什么是tree-shaking以及Tree-shaking的前置依赖
关于什么是tree-shaking可以看这篇文章有一个简单介绍。
tree-shaking的目的
简单来说,为了增强用户体验,用户打开页面所需等待的时间是非常重要的一环。而在用户打开页面所需等待的时间,有一部分时间就是用来加载远程文件,包括HTML、JavaScript、CSS以及图片资源等文件。

如图就是淘宝页面在初始加载时所加载的资源,此处只截取部分。
因此,tree-shaking的目的,就是通过减少web项目中JavaScript的无用代码,以达到减少用户打开页面所需的等待时间,来增强用户体验。对于消除无用代码,并不是JavaScript专利,事实上业界对于该项操作有一个名字,叫做DCE(dead code elemination),然而与其说tree-shaking是DCE的一种实现,不如说tree-shaking从另外一个思路达到了DCE的目的。
tree-shaking与dead code elemination
Bad analogy time: imagine that you made cakes by throwing whole eggs into the mixing bowl and smashing them up, instead of cracking them open and pouring the contents out. Once the cake comes out of the oven, you remove the fragments of eggshell, except that’s quite tricky so most of the eggshell gets left in there.
You’d probably eat less cake, for one thing.
That’s what dead code elimination consists of — taking the finished product, and imperfectly removing bits you don’t want. Tree-shaking, on the other hand, asks the opposite question: given that I want to make a cake, which bits of what ingredients do I need to include in the mixing bowl?
关于tree-shaking与DCE的区别,rollup的主要贡献者Rich Harris用做蛋糕这样一个例子来进行对比,假设我们需要用鸡蛋这个原材料来做蛋糕,很显然,我们要的只是鸡蛋里的蛋清或者蛋黄而不是蛋壳,关于如何去除蛋壳,DCE是这样做的:直接把整个鸡蛋放到碗里搅拌做蛋糕,蛋糕做完后再慢慢的从里面挑出蛋壳;相反tree-shaking在开始阶段,就不会把蛋壳放进碗里,而是拿出蛋清和蛋黄放进碗里搅拌,蛋壳呢?蛋壳在一开始就已经丢进垃圾桶里了。
实现tree-shaking的前提条件
首先既然要实现的是减少浏览器下载的资源大小,因此要tree-shaking的环境必然不能是浏览器,一般宿主环境是Node。
其次如果JavaScript是模块化的,那么必须遵从的是ES6 Module规范,而不是CommonJS(由于CommonJS规范所致)或者其他,这是因为ES6 Module是可以静态分析的,故而可以实现静态时编译进行tree-shaking。为什么说是可以静态分析的,是因为ES6制定了以下规范:
Module Syntax
Module :
ModuleBody
ModuleBody :
ModuleItemList
ModuleItemList :
ModuleItem
ModuleItemList ModuleItem
ModuleItem :
ImportDeclaration
ExportDeclaration
StatementListItem
上述语法摘自ECMAScript 2015 spec。
关于ES6模块该写什么不该写什么,ecma-262规范上已经说的很清楚了,ModuleItem里只能包含ImportDeclaration,ExportDeclaration以及StatementListItem,而关于StatemengListItem,规范里又有如下说明:
## Block Syntax
BlockStatement[Yield, Return] :
Block[?Yield, ?Return]
Block[Yield, Return] :
{ StatementList[?Yield, ?Return]opt }
StatementList[Yield, Return] :
StatementListItem[?Yield, ?Return]
StatementList[?Yield, ?Return] StatementListItem[?Yield, ?Return]
StatementListItem[Yield, Return] :
Statement[?Yield, ?Return]
Declaration[?Yield]
刚才说到,一个模块只能包含StatementListItem,ImportDeclaration,ExportDeclaration,而StatementListItem中又不能包含ImportDeclaration,ExportDeclaration。这也就是说import和export语句只能出现在代码顶层,像如下代码是不符合ES6 Modules规范的:
if(a === true){
import func from './func'
}
这样做的目的就是避免让模块分析依赖代码运行,从而促使Modlus可以进行静态解析。
tree-shaking的实践分析
关于tree-shaking的实践分析,有一篇文章介绍的非常好,其从webpack和rollup两个主要的打包工具进行分析,描述了两者之间的异同及局限性。下面就对其进行一个简单的概括和整理。
rollup与webpack的差异
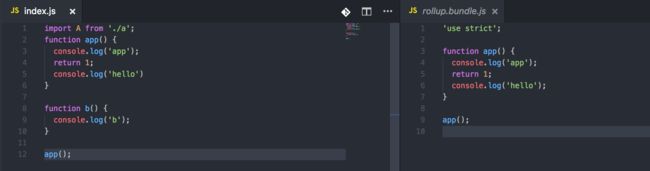
1. 对于单个文件来说,rollup不需要配置插件就可以进行tree-shaking,而webpack要实现tree-shaking必须依赖uglifyJs

