写在前面:
这是我见过的最严肃的数据集,几乎每一行数据背后都是生命和鲜血的代价。这次探索分析并不妄图说明什么,仅仅是对数据处理能力的锻炼。因此本次的探索分析只会展示数据该有的样子而不会进行太多的评价。有一句话叫“因为珍爱和平,我们回首战争”。这里也是,因为珍爱生命,所以回首空难。现在安全的飞行是10万多无辜的人通过性命换来的,向这些伟大的探索者致敬。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
导入数据集
crash = pd.read_csv("./Airplane_Crashes_and_Fatalities_Since_1908.csv")
crash.info()
RangeIndex: 5268 entries, 0 to 5267
Data columns (total 13 columns):
Date 5268 non-null object
Time 3049 non-null object
Location 5248 non-null object
Operator 5250 non-null object
Flight # 1069 non-null object
Route 3562 non-null object
Type 5241 non-null object
Registration 4933 non-null object
cn/In 4040 non-null object
Aboard 5246 non-null float64
Fatalities 5256 non-null float64
Ground 5246 non-null float64
Summary 4878 non-null object
dtypes: float64(3), object(10)
memory usage: 535.1+ KB
crash = crash.drop(["Summary","cn/In","Flight #","Route","Location"],axis=1)
crash.info()
RangeIndex: 5268 entries, 0 to 5267
Data columns (total 8 columns):
Date 5268 non-null object
Time 3049 non-null object
Operator 5250 non-null object
Type 5241 non-null object
Registration 4933 non-null object
Aboard 5246 non-null float64
Fatalities 5256 non-null float64
Ground 5246 non-null float64
dtypes: float64(3), object(5)
memory usage: 329.3+ KB
print(crash[2200:2205])
Date Time Operator Type \
2200 03/06/1968 8:00 Military - U.S. Air Force Fairchild C-123K
2201 03/08/1968 19:18 Air Manila Fairchild F-27
2202 03/09/1968 23:20 Military - French Air Force Douglas DC6B
2203 03/19/1968 19:37 Viking Airways - Air Taxi Cessna 182
2204 03/23/1968 13:00 Fortaire Aviation - Air Taxi Brantly 305
Registration Aboard Fatalities Ground
2200 54-0590 49.0 49.0 0.0
2201 PI-C871 14.0 14.0 0.0
2202 43748 20.0 19.0 0.0
2203 N2623F 2.0 2.0 0.0
2204 N2224U 5.0 3.0 0.0
伤亡分析
伤亡排序
print(crash["Fatalities"].sum())
fatal_crash = crash[crash["Fatalities"].notnull()]
fatal_crash = fatal_crash.sort_values(by="Fatalities")
print(fatal_crash[-5:])
105479.0
Date Time Operator \
3562 06/23/1985 7:15 Air India
2726 03/03/1974 11:41 Turkish Airlines (THY)
4455 11/12/1996 18:40 Saudi Arabian Airlines / Kazastan Airlines
3568 08/12/1985 18:56 Japan Air Lines
2963 03/27/1977 17:07 Pan American World Airways / KLM
Type Registration Aboard \
3562 Boeing B-747-237B VT-EFO 329.0
2726 McDonnell Douglas DC-10-10 TC-JAV 346.0
4455 Boeing B-747-168B / Ilyushin IL-76TD HZAIH/UN-76435 349.0
3568 Boeing B-747-SR46 JA8119 524.0
2963 Boeing B-747-121 / Boeing B-747-206B N736PA/PH-BUF 644.0
Fatalities Ground
3562 329.0 0.0
2726 346.0 0.0
4455 349.0 0.0
3568 520.0 0.0
2963 583.0 0.0
- 内特里费空难:两架波音-747相撞,死亡583人,又称世纪大空难
- 日航123空难:波音747撞富士山,单架飞机失事最高死亡记录
- 恰尔基达德里撞机事件,最严重的的空中撞机事件
- 土耳其航空981号班机空难:货舱门未锁定导致爆炸性施压
- 印度航空182号班机:恐怖袭击
伤亡概率
print(fatal_crash["Fatalities"].sum() / fatal_crash["Aboard"].sum())
0.729700936002
print(fatal_crash[fatal_crash["Fatalities"] != 0]["Fatalities"].sum() / fatal_crash[fatal_crash["Fatalities"] != 0]["Aboard"].sum())
