感谢 Dr.fish 的耐心讲解和细致回答。
本次课的作业如下:
基于smoking_cancer.csv数据,用描述统计量和统计图表对其进行分析。
备注:
STATE: 美国州名的简写
CIG: 人均吸烟的数量
BLAD: 每10万人中死于膀胱癌( bladder cancer)的人数
LUNG: 每10万人中死于肺癌(lung cancer)的人数
KID: 每10万人中死于肾癌(kidney cancer)的人数
LEUK: 每10万人中死于白血病(leukemia)的人数
这次生病了,本来还有些分析要做的,但是有点儿支持不住了,后面身体好了会补上。
不再贫了,直奔主题。
结论
- 全美平均吸烟量为25根,极差28.4,数据分散度较大;
- 四款癌症发病数中,肺癌发病数遥遥领先,已超过全部癌症的一半,其次为白血病
- 分别计算四款癌症与吸烟的相关性发现相关从强到弱分别为:膀胱癌 - 肺癌 - 肾癌 - 白血病
以下为代码部分
#导入分析包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from __future__ import division # 支持精确除法
from sklearn.cluster import KMeans # 聚类分析包
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # 设置图像清晰度
# 导入数据表并查看
df = pd.read_csv('smoking_cancer.csv')
df.head()
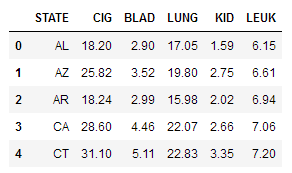
数据样式
# 查看数据表整体情况
df.info()

查看数据表整体情况
# 查看基础统计项
df.describe()
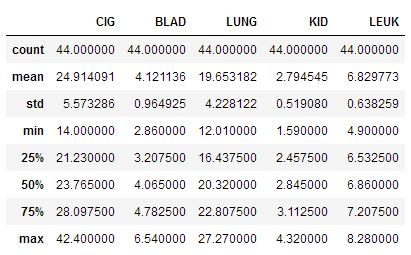
查看基础统计项
# 全美平均吸烟量全距
cig_range = df['CIG'].max() - df['CIG'].min() #极差
print 'cig_range:',cig_range
# 输出结果
cig_range: 28.4
# 全美癌症发病数
bladder = df['BLAD'].sum()
lung = df['LUNG'].sum()
kidney = df['KID'].sum()
leukemia = df['LEUK'].sum()
print 'bladder:',bladder
print 'lung:',lung
print 'kidney:',kidney
print 'leukemia:',leukemia
# 输出结果
bladder: 181.33
lung: 864.74
kidney: 122.96
leukemia: 300.51
# 四种癌症占比
plt.figure(figsize = (5 , 7))
labels = [u'bladder',u'lung',u'kidney',u'leukemia']
sizes = [181.33, 864.74, 122.96, 300.51]
colors = ['#FFFFCC', '#CCFFFF', '#99CCCC', '#FFCCCC']
plt.pie(sizes, labels=labels, colors=colors, labeldistance = 1.1, autopct = '%1.1f%%', shadow = False, startangle = 90, pctdistance = 0.6)
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%1.1f%%表示小数有1位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
plt.axis('equal') # 调整坐标轴的比例
plt.show()
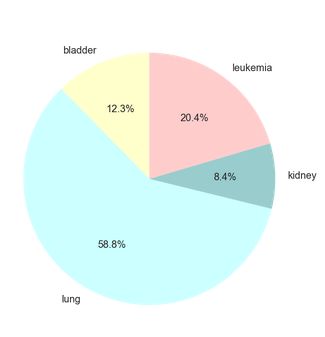
四种癌症占比
**备注 **
- 全美平均吸烟量为25根(一天一包烟,这个量可是真不小)
- 极差28.4,数据分散度较大
- 四项癌症发病数中,肺癌发病数遥遥领先,已超过全部癌症的一半,其次为白血病(是否有相关性待查)
综上所述,需要查看下每个州人均吸烟量情况
# 每州人均吸烟量柱图
state = df.STATE.value_counts()
state_name = list(state.index)
x = np.arange(len(state_name))
y = df.CIG
plt.figure(figsize=(20,4)) #设置chart长宽