左边是原始代码,可以看出该代码真正执行的只有app,函数b并未执行。中间是rollup的打包结果,可以发现rollup的tree-shaking是符合预期的;右侧webpack代码中,app函数和未使用的b函数均被打进webpack.bundle.js文件中。
如果webpack配合uglifyjs插件,结果如下:

可以看到成功移除了无用的b函数。
2. 对于模块化来说,rollup依然可以不依赖其他插件实现tree-shaking,webpack依然依赖uglifyJs。

可以发现,webpack仅仅是通过注释来标识,该模块未使用,要想真正移除,还需要依赖uglifyJs。

假如uglifyJs后成功移除。
局限性
难道tree-shaking真正那么完美吗,并不是,下面就来谈谈局限性。
1. 对于未执行到的代码,单独使用rollup并不能移除,依然需要依赖uglifyJs
上面是未使用uglifyJs的打包结果。

可以发现,通过uglifyJs的配合,rollup成功移除了函数中未执行的代码。
2. 对于依赖运行时才能确定是否会使用代码,tree-shaking无法删除
关于tree-shaking的局限性,这里有篇文章你的Tree-Shaking并没什么卵用,说的不错,但是其有部分内容,在我看来是有一定歧义的。
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
var _createClass = function() {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
descriptor.enumerable = descriptor.enumerable || !1, descriptor.configurable = !0,
"value" in descriptor && (descriptor.writable = !0), Object.defineProperty(target, descriptor.key, descriptor);
}
}
return function(Constructor, protoProps, staticProps) {
return protoProps && defineProperties(Constructor.prototype, protoProps), staticProps && defineProperties(Constructor, staticProps),
Constructor;
};
}()
var Person = function () {
function Person(_ref) {
var name = _ref.name, age = _ref.age, sex = _ref.sex;
_classCallCheck(this, Person);
this.className = 'Person';
this.name = name;
this.age = age;
this.sex = sex;
}
_createClass(Person, [{
key: 'getName',
value: function getName() {
return this.name;
}
}]);
return Person;
}();
我们的Person类被封装成了一个IIFE(立即执行函数),然后返回一个构造函数。那它怎么就产生副作用了呢?问题就出现在_createClass这个方法上,你只要在上一个rollup的repl链接中,将Person的IIFE中的
_createClass调用删了,Person类就会被移除了。
这篇文章以Person类为例,想说代码之所以无法tree-shaking,是因为该代码里含有副作用所以无法移除,以至于你的tree-shaking毫无卵用。然而事实真的是这样吗?
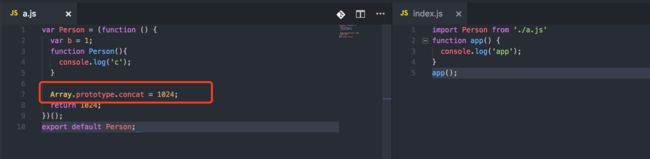
我同样以IIFE为例,来说明。
这里可以看出来,在IIFE中,同样拥有含有副作用的代码,如果按照那篇文章所述,因为代码里有含有副作用的代码,那么即使Person没有被使用,其所有代码依然都会被打进去,导致tree-shaking无任何作用。
下面来看一下rollup的打包结果。
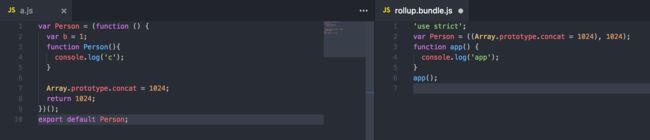
可以发现,tree-shaking后的代码,只保留了有副作用的代码,对于其他无副作用的代码,均被删除。
该文章中Person之所以里面的代码没有被删除,作者的先放一边,让读者感觉似乎只要代码里有副作用,整个代码就无法tree-shaking,其实并不是这样。我们更换代码的写法,会发现有不同的打包结果:


因此,同样的有副作用,有的代码tree-shaking是可以分析出来的,而有的,是难以解析的。
参考链接
1. CommonJS
2. tree-shaking versus dead code elimination
3. ecma-262 sec-modules