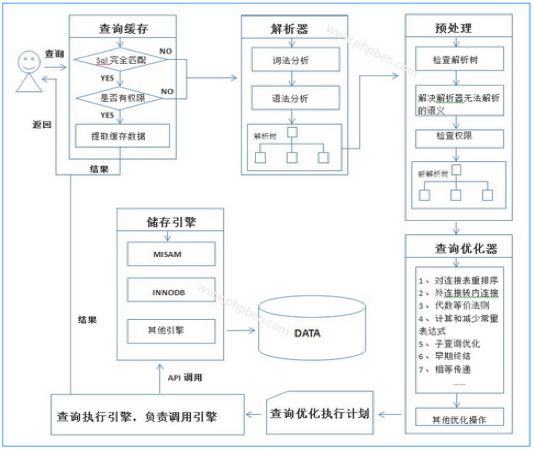
SQL执行流程
索引
快速定位记录的一种数据结构
B+Tree索引
等值、范围检索
Hash索引
等值检索
空间索引(R-Tree)
地理数据检索(多维)
全文索引
非结构化数据检索
索引作用
减少IO
随机IO转化为顺序IO
减少内存计算(比较、排序)
索引类型
普通索引: 最基本的索引类型,
唯一索引: 索引列的所有值都必须唯一
聚簇索引,二级索引
单列索引,组合索引
特点
多叉平衡树,节点的单位是page
提高select速度
降低(insert,delete,update)速度
根据不同维度,可以建立多个索引
B+Tree索引
非叶子节点是叶子节点的索引
叶子节点是数据层
任一值搜索深度相同
叶子结点组成链表,用于全表扫描
存储容量
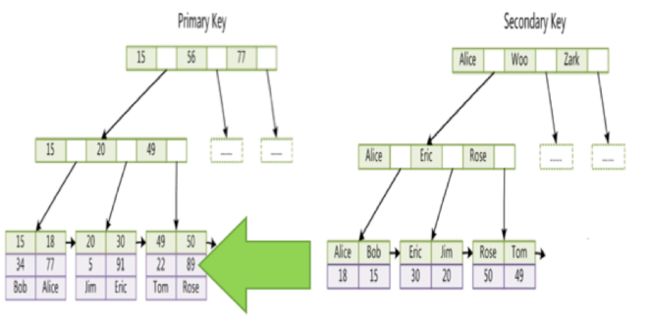
Primary Index VS Secondary Index
create table tab(id int primary key,c1 int,index(c1),c2 varchar(128))
– Clustered index key = 4 bytes
– Secondary index key = 4 bytes
– Key pointer = 8 bytes
– Average row length = 200 bytes
– Page size = 16K = 16384 bytes
– Average node occupancy = 70%
– Average row per page(Pri Key) = 16384 * 70% / 200 ≈50
– Average row per page(Sec Key) = 16384 * 70% / (4+8) ≈1000


查询代价估算

SQL代价= Random IO(RO) +
Sequence IO(SO) +
CPU(内存计算)
单表查询
主键查询
SELECT ... FROM table whereprimary_key=???
代价:RO(PK-Tree(h))
二级索引查询
SELECT ... FROM table where key = ???
代价:RO(Sec-Tree(h)) + N*RO(PK-Tree(h))
全表扫描
SELECT ... FROM table where col = ???
代价:SO(PK-Tree)
连接查询
SELECT ... FROM a1 join on a2 where a1.name = a2.name
NLJ(Nest Loop Join)
For each tuple r in R do
For each tuple s in S do
If r and s satisfy the join condition Then output the tuple
代价:SO(R-tree) * SO(S-tree)
NLIJ(Nest Loop Index Join)
For each tuple r in R do
lookup r join condition in S index
If found s == r
Then output the tuple
代价:SO(R-tree) * RO(S-tree(h))
表结构设计
降低单条记录长度
提高缓存利用率
将访问频率低、大字段拆分,用主键对应
提高缓存命中率
适当冗余,减少多表join查询
使用信息统计表
索引设计
选择过滤性高的字段
distinct(col)与count(*)比值
Join查询中连接字段建立索引
避免全表扫描
尽量使用覆盖索引
无需访问表,避免随机IO
利用前缀索引
name varchar(128), index(name(16))
避免重复使用索引
(a),(a,b),(a,b,c)
业务确定唯一,建唯一索引
SQL写法
尽量利用索引排序,避免产生临时表
order by col1,col2 index(col1,col2)
避免对查询字段进行计算(类型转换,计算)
where id*2 > 5
避免使用select *
避免使用全模糊查询 like '%xxx%’
多SQL综合考虑,保证核心SQL
SQL优化实践

减少磁盘访问
使用索引检索记录
CREATE INDEX idx_abc ON table (A, B, C);
下列查询条件可使用索引(红色部分不能使用索引)
A=5
● A BETWEEN 5 AND 10
● A=5 AND B BETWEEN 5 AND 10
● A BETWEEN 5 AND 10 AND B=5
● A IN (5,6,7,8,9,10) AND B=5
× B=5 and ...
× A=5 and B > 5 and C>5
减少磁盘访问
使用覆盖索引
CREATE INDEX idx_ab ON table (A, B);
使用该索引可直接返回结果集
● SELECT A, B FROM table where
[ A=5 AND B BETWEEN 5 AND 10 ]
[ A IN (5,6,7,8,9,10) AND B=5 ]
返回更少的数据
只返回需要的字段
select * from product where company_id=?;
优化:select id,name from product where company_id=?;
优点:
1、减少网络传输开销
2、减少处理开销
3、减少客户端内存占用
4、字段变更时提前发现问题,减少程序BUG
5、有机会使用覆盖索引
减少交互次数
select * from tbl_1 where id in(:id1,id2,...,idn);
优点:
1.减少交互次数
2.减少语法/语义分析,执行计划生成过程
3.建议in不超过20
更新批量提交

减少CPU开销
利用索引排序
CREATE INDEX idx_ab ON table (A, B);
下列查询条件可使用索引(红色部分不能使用索引)
ORDER BY A
● ORDER BY A,B
● ORDER BY A DESC, B DESC
● A=5 ORDER BY B [ASC/DESC]
● A>5 ORDER BY A [ASC/DESC]
● A>5 ORDER BY A,B
× ORDER BY B
× ORDER BY A [ASC/DESC], B[DESC/ASC]
减少“比较”,比如全模糊匹配
执行计划查看
Explain语句
(1).EXPLAIN SELECT ……
(2).EXPLAIN EXTENDED SELECT ……

复习
where后面的条件字段都要建索引?
建一个组合索引还是多个单列索引?
对于and, or , >, < , like等谓词,如何建索引?
使用了索引就一定快?
索引顺序要与where条件中字段顺序一致?
(a,b)还是(b,a)?