。对于一些无法并行化的操作,例如Median,Druid暂时不提供支持。在支持直方图(Histogram)方面,Druid 也是通过一些近似计算的方法进行支持,以保证Druid 整体的查询性能,这些近似计算方法还包括HyperLoglog、DataSketches的一些基数计算。
1.4.3 实时分析(Realtime Analytics)
Druid 提供了包含基于时间维度数据的存储服务,并且任何一行数据都是历史真实发生的事件,因此在设计之初就约定事件一但进入系统,就不能再改变。
对于历史数据Druid 以Segment 数据文件的方式组织,并且将它们存储到深度存储系统中,例如文件系统或亚马逊的S3 等。当需要查询这些数据的时候,Druid 再从深度存储系统中将它们装载到内存供查询使用。
1.5 Druid 的技术特点
Druid 具有如下技术特点。
数据吞吐量大。
支持流式数据摄入和实时。
查询灵活且快。
社区支持力度大。
1.5.1 数据吞吐量大
很多公司选择Druid 作为分析平台,都是看中Druid 的数据吞吐能力。每天处理几十亿到几百亿的事件,对于Druid 来说是非常适合的场景,目前已被大量互联网公司实践。因此,很多公司选型Druid 是为了解决数据爆炸的问题。
1.5.2 支持流式数据摄入
很多数据分析软件在吞吐量和流式能力上做了很多平衡,比如Hadoop 更加青睐批量处理,而Storm 则是一个流式计算平台,真正在分析平台层面上直接对接各种流式数据源的系统并不多。
1.5.3 查询灵活且快
数据分析师的想法经常是天马行空,希望从不同的角度去分析数据,为了解决这个问题,OLAP 的Star Schema 实际上就定义了一个很好的空间,让数据分析师自由探索数据。数据量小的时候,一切安好,但是数据量变大后,不能秒级返回结果的分析系统都是被诟病的对象。因此,Druid 支持在任何维度组合上进行查询,访问速度极快,成为分析平台最重要的两个杀手锏。
1.5.4 社区支持力度大
Druid 开源后,受到不少互联网公司的青睐,包括雅虎、eBay、阿里巴巴等,其中雅虎的Committer 有5 个,谷歌有1 个,阿里巴巴有1 个。最近,MetaMarkets 之前几个Druid 发明人也成立了一家叫作Imply.io 的新公司,推动Druid 生态的发展,致力于Druid 的繁荣和应用。接下来,我们一起来看看Druid 的Hello World 吧。
1.6 Druid 的Hello World
1.6.1 Druid 的部署环境
Druid 系统用Java 编写,目前支持JDK 7 及以上版本。目前Druid 论坛已经在开始讨论不再支持Java 7,大部分公司都正在使用Java 8 版本,旧版本的Java 也在升级中,建议直接使用Java 8 版本安装Druid。在操作系统方面,支持主流Linux 和Mac OS,不支持Windows 操作系统。内存配置越大越好,建议8GB 以上。如果只用测试功能,4GB 内存也可运行。
1.6.2 Druid 的基本概念
1. 数据格式
Druid 在数据摄入之前,首先需要定义一个数据源(DataSource),这个DataSource 有些类似数据库中表的概念。每个数据集合包括三个部分:时间列(TimeStamp)、维度列(Dimension)和指标列(Metric)。
(1)时间列
每个数据集合都必须有时间列,这个列是数据聚合的重要维度,Druid 会将时间很近的一些数据行聚合在一起。另外,所有的查询都需要指定查询时间范围。
(2)维度列
维度来自于OLAP 的概念,用来标识一些事件(Event),这些标识主要用于过滤或者切片数据,维度列的字段为字符串类型。例如,对于一次广告展现,我们可以将“哪个广告”、“哪个广告位置”、“计费的类型”、“广告主的类型”等作为广告展现的描述信息。随着业务分析的精细化,增加维度列也是一个常见的需求。
(3)指标列
指标对应于OLAP 概念中的Fact,即用于聚合和计算的列。指标列字段通常为数值类型,计算操作通常包括Count、Sum 和Mean 等。指标通常是业务的关键量化指标,包括收入、使用时长等核心可度量和比较的指标。数据格式样例如图1-2 所示。
need-to-insert-img
need-to-insert-img

图1-2 数据格式样例
2. 数据摄入
Druid 提供两种数据摄入方式,如图1-3 所示,其中一种是实时数据摄入;另一种是批处理数据摄入。
need-to-insert-img
need-to-insert-img

图1-3 两种数据摄入方式
3. 数据查询
在数据查询方面,Druid 原生查询是采用JSON 格式,通过HTTP 传送。Druid 不支持标准的SQL 语言查询,因为有些SQL 语言查询并不适用于Druid 现在的设计。为了简化查询的解析,采用自己定义的JSON 格式,方便内外部处理。随着Druid 应用越来越广泛,支持标准SQL 的需求变得越来越重要,一些开源生态项目正在向这个方面努力,例如Imply.io 的PlyQL 等。