plt.bar(x,y,color = '#00bfff',alpha=0.5) #生成条形图,"color"设置柱子颜色,"alpha"设置柱子透明度
plt.xticks(x, state_name,rotation=30) #设置X轴标签,rotation 旋转横坐标标签
plt.xlabel('state name') #设置X轴名称
plt.ylabel('CIG') #设置Y轴名称
plt.title('CIG OF STATE') #设置chart标题
plt.legend(['CIG'],loc = 'upper right',fontsize = 10) #添加图示,fontsize 字号大小
#添加数据标签
#a,b+0.5 在每一柱子对应x值、y值上方0.5处标注文字说明
#'%.0f' % b 标注的文字(每个柱子对应的y值)
#ha='center',va= 'bottom' horizontalalignment(水平对齐)、verticalalignment(垂直对齐)
for a,b in zip(x,y):
plt.text(a, b + 0.5, '%.0f' % b, ha='center', va= 'bottom',fontsize=10)
plt.show()
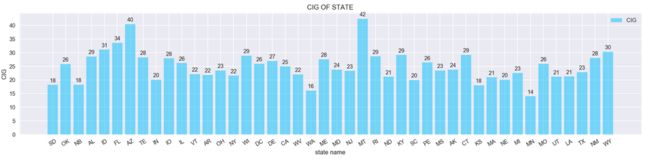
每州人均吸烟量柱图
# 每州总癌症发病数柱图
bladder_c = df.groupby('STATE').BLAD.sum() #计算各州 hillary 支持票数
lung_c = df.groupby('STATE').LUNG.sum() #计算各州 trump 支持票数
kidney_c = df.groupby('STATE').KID.sum()
leukemia_c =df.groupby('STATE').LEUK.sum()
states = list(bladder_c.index) #获取各州名称
x = np.arange(len(states)) #返回array类型对象
y = bladder_c #指定 hillary 的Y坐标
y1 = lung_c #指定 trump 的Y坐标
y2 = kidney_c
y3 = leukemia_c
plt.figure(figsize=(20,4)) #设置chart长宽
plt.bar(x,y,width = 0.8,align = 'center',color = '#FFFFCC') #生成条形图,"color='g'"设置柱子颜色,"alpha=0.5"设置柱子透明度
plt.bar(x,y1,width = 0.8,align = 'center',color = '#CCFFFF',bottom = y)
plt.bar(x,y2,width = 0.8,align = 'center',color = '#99CCCC',bottom = y)
plt.bar(x,y3,width = 0.8,align = 'center',color = '#FFCCCC',bottom = y)
plt.xticks(x, states,rotation=30) #设置X轴标签,rotation 旋转横坐标标签
plt.xlabel('states name') #设置X轴名称
plt.ylabel('ticket') #设置Y轴名称
plt.title('APPROVAL RATINGS') #设置chart标题
plt.legend(['bladder','lung','kidney','leukemia'],loc = 'upper right',fontsize = 10) #添加图示,fontsize 字号大小
#添加数据标签
#a,b+0.8 在每一柱子对应x值、y值上方0.5处标注文字说明
#'%.0f' % b 标注的文字(每个柱子对应的y值)
#ha='center',va= 'bottom' horizontalalignment(水平对齐)、verticalalignment(垂直对齐)
for a,b in zip(x,y):
plt.text(a, b - 3, '%.0f' % b, ha = 'center', va = 'bottom',fontsize = 10)
for a,b in zip(x,y1):
plt.text(a, b + 0.8, '%.0f' % b, ha = 'center', va = 'bottom',fontsize = 10)
for a,b in zip(x,y2):
plt.text(a, b + 1, '%.0f' % b, ha = 'center', va = 'bottom',fontsize = 10)
