声明:由于本人也是处于学习阶段,有些理解可能并不深刻,甚至会携带一定错误,因此请以批判的态度来进行阅读,如有错误,请留言或直接联系本人。
WEEK3内容概要:1)week2回顾;2)Design Pattern 1: In-mapper Combining;3)Design Pattern 2: Pairs vs Stripes;4)Writable(定义及相关Java语句); 5)Design Pattern 3: Order Inversion
关键词:In-mapper Combining; commutative; associative; Pairs; Stripes; Term Co-occurrence; serialization; Writable; Order Inversion
Overview of Previous Lecture
1)Motivation of MapReduce
2)Data Structures in MapReduce: (key, value) pairs
3)Map and Reduce Functions
4)Hadoop MapReduce Programming
4.1)Mapper
4.2)Reducer
4.3)Combiner
4.4)Partitioner
4.5)Driver
问题,combiner function的作用和使用规则是什么?
1)To minimize the data transferred between map and reduce tasks
2)Combiner function is run on the map output
3)Both input and output data types must be consistent with the output of mapper (or input of reducer)
4)But Hadoop do not guarantee how many times it will call combiner function for a particular map output record
4.1)It is just optimization
4.2)The number of calling (even zero) does not affect the output of Reducers
5)Applicable on problems that are commutative(分配律) and associative(结合律)(注意,只有满足交换律和结合律才能将reducer当作combiner用。PPT.13)
(记住:1)Combiners and reducers share same method signature因此Sometimes, reducers can serve as combiners;2)Remember: combiner are optional optimizations,所以Should not affect algorithm correctness,以及May be run 0, 1, or multiple times)
Design Pattern 1: In-mapper Combining
在处理数据情况下,Twice the data, twice the running time,如果我们Twice the resources, half the running time(可以理解为使用两台计算机并行处理,那么速度就倍增),但是Data synchronization requires communication, but communication kills performance.因此,我们通过先进行本地aggregation然后再通过Reducer的HTTP 请求传输给Reducer,以提高效率。我们已知,combiner是工作在mapper node中的optimization option,但是它的工作流程是mapper output(memory) -> disk -> combiner processing(memory)。因为要通过I/0传输给disk,所以受限于I/O带宽,效率也会受到影响。那么有没有什么好的算法设计,使得aggregation直接在memory中进行呢?有,就是采用In-mapper Combining。
下面我们用用Word Count来作为例子进行解释:

图一伪代码将mapper output 直接作为reducer input,因此会有成百上千的(termt, count 1)的intermediate records 直接传输给reducer。由于网络带宽的限制,这会降低mapreduce的工作效率。
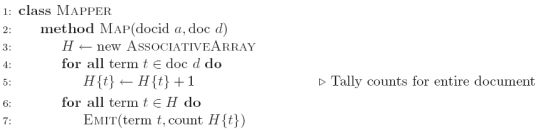
由此,我们采用图二的方式,设一个ASSOCIATIVEARRAY将一个document下所有term t sum到H{t}中,然后EMIT(term t, count H{t})。
那么这里我们可以忽略combiner吗?
不可以,因为每次执行一个document,针对term t会建立一个新的ASSOCIATIVEARRAY。然而一个mapper node在一个task中可能会执行多个document(假设n个document),而每个document中都可能有term t,那么将会生成n个关于term t的ASSOCIATIVEARRAY。于是,还需要使用combiner将这n个term t的ASSOCIATIVEARRAY进行combine。

由于combiner的效率还是不高,于是我们采用图三的in-mapper combining。这里的先创立一个总的ASSOCIATIVEARRAY,通过不断的读入documents来不断的将term t的数量sum到这个总的ASSOCIATIVEARRAY中的H{t}中。
由此,我们可以总结in-mapper combining的特点:
1)Fold the functionality of the combiner into the mapper by preserving state across multiple map calls
2)Advantages
2.1)Speed(通过网络传输的数据更加小(就wordcount而言,一个mapper传给一个reducer只有一个pair))
2.2)It's faster than actual combiners(因为in-mapper combining是完全在memory中进行的,而combiner combine数据要将map output从memory传到disk,再从disk传到memory进行combine)
3)Disadvantages
3.1)Explicit memory management required
3.2)Potential for order-dependent bugs
下面我们再用一个求平均值的例子更加详细的说明in-mapper combining:

在图四中,我们直接将mapper output作为reducer input,而省略了combiner,那么这里我们将reducer当作combiner用可不可以呢?
不可以,因为只有满足交换律和结合律才能将reducer当作combiner用。
(注意,这是个错误示例,是为了说明combiner的使用是要满足commutative(分配律)和 associative(结合律)的)
class MAPPER
method MAP(string t, interger r)
EMIT(string t, integer r)
class COMBINER
method COMBINER(string t, intgers[r1, r2, ...])
sum <- 0
count <- 0
for all integer r 属于 intergers[r1, r2, ...] do
sum <- sum + r
count <- count + 1
r(avg) <- sum/count
EMIT(string t, integer r(avg))
class REDUCER
method REDUCER(string t, integers[r1(avg), r2(avg),...])
sum <- 0
count <- 0
for all integer r 属于 intergers[r1(avg), r2(avg),...] do
sum <- sum + r(avg)
count <- count + 1
r_all(avg) <- sum/count
EMIT(string t, integer r_all(avg))
然而在这里,如果每一个mapper node的关于string t的平均值都被combiner算出来了,那么在reducer中首先得到的是每个mapper node关于string t的平均值,接着这些平均值被sum然后求average,这是不正确的。例如:Mean(1, 2, 3, 4, 5) != Mean(Mean(1, 2), Mean(3, 4, 5))

那么,我们采用图5的方法可以吗?
不可以,因为mapper input的类型与reducer input 的类型不符,这里经过combiner的combine之后,数据类型被改变了,而根据MapReduce的作业要求:Both input and output data types must be consistent with the output of mapper (or input of reducer)。所以图五的方式不正确。

图六的写法是对的,然而有combiner还是不那么高效,可以将其转化为更高效的in-mapper combining 吗?可以,见图七。

问题,How to Implement In-mapper Combiner in MapReduce?
1)Lifecycle: setup -> map -> cleanup
1.1)setup(): called once at the beginning of the task
1.2)map(): do the map
1.3)cleanup(): called once at the end of the task.
1.4)We do not invoke these functions
2)In-mapper Combining:
1.1)Use setup() to initialize the state preserving data structure
2.2)Use clearnup() to emit the final key-value pairs

Design Pattern 2: Pairs vs Stripes
Term Co-occurrence Computation
1)Term co-occurrence matrix for a text collection
1.1)M = N x N matrix (N = vocabulary size)
1.2)Mij: number of times i and j co-occur in some context (for concreteness, let’s say context = sentence)
1.3)specific instance of a large counting problem
1.3.1)A large event space (number of terms)
1.3.2)A large number of observations (the collection itself)
1.3.3)Goal: keep track of interesting statistics about the events
2)Basic approach
2.1)Mappers generate partial counts
2.2)Reducers aggregate partial counts
那我们用什么方法来计算Term Co-occurrence呢?
1)Pairs
2)Stripes
pairs:
1)Each mapper takes a sentence
1.1)Generate all co-occurring term pairs
1.2)For all pairs, emit (a, b) → count
2)Reducers sum up counts associated with these pairs
3)Use combiners
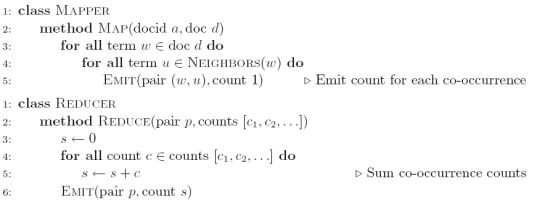
Pairs’ Advantages
1)Easy to implement, easy to understand
Pairs’ Disadvantages
1)Lots of pairs to sort and shuffle around (upper bound?)
2)Not many opportunities for combiners to work(因为,相对于一个词的wordcount,相同单词对在一个mapper node中显得较少,因此combiner作用的机会少)
Stripes:


上图,MAPPER中,第一个for循环找出,key:w并创立新ASSOCIATIVEARRAY: H(用来存储stripes),然后第二个for循环找出w的neighbor word: u,然后对u计数存入H{u}。最后输出EMIT(Term w, Stripe H)。在Reducer中,通过对以Key:w的数据类中的stripes里的neighbor words的H进行sum,来得到一个最终的以key: w; stripe: Hf的数据类型输出。(例如, 2个mapper各向reducer传入:a→{b:1; d:5; e:3}; a→{b:1; c:2; d:2; f:2}, 于是reducer将他们aggregate后得到 a→{b:2; c:2; d:7; e:3; f:2})
Stripes’ Advantages
1)Far less sorting and shuffling of key-value pairs
2)Can make better use of combiners
Stripes’ Disadvantages
1)More difficult to implement
2)Underlying object more heavyweight
3)Fundamental limitation in terms of size of event space
Pairs vs. Stripes:
1)The pairs approach
1.1)Keep track of each team co-occurrence separately
1.2)Generates a large number of key-value pairs (also intermediate)
1.3)The benefit from combiners is limited, as it is less likely for a mapper to process multiple occurrences of a word
2)The stripe approach
2.1)Keep track of all terms that co-occur with the same term
2.2)Generates fewer and shorted intermediate keys
2.3)The framework has less sorting to do
2.4)Greatly benefits from combiners, as the key space is the vocabulary
2.5)More efficient, but may suffer from memory problem
3)These two design patterns are broadly useful and frequently observed in a variety of applications
3.1)Text processing, data mining, and bioinformatics
相较于Pairs,Stripes面对大量数据时体现出更高的时间效率。
问题,How to Implement “Pairs” and “Stripes”in MapReduce?
首先介绍以下Serialization:Process of turning structured objects into a byte stream for transmission over a network or for writing to persistent storage
Requirements:
1)Compact:To make efficient use of storage space
2)Fast:The overhead in reading and writing of data is minimal
3)Extensible:We can transparently read data written in an older format
4)Interoperable:We can read or write persistent data using different language
再介绍以下Writable Interface:Writable is a serializable object which implements a simple, efficient, serialization protocol
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
Writable Interface要求:
1)All values must implement interface Writable
2)All keys must implement interface WritableComparable
3)context.write(WritableComparable, Writable)
3.1)You cannot use java primitives here!!
Writable 再pairs和stripes中的应用:


Design Pattern 3: Order Inversion
在WordCount的时候我们,可能不仅需要统计一对单词组(例如,computer science)的出现次数,而且还要统计它(computer, science)在所有的出现computer的单词对(computer, *)中的出现频率,因此我们需要统计出所有(computer, *)(设为N(Wi, w’))的数量,然后再用(computer, science)(设为N(Wi, wj))出现的次数除以N(Wi, w’)。见下图
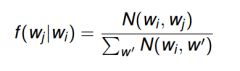
注意:1)N(·,·) is the number of times a co-occurring word pair is observed
2)The denominator is called the marginal
这里有两种方式统计词频:1)Stripes; 2)Pairs (统计词频是在reducer中进行的)
1)Stripes:(这个方法面对的问题是memory,因为所有的stripes的活动都得在内存中进行)
In the reducer, the counts of all words that co-occur with the conditioning variable (wi) are available in the associative array. Hence, the sum of all those counts gives the marginal.
a → {b1:3, b2 :12, b3 :7, b4 :1, … }
f(b1|a) = 3 / (3 + 12 + 7 + 1 + …)
2)Pairs:
Reducer直接接收pairs然后进行词频统计,然而这里有个问题,就是分母必须是在扫描了所有的(wi, *)后才能得到,不然无法进行词频计算。
这里有两种解决方式:
2.1) Fortunately, as for the mapper, also the reducer can preserve state across multiple keys. We can buffer in memory all the words that co-occur with wi and their counts. This is basically building the associative array in the stripes method.(类似于stripes的方式,问题也是memory)
但是这个方法在mapper传来的pairs没有被sort的时候,需要对其先按照(wi, *)的方式进行sort,然后才是(wi, wj)的sort,然而在sort的过程中(即sort(wi, )),我们遍历了所有(wi,)对,所以分母就知道了。(所有的一切都是在memory中进行)
这里还有个问题就是,reducer1可能索取了(wi, wj),reducer2可能索取了(wi, wq),这就会产生词频统计不正确的现象(因为分母错误了),所以我们需要自己设定partitioner来使一个reducer来请求(wi, *)的单词对。这里的partitioner是基于采用hash value的方式,因为hash值是具有身份鉴别功能,所以只需要(wi, *)中的wi的hash value相同,就会被同一个reducer fetch。
2.2)将统计好的marginal先传输给reducer(例如,(pair(wi, *), all_count)),再将各个单词对及其出现次数(pair(wi, wu), count)传输给reducer进行词频计算(即 frequency_of_(wi, wu) = count/all_count)。在这里关键就是properly sequence data presented to reducers,那么我们就需要采用一种叫“order inversion”的方法:
(1)The mapper:
(1.1)additionally emits a “special” key of the form (wi, ∗)
(1.2)The value associated to the special key is one, that represents the contribution of the word pair to the marginal
(1.3)Using combiners, these partial marginal counts will be aggregated before being sent to the reducers
(2)The reducer:
(2.1)We must make sure that the special key-value pairs are processed before any other key-value pairs where the left word is wi (define sort order)
(2.2)We also need to guarantee that all pairs associated with the same word are sent to the same reducer (use partitioner)

方法二的特点:
(1)Memory requirements:
(1.1)Minimal, because only the marginal (an integer) needs to be stored
(1.2)No buffering of individual co-occurring word
(1.3)No scalability bottleneck
(2)Key ingredients for order inversion
(2.1)Emit a special key-value pair to capture the marginal
(2.2)Control the sort order of the intermediate key, so that the special key-value pair is processed first
(2.3)Define a custom partitioner for routing intermediate key-value pairs
Order Inversion:
(1)Common design pattern
(1.1)Computing relative frequencies requires marginal counts
(1.2)But marginal cannot be computed until you see all counts
(1.3)Buffering is a bad idea!
(1.4)Trick: getting the marginal counts to arrive at the reducer before the joint counts
(2)Optimizations
(2.1)Apply in-memory combining pattern to accumulate marginal counts