因为公司业务需要,之前一段时间开发了一套反垃圾系统,用这篇文章总结下反垃圾系统的设计和开发心得。
为什么需要一个反垃圾系统
在中国互联网环境中,成长到一定规模后的大型网络社区都难以避免地吸引大量垃圾信息,比如政治,招嫖,医疗,枪支广告,外挂信息,理财,房地产等等,这些信息每天都会大量出现。因为公司也算是个比较大的互联网站点,一有点异常信息就有网警找上门来。原本也有接入一些第三方服务,可是第三方服务常常存在各种各样的问题:
1、针对广告变形的识别能力有限

2、 语义分析效果差
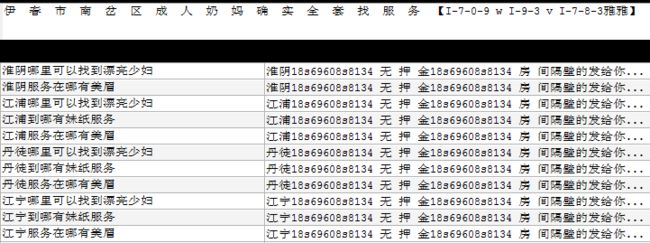
在被刷了这些广告后,和对方的开发沟通过,对方的答案是
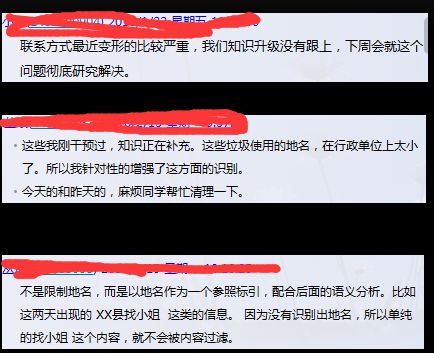
简单的说,也就是,找小姐单独出现,系统并不判断为异常,只有当地名作为参照出现才会判定,如果地名的库不全那就无能为力。语义分析看着是个很完美的方案,可是对于刷广告的人的,他的目的是联系方式和关键词在搜索引擎中能够出现,他们完全可以用一些根本没有任何关联的语句来刷,让语义分析失效。
比如
标题:妹 子 烟 台 东 山 微 信 陌 陌
内容: 1下8 功6 夫9 符6 合0 法8 规8 和1 法3 国4 发 给 的 法 规 合 法 化
像内容里这段有什么语义可言?
从头构建一个反垃圾系统
1、基于敏感词库的过滤
反垃圾系统最简单有效的方式就是通过敏感词库对信息进行判定。具体的执行方式就是对待检测文本通过一次扫描找出其中存在的敏感词,Trie tree这种数据结构对于这种需求非常合适。
维基百科:trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
https://zh.wikipedia.org/wiki/Trie
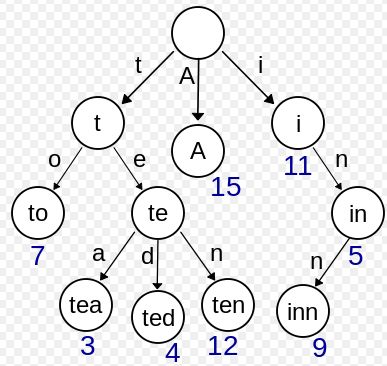
这幅图可以很清楚的说明工作原理。
在此基础上,针对中文环境以及常见的干扰,我对数据结构做了一些扩展
1、扩展了对拼音混合拼写的识别
例如:毛ze东,fan(反)共,找xiaojie(小姐)
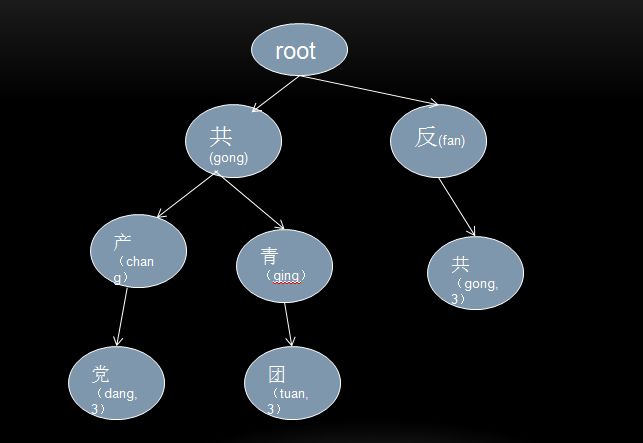
2、扩展了敏感词级别,增加了敏感词的参照标记,方便以后对文本整体敏感度的计算
例如:小姐单纯看是个中性词,可是如果同时存在微信号,手机号等联系关系时,就可以判定为广告信息。
基本结构类似下图
trie可以用多种方式实现,常见实现里基于字典的方式内存占用大但是易理解易调试,Double Array Trie的实现则能减少空间的浪费。可以根据自己的实际情况采用。
可以参考 双数组Trie树(DoubleArrayTrie)Java实现
2、行为检测
针对文本的检测直接有效,但是也是最容易被干扰的。特殊字符,火星文,繁体,偏旁部首拆分,如果单纯靠词库只能是疲于奔命,但是仔细观察广告数据可以发现很多共同的特征:短时间,大批量,相似内容。
比如刷招嫖,医院内信息都是几个ip或者几个id大量发布内容,而且内容相似程度极高

不管内容如何变,发布垃圾信息的行为模式是没法掩饰的,针对行为做检查可以很好的补充关键词检查的不足。比如对ip,id还有内容的文本近似程度做检测:一个ip或者id,1分钟内发布的消息数超过一定数量,而且这些消息的文本相似程度极高,可以在后台提出预警,方便管理员屏蔽。
还可以对某个时段内站点进入信息的基于文本相似程度的归类统计,做到提前发现,方便管理员统一处理。其实做到这一步就有些机器学习的味道在里面。
文本的相似度检测有很多算法,python也有现成的库可以使用,不在赘述。
3、用户历史数据的挖掘分析
反垃圾系统最头痛的就是太松,垃圾一堆,太严格又容易错杀。尤其作为一个娱乐为主的网站,有的时候一些打擦边球,但是无害的内容容易被错杀。由于拥有用户发表过的数据,发布频率,可以在此基础上做很多有价值的挖掘,做到更精细的检测。比如如果是表现良好的用户,发布的内容中有低危害等级的敏感词,可以放宽检测标准。
小结
这就是个道高一次魔高一丈的较量,要做到比较好的效果必然是多维度的检测,这里只是一些抛砖引玉的心得,优化一直在路上。