0.754191781605
机型处理
处理函数
type_crash = fatal_crash["Type"]
def type_handle(x):
x = str(x)
if "McDonnell Douglas" in x:
return "McDonnell Douglas"
elif "Douglas" in x:
return "Douglas"
elif "Boeing" in x:
return "Boeing"
elif "Airbus" in x:
return "Airbus"
elif "Embraer" in x:
return "Embraer"
elif "Ilyushin" in x:
return "Ilyushin"
else:
return "other"
company_crash = type_crash.map(type_handle)
print(pd.value_counts(company_crash))
other 3581
Douglas 984
Boeing 376
McDonnell Douglas 123
Ilyushin 96
Embraer 61
Airbus 35
Name: Type, dtype: int64
fatal_crash["company"] = company_crash
print(fatal_crash[:2])
Date Time Operator Type Registration \
108 10/21/1926 13:15 Imperial Airways Handley Page W-10 G-EBMS
5178 11/08/2007 8:00 Juba Air Cargo Antonov 12 ST-JUA
Aboard Fatalities Ground year month company
108 12.0 0.0 0.0 1926 10 other
5178 4.0 0.0 2.0 2007 11 other
处理结果
def airplane_counte(x):
fatal_ratio = x["Fatalities"].sum() / x["Aboard"].sum()
crash_time = x.shape[0]
fatal_num = x["Fatalities"].sum()
return pd.Series({"fatal_num":fatal_num,"crash_time":crash_time,"fatal_ratio":fatal_ratio})
company = fatal_crash.groupby(['company']).apply(airplane_counte)
print(company)
plt.close()
plt.figure(figsize=(16,4))
plt.subplot(1,3,1)
company['crash_time'].drop("other").plot(kind='bar',title="time")
plt.subplot(1,3,2)
company['fatal_num'].drop("other").plot(kind='bar',title="fatal_num")
plt.subplot(1,3,3)
company['fatal_ratio'].plot(kind='bar',title="fatal_ratio")
plt.show()
crash_time fatal_num fatal_ratio
company
Airbus 35.0 2980.0 0.510711
Boeing 376.0 18705.0 0.649434
Douglas 984.0 16899.0 0.794350
Embraer 61.0 644.0 0.779661
Ilyushin 96.0 4547.0 0.883084
McDonnell Douglas 123.0 6827.0 0.531946
other 3581.0 54877.0 0.785854
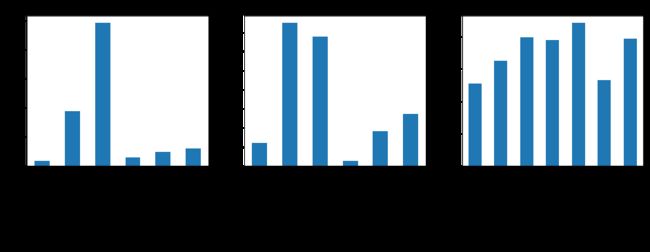
分厂商分析结果
时间分析
年
def get_year(x):
return x.split("/")[-1]
fatal_crash['year'] = fatal_crash["Date"].map(get_year)
year_fatal = fatal_crash[fatal_crash["year"] != np.NaN][["year","Fatalities","Aboard"]]
year_fatal.info()
Int64Index: 5256 entries, 108 to 2963
Data columns (total 3 columns):
year 5256 non-null object
Fatalities 5256 non-null float64
Aboard 5246 non-null float64
dtypes: float64(2), object(1)
memory usage: 164.2+ KB
def year_analysis(x):
return pd.Series({"fatal_num":x["Fatalities"].sum(),"time":x.shape[0],"fatal_ratio":x["Fatalities"].sum() / x["Aboard"].sum()})
year = year_fatal.groupby(["year"]).apply(year_analysis)
year = year.sort_index()
year.info()
Index: 98 entries, 1908 to 2009
Data columns (total 3 columns):
fatal_num 98 non-null float64
fatal_ratio 98 non-null float64
time 98 non-null float64
dtypes: float64(3)
memory usage: 3.1+ KB
plt.close()
plt.figure(figsize=(16,4))
plt.subplot(1,3,1)
year["fatal_num"].plot(title="fatal_num")
plt.subplot(1,3,2)
year["time"].plot(title="crash_time")
plt.subplot(1,3,3)
