1. 研究背景和动机
卷积神经网络的趋势是建立更深更复杂的网络,但是在诸如机器人、自动驾驶汽车和增强现实等许多现实世界的应用中,需要在计算资源有限的移动或嵌入式平台实时运行。因此,迫切需要一种轻量、低延迟模型来满足这些场景的需要。
目前,构建小型神经网络通常有以下两类方法:
压缩预训练的网络:
Product quantization,Vector quantization,Distillation,Hashing,Huffman coding.直接训练小型网络:卷积分解, 如
Flattened networks,Factorized Networks,Xception network,Squeezenet.
已有模型大多只注重大小,却忽视了速度。而MobileNet同时关注延迟的优化,是一种轻量高效的CNN。
2. MobileNet架构
2.1 深度可分离卷积
同Xception一样,MobileNet也是以深度可分离卷积(Depthwise Separable Convolution)作为核心层来进行构建的。一个标准卷积层即 filter 特征也 combine 特征,作为分解卷积的一种形式,如图2所示,深度可分离卷积将一个标准卷积层分解成了:
-
depthwise convolution(filtering step):每个输入通道都对应一个单独的滤波器 -
pointwise convolution(combination step):这是一个1 × 1的卷积,对depthwise convolution的输出进行linear combination

假设输入特征图 F大小为
滤波器的长宽为
-
对于标准卷积层,卷积核 K 大小为
输出特征图 G根据如下公式计算:
因此,标准卷积的计算量为
-
对于
深度可分离卷积-
第一层
depthwise convolution的卷积核大小为输出特征图可由如下公式计算: 计算量为
计算量为
-
第二层
pointwise convolution的卷积核大小为计算量为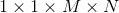 因此,总计算量为
因此,总计算量为

-
这样,深度可分离卷积与标准卷积的计算量比率为

depthwise convolution使用3 × 3的滤波器,所以计算量可以减小为原来的 8 ~ 9 倍(1/N + 1/9)。
2.2 网络结构和训练
MobileNet总的结构如表1所示,如果把depthwise convolution和pointwise convolution都看作单独的层,则一共有28层。其中,第一层是标准的卷积层,利用步长为2的卷积对特征图下采样,最后还在全连接层前用平均池化将特征图减小到1 × 1。此外,如图3所示,除了最后的全连接层所有层后都跟了batchnorm和ReLU激活函数。


并不是减小了乘-加次数的模型就一定快,由于卷积通常都是被转换成GEMM(general matrix multiply)来实现,这就需要先进行im2col将一个图像转为相应矩阵。然而,如表2所示,MobileNet中几乎95%的计算都是1 × 1的卷积,这不需要执行im2col就可以直接执行GEMM,因此,MobileNet的卷积实现非常高效,这就为加快模型速度提供了保证。

MobileNet使用TensorFlow进行训练,并用RMSprop进行优化。由于小模型通常不用担心过拟合,MobileNet使用了很少的正则化和数据增强。此外,作者发现在depthwise convolution应该使用很少或者不用L2正则化,因为那里的参数很少(只占1.06%)。
2.3 Width Multiplier
尽管基础的MobileNet架构已经很小很快了,但很多实际场景的要求更苛刻,这就引入了Width Multiplier: α∈ (0, 1],这个简单的超参是用来均匀地将所有层变得更瘦,即将每个层的输入通道变为 αM、输出通道变为 αN,因此计算量就变为
2.4 Resolution Multiplier
引入的第二个超参为Resolution Multiplier: ρ∈ (0, 1],它是为了降低输入图像和内部表示的分辨率继而进一步加快MobileNet的速度,但在实践中它是通过设置输入图像的分辨率而隐式地设置。
当同时使用了上述两个超参时,计算量变为
通过表3,我们可以直观的看出不断累积使用深度可分离卷积、Width Multiplier、Resolution Multiplier对计算量和参数数量带来的改善。