for a,b in zip(x,y3):
plt.text(a, b + 0.8, '%.0f' % b, ha = 'center', va = 'bottom',fontsize = 10)
plt.show()

每州癌症爆发柱图
以下依据癌症爆发人次进行分析相关性
# 平均吸烟量与癌症相关性 - lung
plt.scatter(df.CIG, df.LEUK, c = '#6666FF')
plt.show()
np.corrcoef(df.CIG, df.LUNG)[0,1] # 计算相关系数
# 输出结果
相关系数 : 0.6974025049275292
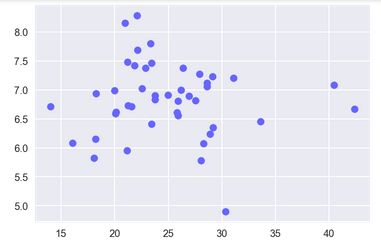
吸烟与肺癌发病散点图
# 加线性回归方法(95%置信区间)
sns.lmplot(x = "CIG", y = "LUNG",data = df[['CIG','LUNG']], order = 1, ci = 95, size=4, aspect=1)
plt.show()
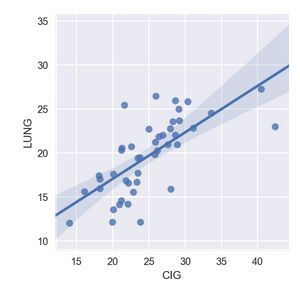
线性回归验证相关性
# 平均吸烟量与癌症相关性 - leukemia
plt.scatter(df.CIG, df.LEUK, c = '#FF6666')
plt.show()
np.corrcoef(df.CIG, df.LEUK)[0,1] # 计算相关系数
# 输出结果
相关系数 : -0.068481229476638969
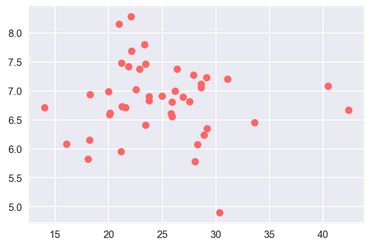
吸烟与白血病发病散点图
# 加线性回归方法(95%置信区间)
sns.lmplot(x = "CIG", y = "LEUK",data = df[['CIG','LEUK']], order = 1, ci = 95, size=4, aspect=1)
plt.show()
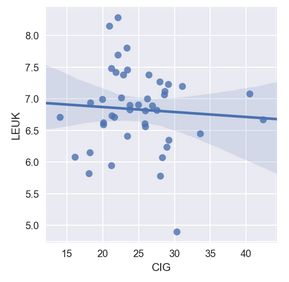
线性回归验证相关性
# 平均吸烟量与癌症相关性 - bladder
plt.scatter(df.CIG, df.BLAD, c = '#FFFF66')
plt.show()
np.corrcoef(df.CIG, df.BLAD)[0,1] # 计算相关系数
# 输出结果
相关系数 : 0.70362185946144185
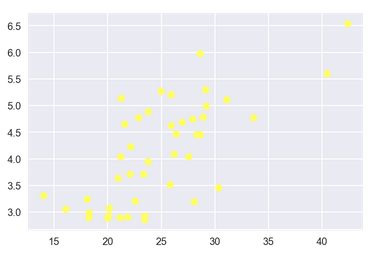
吸烟与膀胱癌发病散点图
# 加线性回归方法(95%置信区间)
sns.lmplot(x = "CIG", y = "BLAD",data = df[['CIG','BLAD']], order = 1, ci = 95, size=4, aspect=1)
plt.show()
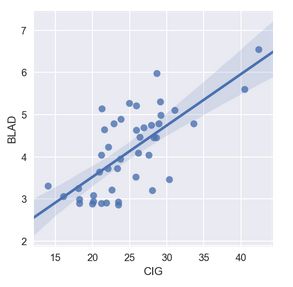
线性回归验证相关性
# 平均吸烟量与癌症相关性 - kidney
plt.scatter(df.CIG, df.KID, c = '#336699')
plt.show()
np.corrcoef(df.CIG, df.KID)[0,1] # 计算相关系数
# 输出结果
相关系数 :0.48738961703356476
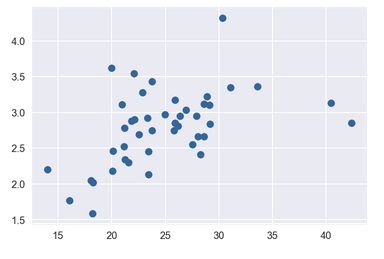
吸烟与肾癌发病散点图
# 加线性回归方法(95%置信区间)
sns.lmplot(x = "CIG", y = "KID",data = df[['CIG','KID']], order = 1, ci = 95, size=4, aspect=1)
plt.show()
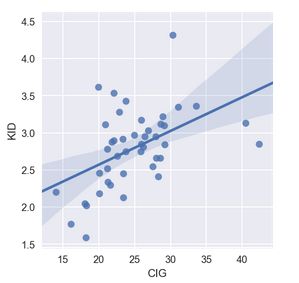
线性回归验证相关性
后记
就在写这篇作业的时候,小白也在与病魔进行斗争(生扛那种),深刻的体会到了拥有一个好身体的重要性。其实这篇作业写得还是蛮压抑的,随着cancer的全球性爆发,我们究竟如何才能躲过它走向生命的尽头,真的很值得我们思考(再想想帝都的雾霾…OMG,小白好像病的更厉害了些)。
虽然没有证据证明肺癌是由吸烟引起的,但是依据数据可以明显看到它们的强相关性。以及让小白差异的膀胱癌?!居然相关性比肺癌还高。当然,这只是一份全美的数据表,给出的数据规模也并不能完全支持“吸烟更容易引起膀胱癌”这样的结论,另外也没有将其他疾病数据引入进来。但即便是这样,我们还是可以发现样本数据中吸烟就是会和某些癌症表现出异常的相关性来,这样的结果多少值得我们重视一下。
所以,爱惜生命,从戒烟开始。