year["fatal_ratio"].plot(title="fatal_ratio")
plt.show()
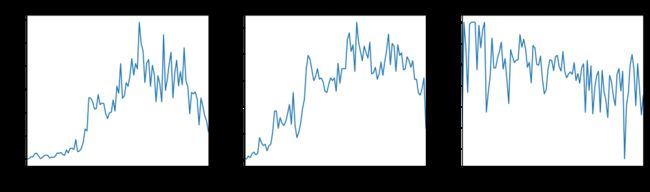
按年分析结果
月
def get_month(x):
return x.split("/")[0]
fatal_crash['month'] = fatal_crash["Date"].map(get_month)
month_fatal = fatal_crash[fatal_crash["month"] != np.NaN][["month","Fatalities","Aboard"]]
month_fatal.info()
Int64Index: 5256 entries, 108 to 2963
Data columns (total 3 columns):
month 5256 non-null object
Fatalities 5256 non-null float64
Aboard 5246 non-null float64
dtypes: float64(2), object(1)
memory usage: 164.2+ KB
def month_analysis(x):
return pd.Series({"fatal_num":x["Fatalities"].sum(),"time":x.shape[0],"fatal_ratio":x["Fatalities"].sum() / x["Aboard"].sum()})
month = month_fatal.groupby(["month"]).apply(year_analysis)
month = month.sort_index()
print(month)
fatal_num fatal_ratio time
month
01 8425.0 0.768354 494.0
02 7966.0 0.693057 395.0
03 8708.0 0.787057 453.0
04 6769.0 0.711852 378.0
05 7130.0 0.731807 370.0
06 7909.0 0.681399 385.0
07 9232.0 0.700349 427.0
08 10174.0 0.729162 474.0
09 10286.0 0.760349 458.0
10 8388.0 0.778758 452.0
11 10033.0 0.766522 454.0
12 10459.0 0.668478 516.0
plt.close()
plt.figure(figsize=(16,4))
plt.subplot(1,3,1)
month["fatal_num"].plot(kind="bar",title="fatal_num")
plt.subplot(1,3,2)
month["time"].plot(kind="bar",title="crash_time")
plt.subplot(1,3,3)
month["fatal_ratio"].plot(kind="bar",title="fatal_ratio")
plt.show()
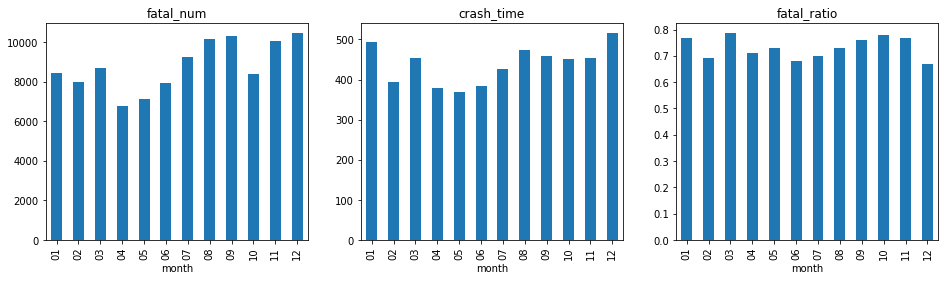
按月份分析
小时
def get_hour(x):
hour = x.split(":")[0]
try:
hour = float(hour)
if int(hour) == hour and hour < 24:
return hour
else:
return np.nan
except:
return np.nan
time_fatal = fatal_crash[fatal_crash["Time"].isnull() == False]
time_fatal["hour"] = time_fatal["Time"].map(get_hour)
time_fatal.info()
Int64Index: 3049 entries, 108 to 2963
Data columns (total 13 columns):
Date 3049 non-null object
Time 3049 non-null object
Operator 3046 non-null object
Type 3048 non-null object
Registration 2952 non-null object
Aboard 3049 non-null float64
Fatalities 3049 non-null float64
Ground 3046 non-null float64
airplane 3049 non-null object
company 3049 non-null object
year 3049 non-null object
month 3049 non-null object
hour 3036 non-null float64
dtypes: float64(4), object(9)
memory usage: 333.5+ KB
c:\users\qiank\appdata\local\programs\python\python35\lib\site-packages\ipykernel_launcher.py:13: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
del sys.path[0]
def hour_analysis(x):
return pd.Series({"fatal_num":x["Fatalities"].sum(),"time":x.shape[0],"fatal_ratio":x["Fatalities"].sum() / x["Aboard"].sum()})
hour = time_fatal.groupby(["hour"]).apply(hour_analysis)
plt.close()
plt.figure(figsize=(16,4))
plt.subplot(1,3,1)
hour["fatal_num"].plot(title="fatal_num")
plt.subplot(1,3,2)
hour["time"].plot(title="crash_time")
plt.subplot(1,3,3)
hour["fatal_ratio"].plot(title="fatal_ratio")
plt.show()
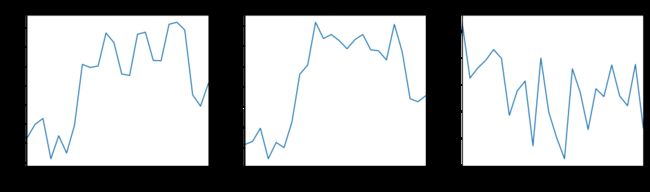
按时间分析