对于Druid 的查询访问,除了原生Java 客户端支持外,也出现了很多支持不同语言客户端访问的开源项目,例如Python、R、JavaScript 和Ruby 等。
下面是一个用JSON 表达的查询例子,该查询中指定了时间范围、聚合粒度、数据源等。
{
“queryType”: “timeseries”,
“dataSource”: “sample_datasource”,
“granularity”: “day”,
“aggregations”: [
{ “type”: “longSum”, “name”: “result_name”, “fieldName”: “field_name” }
],
“intervals”: [“2012-01-01T00:00:00.000/2012-01-04T00:00:00.000”],
“context” : {“skipEmptyBuckets”: “true”}
}
1.7 系统的扩展性
Druid 是一个分布式系统,采用Lambda 架构,将实时数据和批处理数据合理地解耦。实时数据处理部分是面向写多读少的优化,批处理部分是面向读多写少的优化。整个分布式系统采用Shared nothing 的结构,各个节点都有自己的计算和存储能力。整个系统使用Zookeeper 进行协调,另外还使用了MySQL 提供一些元数据的存储。
在雅虎,已经验证过数百台Druid 集群的规模。国内的阿里巴巴、小米、优酷等公司也有大规模部署Druid 的成功经验。
MetaMarkets 曾经介绍过它的一些扩展能力的数据。
每天1000 亿的事件
每秒超过300 万的事件
超过100PB 的原始数据
超过50000 亿的总数据
上千用户的每秒查询峰值
数万个处理器核
1.8 性能指标
性能测试涉及太多的因素,包括测试数据源、访问模式、机器配置和部署等,因此很难有统一的业界标准。在参考资料中,提到了根据TPC-H 标准数据集的性能评测结果。由于Druid 不能支持所有的查询,所以测试只覆盖了支持的查询场景。对于1GB 的数据和100GB 的数据,从查询性能来看,Druid 基本完胜MySQL,查询时间缩小了5~10 倍。随着数据量的增大,这种性能改善的程度会越来越大。
100GB 规模的Druid 测试数据,从测试结果来看,性能提升也是非常明显的。
need-to-insert-img
1.9 Druid 的应用场景
从技术定位上看,Druid 是一个分布式的数据分析平台,在功能上也非常像传统的OLAP系统,但是在实现方式上做了很多聚焦和取舍,为了支持更大的数据量、更灵活的分布式部署、更实时的数据摄入,Druid 舍去了OLAP 查询中比较复杂的操作,例如JOIN 等。相比传统数据库,Druid 是一种时序数据库,按照一定的时间粒度对数据进行聚合,以加快分析查询。
在应用场景上,Druid 从广告数据分析平台起家,已经广泛应用在各个行业和很多互联网公司中,下面将介绍一些使用Druid 的公司,最新列表可以访问http://druid.io/druidpowered.html。
1.9.1 国内公司
1. 腾讯
腾讯是一家著名的社交互联网公司,其明星产品如QQ、微信有着上亿级别庞大的用户量。在2B 业务领域,作为中国领先的SaaS 级社会化客户关系管理平台,腾讯企点采用了Druid 用于分析大量的用户行为,帮助提升客户价值。
2. 阿里巴巴
阿里巴巴是世界领先的电子商务公司。阿里搜索组使用Druid 的实时分析功能来获取用户的交互行为。
3. 新浪微博
新浪微博是中国领先的社交平台。新浪微博的广告团队使用Druid 构建数据洞察系统的实时分析部分,每天处理数十亿的消息。
4. 小米
小米是中国领先的专注智能产品和服务的移动互联网公司。Druid 用于小米统计的部分后台数据收集和分析;另外,在广告平台的数据分析方面,Druid 也提供了实时的内部分析功能,支持细粒度的多维度查询。
5. 滴滴打车
滴滴打车是世界领先的交通平台。Druid 是滴滴实时大数据处理的核心模块,用于滴滴的实时监控系统,支持数百个关键业务指标。通过Druid,滴滴能够快速得到各种实时的数据洞察。
6. 优酷土豆
优酷土豆是中国领先的互联网视频公司,Druid 用于其广告平台的数据处理和分析。
7.数极客
数极客是中国领先的大数据用户行为分析产品服务商,Druid应用于实时的用户行为数据分析,目前数极客运营的SAAS平台达到每日百亿级数据量,给客户私有化部署的版本,单个客户也达到数十亿数据量级别,通过Druid,数极客实现了亿级数据秒级响应分析。
8. 蓝海讯通(OneAPM)
蓝海讯通是中国领先的应用性能管理(APM)的技术服务公司。Druid 用于实时的应用监测数据收集,并且提供给用户灵活的查询功能。
1.9.2 国外公司
1. 雅虎(Yahoo!)
