
有句话是这么说的:
It's not who has the best algorithm that wins.
It's who has the most data.
数据对于机器学习来说,其重要性毋容置疑。
随着数据量的增加,算法预测的精准度也会有所增加:
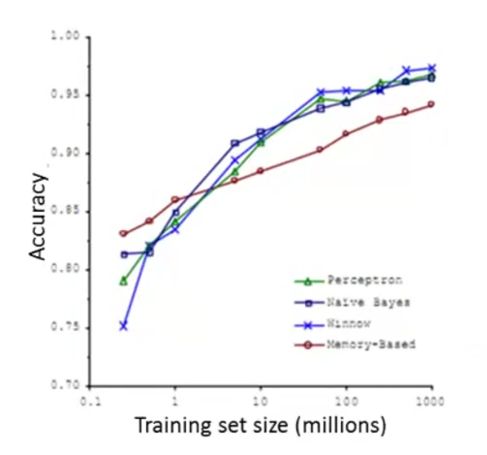
不过大量的数据,会带来一个直接的问题,那就是与之相匹配的运算量。
当我们的训练集非常大时,之前介绍的梯度下降算法,就因为巨大的运算量而显得不太好用。
怎么办呢?下面来说说几种解决的方式。
1 随机梯度下降(Stochastic Gradient Descent)
首先我们回顾一下梯度下降算法。
预测函数:
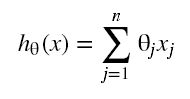
代价函数:
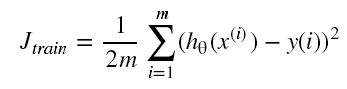
梯度下降算法需要同步执行的步骤:
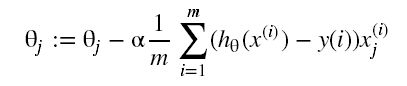
随机梯度下降和这不一样的地方在于,梯度计算时不需要对所有的 m 个训练样本求和,每次只处理一个样本。
这样就不会因为训练样本数过大,而运行缓慢。
其代价函数为:
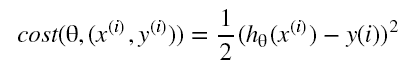
需要同步执行的步骤为:

因为每次只处理一个样本,为了避免样本顺序的影响,在计算之前先随机打乱样本顺序。
计算完一个样本然后在计算下一个,如此反复,直到所有样本都计算完毕。
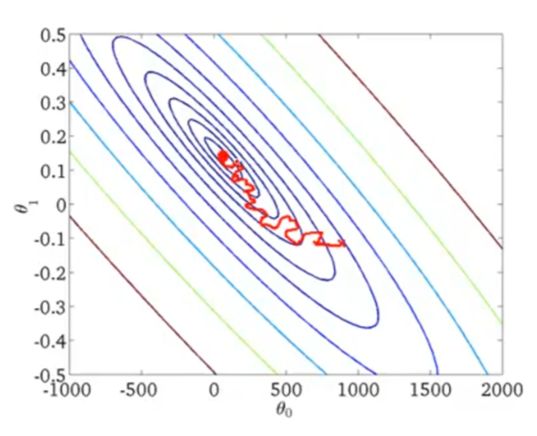
如果说梯度下降算法的收敛是这样一条相对平滑的弧线:

那么随机梯度下降算法的收敛过程就显得非常曲折:

并且曲线最终没有收敛到一个点,而是一个区域。
如果每 1000 次迭代,绘画最近 1000 个样本的代价函数平均值,就是下面几个图中的蓝线。
情况一:趋势向下
其中红线的学习速率 α 比蓝线的更小,我们可以看到其收敛的速度更慢。
虽然两者最终的结果有所差异,不过差异非常小。
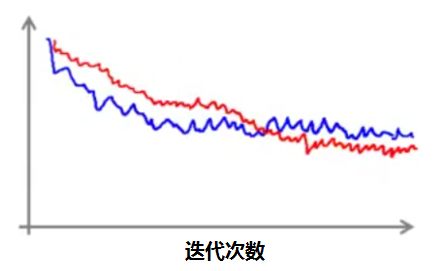
如果将迭代次数从1000 变成 5000,得到的曲线会比原来更加平滑:
不过缺点就是每 5000 个样本才得到一个数据点,因此这个曲线给出的反馈是相对延迟的。
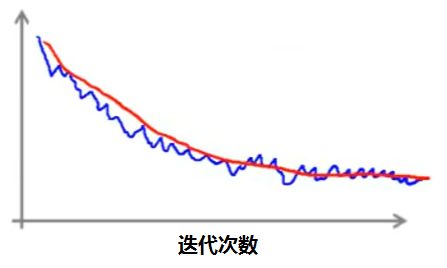
情况二:上下波动
如果出现上面这样的情况,我们将迭代的次数增加到 5000 次,可能会得到两种不同的曲线。
如果得到的是红线,说明算法其实有在收敛,只是速度比较慢。
如果是得到上图中的粉线,说明算法其实没有起到什么作用。
这时候我们应该尝试一些改变,例如调整学习速率,改变特征变量等等。
情况三:趋势向上
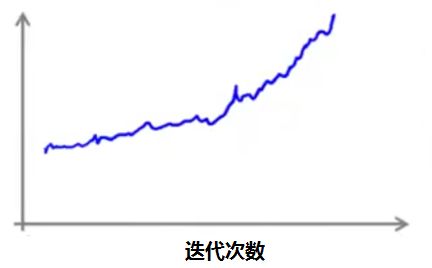
这说明算法产生了背离, α 过大了,此时应该缩小 α 。
其实对于学习速率 α 的选择,也可以动态的进行:

通过这样的方式,随着迭代次数的增加, α 会越来越小,最终会收敛到较小的范围:
不过这样也产生了一个新的麻烦,那就是多了一个参数 C 需要调试。
2 小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降算法,是介于批量梯度下降算法和随机梯度下降算法之间的。
如果说批量梯度下降算法每次迭代使用的是全样本 m ,随机梯度下降算法每次迭代使用的是 1 个样本,那么小批量梯度下降算法每次迭代使用的 b 个样本,其中 1 < b < m 。
其梯度计算的公式是:
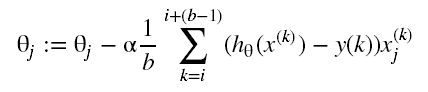
b 一般设置在 2 到 100 之间。
假如 m = 1000,设置 b = 10 ,也就是:

其中 i = 1, 11, 21, 31, … , 991 。
和随机梯度下降相比,每次处理 b 个样本的优势在于向量化处理。
当你有较好的向量化实现时,小批量梯度下降能够并行计算,使用更短的时间得到结果。
当然小批量梯度下降也有一个缺点,那就是多了一个额外的参数 b 需要调试。
3 在线学习(Online Learning)
在线学习算法的机制,和随机梯度下降算法差异不大,唯一的区别就是放弃了一个固定的数据集,通过不断获取新样本来训练学习。
训练完成之后,这个样本就被丢弃,之后也再也不会用到了。
我们举一个例子,假设在一个大型网站中,用户不断搜索手机信息,并点击浏览。
网站会不断收集用户搜索的关键字和点击的结果。如果用户点击了,就标记为 1 ,否则就标记为 0 。
那么用户每一次的搜索和点击,都会构成一个训练样本。
从本质上来说,这样的数据是无限,所以没有必要重复处理同一个样本。
当然,如果只有少量的用户,在数据非常少的时候,将数据保存在一个固定的数据集中才有意义。
通过在线学习的方式,每一个新的数据,都会给算法的学习结果带来调整。
对于用户偏好的变化,可以很好的适应。
4 映射约减(Map Reduce)
映射约减 (map reduce) 大规模机器学习常用到的一种方法。
其主要的过程是将训练集拆分成多个部分,然后分别交给不同的计算机进行计算,最终汇总结果:
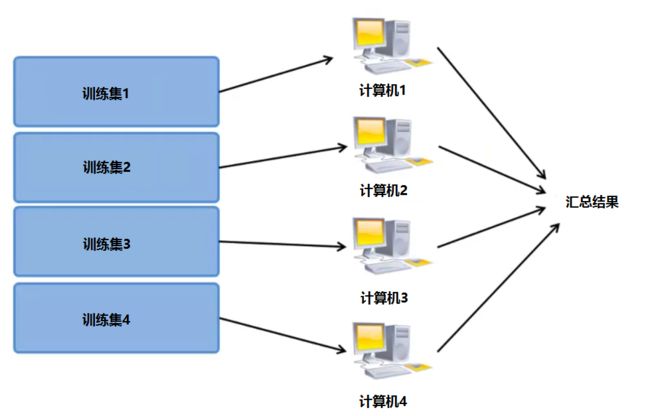
假如训练集数量 m = 400 ,把训练集拆分成 4 份:
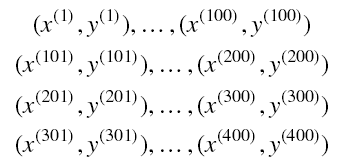
然后传到不同的计算机分别计算:

最终进行汇总:
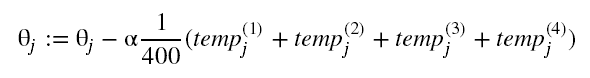
其结果和直接计算是一样的:
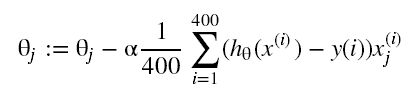
通过这样的方式,可以将计算变成并行,大大提高计算速度,降低运算时间。
理论上我们可以得到 4 倍的加速时间,不过考虑网络延时,以及数据汇总的额外消耗,得到的加速时间总是小于 4 倍的。
还有一种方式就多核处理。
现在很多计算机都是多核的,例如我们有一台 4 核计算机,就可以将训练样本分成 4 份,让每一个核处理其中一份:
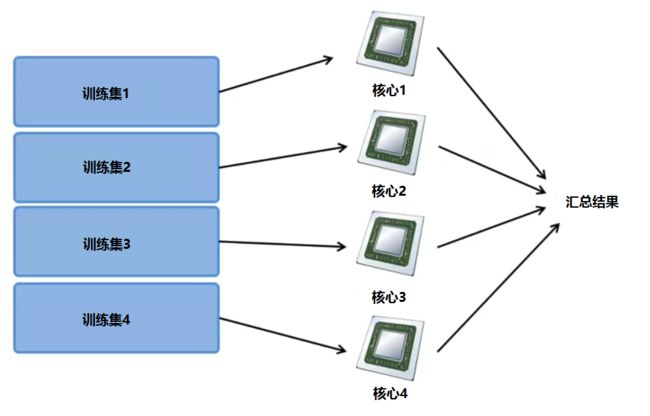
这样,相比使用多台计算机并行计算,就不用担心网络延时的影响。
5 注意
有时候并不是数据越多越好。
如果是高偏差的问题,使用大量的数据,算法效果也不会得到改善:

所以在上大数据之前,应该先使用其中的一部分数据对算法进行验证。
文章转载自公众号:止一之路