3. 实验
3.1 MobileNets的模型选择

小身材,大拳头:使用深度可分离卷积的MobileNet比使用标准卷积层的MobileNet仅仅减少了1%的accuracy,但是减少了大量的计算量和参数。
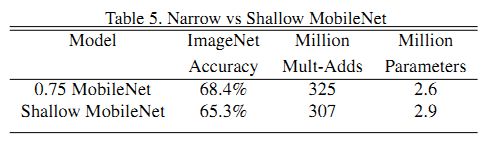
宁窄毋浅:MobileNet使用Width Multiplier参数后比缩减层数的MobileNetaccuracy高3%。
3.2 模型压缩超参数
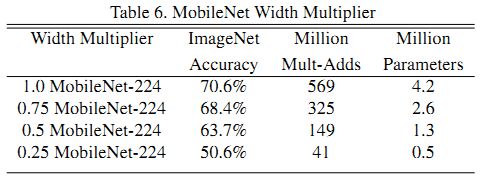
由表6可见,accuracy随着Width Multiplier参数的变小均匀减小,直到参数为0.25时accuracy有明显得下降。

由表7可见,accuracy随着Resolution Multiplier参数的变小均匀变小。


图4和图5显示了使用Width Multiplier参数(1,0.75,0.5,0.25)和Resolution Multiplier参数即分辨率(224,192,160,128)时,在ImageNet上accuracy和计算量与参数数量的关系。

表8和表9分别显示了MobileNet和精简了的MobileNet与流行模型的对比。可以看出,其accuracy和其它模型不相上下,而计算量却大大减少。
3.3 细粒度识别(Fine Grained Recognition)

MobileNet先使用很大却有噪声的网络数据预训练一个识别模型,然后使用Stanford Dogs数据集进行微调。结果显示,MobileNet在accuracy相差不大的情况下,计算量和模型尺寸都大大减少。
3.4 大范围地理定位
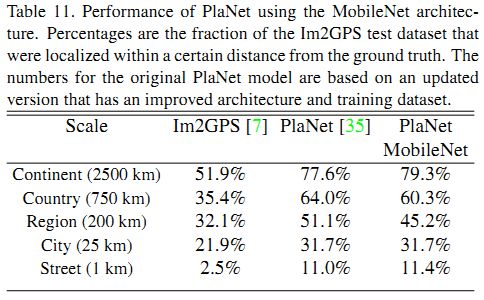
作者基于MobileNet架构,使用相同的数据,重新训练了PlaNet。结果显示,MobileNet版本仅仅减少了一点点accuracy,换来了计算量的大幅减少和更紧凑的模型。更重要的是,其表现仍然比Im2GPS好很多。
3.5 人脸属性分类
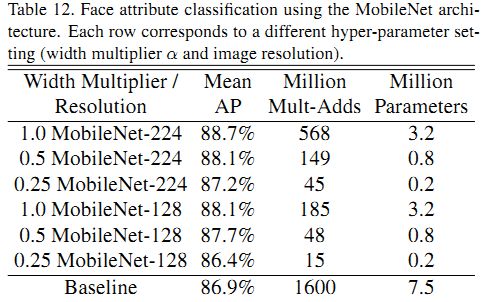
可以通过结合MobileNet和Distillation来压缩一些复杂的模型。作者通过MobileNet模仿大型模型的输出而不是人工标记的数据提取了一个人脸属性分类器,模型结合了MobileNet的精简参数和Distillation的可伸缩性,得到的结果如表12所示。其mAP和基准类似,计算量却只有基准模型的1%。
3.6 物体检测

表13显示了在Faster-RCNN和SSD框架下,MobileNet与VGG和Inception V2的对比。在两个框架下,MobileNet的结果与其他网络类似,但是计算量和模型都较小。
3.7 Face Embeddings

采用Distillation方法,通过最小化MobileNet与FaceNet的输出平方误差来训练MobileNet,得到的结果如表14。其accuracy稍低,但是计算量小。
4.总结
MobileNet基于深度可分离卷积,引入Width Multiplier(减少feature map数量)和Resolution Multiplier(缩小feature map大小)参数构建更小更快的移动网络,可通过牺牲合适的精度来减小尺寸和延迟。文中的实验结果表明,MobileNet具有较好的速度和准确度特征,并且能够胜任各种任务。