文章首发于我的个人项目SunHuawei/SourceDetector
缘起
此前我在回答这个问题的时候提到,“我偶然间获得了知乎的源码”。本文将解释我是如何“偶然获取”的。另外本repo即是由此而生的一个chrome extension。
Source Map
前端工程化的一个重要部分就是就是源码转换,一方面压缩体积,另一方面合并文件。当然还有可能是为了转换Typescript、ES6+或其他代码。但通常转换完的代码难以阅读和调试。Source Map就是为了解决这个问题而出现的。
关于Source Map的详细信息,推荐阮一峰的这篇文章-JavaScript Source Map 详解。
故事
话说,某天我在逛知乎的时候习惯性的打开了Chrome Dev-tools,在Sources栏下竟然发现了一个webpack://目录。用过webpack source map的前端应该立刻就会反应过来-哇,有源码!于是我便如此“偶然获得”了文件zfeedback.js.map。
故事还没完。
事实上,我此时是可以直接查看各个源码文件的。只是如何将其保存到本地呢?我尝试点击右键,貌似并没有保存整个目录到本地的选项,看起来只能一个一个文件的保存,好累。
受好奇心驱使,我在github上搜了一圈,找到了一个开源项目-mozilla/source-map。于是自己手动写了些代码便将整个目录下载到了本地。啊哈~
源码如下,可用node app.js执行。
// app.js
const fs = require('fs-extra')
const https = require('https')
const crypto = require('crypto')
const SourceMapConsumer = require('source-map').SourceMapConsumer
const analyse = (srcMapURL) => {
const BASE_CACHE_PATH = __dirname + '/cache/'
const BASE_OUTPUT_PATH = __dirname + '/output/' + srcMapURL.substr(srcMapURL.lastIndexOf('/') + 1) + '/'
const BASE_OUTPUT_LIB_PATH = BASE_OUTPUT_PATH + 'node_modules/'
const md5 = (content) => {
let md5Maker = crypto.createHash('md5');
md5Maker.update(content);
return md5Maker.digest('hex');
}
const download = (url, callback) => {
const hash = md5(url)
const cacheFileName = BASE_CACHE_PATH + hash
if (fs.existsSync(cacheFileName)) {
fs.readFile(cacheFileName, 'utf8', (err, data) => {
console.log("From cache")
callback(data)
})
} else {
return https.get(url, function(response) {
let body = '';
let totalSize = parseInt(response.headers['content-length'])
response.on('data', function(d) {
body += d
printDownloading(body, totalSize)
});
response.on('end', function() {
printFinishDownload(body)
fs.outputFile(cacheFileName, body, error => {
callback(body)
})
});
});
}
}
const printDownloading = (body, totalSize) => {
let statusLine = '\r'
statusLine += 'Downloading '
statusLine += srcMapURL.substr(srcMapURL.lastIndexOf('/') + 1)
statusLine += ' '
statusLine += (body.length / totalSize * 100).toFixed(2)
statusLine += '%'
process.stdout.write(statusLine)
}
const printFinishDownload = (body) => {
let statusLine = 'Finish Download '
statusLine += srcMapURL.substr(srcMapURL.lastIndexOf('/') + 1)
statusLine += ' total size: '
statusLine += body.length
statusLine += 'bytes'
console.log('\n' + statusLine)
}
download(srcMapURL, (rawSourceMap) => {
try {
const consumer = new SourceMapConsumer(rawSourceMap);
if (consumer.hasContentsOfAllSources()) {
consumer.sources.forEach(fileName => {
if (fileName.indexOf('webpack://') !== 0) {
return
}
let fileContent = consumer.sourceContentFor(fileName)
fileName = fileName.replace(/^webpack:\/\//, '')
fileName = fileName.replace(/^\//, BASE_OUTPUT_PATH)
fileName = fileName.replace(/^.*\/\~\//, BASE_OUTPUT_LIB_PATH)
fs.outputFile(fileName, fileContent, error => {
// console.log(error) // TODO, debug code, to delete before commit
})
})
console.log('Please check here for sources: ', BASE_OUTPUT_PATH)
} else {
console.log('TODO')
}
} catch (e) {
console.log("Failed to parse", srcMapURL) // TODO, debug code, to delete before commit
}
})
}
let jsURLs = `
https://zhstatic.zhihu.com/assets/zfeedback/3.0.13/zfeedback.js
`
jsURLs.split('\n').filter(Boolean).forEach(jsURL => {
const srcMapURL = jsURL + '.map'
analyse(srcMapURL)
})
之后的故事是,我将分析源码的过程写到了这个回答。之后知乎某员工询问我如何获取的源码,建议我与知乎开发及安全团队取得联系,我解释了该过程,然后知乎修复了问题。
事后
不过依然不过瘾。这样只能是当我有了某个.map文件时可以解析出源文件。如果能有一个工具随时提醒我,我访问的某个网站有源码,并帮我下载下来就更完美了。于是便有了这个Chrome extension。
安装
Chrome web store
安装地址https://chrome.google.com/webstore/detail/source-detecotor/aioimldmpakibclgckpdfpfkadbflfkn?hl=zh-CN&gl=CN
源码安装
git clone https://github.com/SunHuawei/SourceDetector.gitnpm installbower installgulp- 打开Chrome设置-扩展程序
- 点击"加载已解压的扩展程序..."
- 选择
path/to/source-detector/dist目录

之后你在浏览任何网页时,该插件将自动检测是否有.map文件。其会自动按网站分组显示源码文件,并可点击下载全部或部分源码文件。
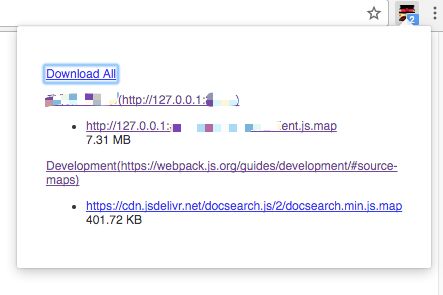
进入webpack首页,查看右上角的小图标吧~
有问题?有建议?
欢迎说出你的想法。欢迎issue和PR。