雅虎是全球领先的互联网公司,它也是最早一批深度使用Druid 的公司。雅虎曾经维护着世界上最大的Hadoop 集群,但是Hadoop 集群无法处理实时交互查询,无法支持实时数据摄入,无法灵活支持每日几百亿的事件。在尝试很多工具之后,最后他们还是深度拥抱了Druid。
Druid 用于数据收集,为管理层提供仪表盘,为客户提供实时的数据查询功能。另外,雅虎也深度参与这个项目的开发当中,不少Committer 都来自雅虎公司,雅虎也在和社区紧密合作推动Druid 的发展。
2. PayPal
PayPal 是世界领先的互联网支付公司。2014 年年初,PayPal 的Tracking Platform 组采用了Druid 处理每天70~100 亿条的记录数据,查询的响应时间非常理想。如今Druid 在PayPal已经有一个非常大的集群,为业务分析组提供了各种各样的数据分析支持。
3. eBay
eBay 是互联网电子商务的领先公司。eBay 使用Druid 聚合多个数据源,用于用户行为分析,数据量超过10 万消息/秒。同时在查询方面,Druid 提供了一个自由组合的条件查询功能,支持商业分析的场景。另外,eBay 的云平台组也在2016 年2 月开源了一个embedded-druid项目,针对单机JVM 进程提供嵌入式的Druid 解决方案,它不涉及复杂节点的部署,单节点,高性能。
4. Hulu
Hulu 是美国领先的互联网视频公司。Hulu 使用Druid 构建数据分析平台,进行实时的用户行为和应用数据分析。
5. 思科(Cisco)
思科是世界领先的通信技术公司之一,使用Druid 对网络数据流进行实时的数据分析。此外,还有很多使用Druid 的公司,广告公司还包括Criteo、LDMoBIle、MetaMarkets、PubNative、VideoAmp 和GumGum 等,数据分析公司还包括Optimizely、Monetate、AppsFlyer和Archive-it.org 等,其他公司还包括AirBnb、DripStat 等。
总结这些公司的使用场景,Druid 确实提供了一个相对通用的数据分析平台,起源于广告数据分析,但广泛应用于用户行为分析、网络数据分析等领域。不仅仅有互联网公司在使用,也有很多老牌公司在使用,例如Cisco、SK Telecom 等。大部分公司都看中了Druid 的大数据量处理能力、数据实时性和秒级数据查询功能。
1.10 小结
Druid 从出生到繁荣,很单纯和专注地解决了大规模数据的分析问题,实时性是它的特色之一。
在Hadoop 和Spark 大生态繁荣圈中,Druid 能获得众多公司的青睐,异军突起,总结起来有三个原因。
第一,Druid 不断拥抱各种主流开源生态,例如Hadoop、Spark 等。
第二,围绕着Druid,已经开始出现一些项目,完善了Druid 的生态系统,其中包括数据的摄入、客户端的访问、数据查询的便利和数据的可视化等。
第三,出现了专业的Druid 技术服务公司,例如Imply.io 等,帮助企业客户更好地认识Druid,使用和优化Druid,以解决客户的数据分析需求。
我们非常高兴看到最近几年Druid 获得的长足快速发展,并且解决了很多公司在业务上的数据分析痛点。在技术上Druid 采用分布式、Shared nothing 结构,提供了实时和离线批量数据摄入的能力,通过数据的预聚合、优化存储结构和内存使用,保证了在查询分析方面的高效率。在应用场景上Druid 满足了OLAP 的核心功能,在社区推广方面Druid 也同样值得称赞。
参考资料
Druid 主页:http://druid.io
Druid 应用公司列表:http://druid.io/druid-powered.html
Druid 的技术论文:http://static.druid.io/docs/druid.pdf
——本文摘自《Druid实时大数据分析原理与实践》(腾讯、小米、优酷等互联网公司的一线实践经验,为你解读海量实时OLAP平台!)

编辑推荐
精通实时大数据分析!
内容提要
Druid 作为一款开源的实时大数据分析软件,最近几年快速风靡全球互联网公司,特别是对于海量数据和实时性要求高的场景,包括广告数据分析、用户行为分析、数据统计分析、运维监控分析等,在腾讯、阿里、优酷、小米等公司都有大量成功应用的案例。《Druid实时大数据分析原理与实践》的目的就是帮助技术人员更好地深入理解Druid 技术、大数据分析技术选型、Druid 的安装和使用、高级特性的使用,也包括一些源代码的解析,以及一些常见问题的快速回答。
Druid 的生态系统正在不断扩大和成熟,Druid 也正在解决越来越多的业务场景。希望本书能帮助技术人员做出更好的技术选型,深度了解Druid 的功能和原理,更好地解决大数据分析问题。《Druid实时大数据分析原理与实践》适合大数据分析的从业人员、IT 人员、互联网从业者阅读。