早在小学时我们就学过名词、动词、形容词和副词之间的差异。这些“词类”不是闲置的文法家的发明,而是对许多语言处理任务都有用的分类。正如我们将看到的,这些分类源于对文本中词的分布的简单的分析。
将单词按它们的词性分类并进行相应地标注的过程,称为词语性质标注、词性标注或简称标注。词性也称为词类或词汇类别。用于特定任务的标记的集合被称为一个标记集。我们在本章的重点是运用标记和自动标注文本。
一、使用词性标注器
text = nltk.word_tokenize("And now for something completely different")
nltk.pos_tag(text)
>> [('And', 'CC'),
('now', 'RB'),
('for', 'IN'),
('something', 'NN'),
('completely', 'RB'),
('different', 'JJ')]
and是CC,并列连词;now和completely是RB,副词;for是IN,介词;something是NN,名词;different是JJ,形容词
text = nltk.word_tokenize("They refuse to permit us to obtain the refuse permit")
nltk.pos_tag(text)
>> [('They', 'PRP'),
('refuse', 'VBP'),
('to', 'TO'),
('permit', 'VB'),
('us', 'PRP'),
('to', 'TO'),
('obtain', 'VB'),
('the', 'DT'),
('refuse', 'NN'),
('permit', 'NN')]
请注意:refuse和permit都以现在时动词(VBP)和名词(NN)形式出现。例如refUSE是一个动词,意为“拒绝”,而REFuse是一个名词,意为“垃圾”(即它们不是同音词)。因此,我们需要知道正在使用哪一个词以便能正确读出文本。
汇类别如“名词”和词性标记如NN,看上去似乎有其用途,但好像却不是那么容易让人明白它们的用途。
text = nltk.Text(word.lower() for word in nltk.corpus.brown.words())
text.similar('woman')
>> man time day year car moment world house family child country boy
state job place way war girl work word
text.similar('bought')
>> made said done put had seen found given left heard was been brought
set got that took in told felt
text.similar('over')
>> in on to of and for with from at by that into as up out down through
is all about
text.similar('the')
>> a his this their its her an that our any all one these my in your no
some other and
上面是一个查找相似词的程序,可以观察到,搜索woman找到名词;搜索bought找到的大部分是动词;搜索over一般会找到介词;搜索the找到几个限定词。一个标注器能够正确识别一个句子的上下文中的这些词的标记,例如The woman bought over $150,000 worth of clothes。
一个标注器还可以为我们对未知词的认识建模,例如我们可以根据词根scrobble猜测scrobbling可能是一个动词,并有可能发生在he was scrobbling这样的上下文中。
二、标注语料库
1. 表示已标注的标识符
按照 NLTK 的约定,一个已标注的标识符使用一个由标识符和标记组成的元组来表示。 我们可以使用函数 str2tuple()从表示一个已标注的标识符的标准字符串创建一个这样的特殊元组:
tagged_token = nltk.tag.str2tuple('fly/NN')
tagged_token
>> ('fly', 'NN')
2. 读取已标注的语料库
只要语料库包含已标注的文本,NLTK的语料库接口都将有一个tagged_words()方法,使用该方法,我们就可以得到 [('The', 'AT'), ('Fulton', 'NP-TL'), ...] 这种形式的文章。
nltk.corpus.brown.tagged_words()
语料类一共提供了下列方法可以返回预标注数据:

并非所有的语料库都采用同一组标记;看前面提到的标记集的帮助函数和readme()方法中的文档。最初,我们想避免这些标记集的复杂化,所以我们使用一个内置的到“通用标记集“的映射:
nltk.corpus.brown.tagged_words(tagset='universal')


如果语料库也被分割成句子,将有一个tagged_sents()方法将已标注的词划分成句子,而不是将它们表示成一个大列表。也就是说,词还是以(词,POS)的形式出现,但是会以一个句子一个列表的形式进行存放。
3. 各类词性
名词:一般指的是人、地点、事情或概念,例如:女人、苏格兰、图书、情报。名词可能 出现在限定词和形容词之后,可以是动词的主语或宾语
动词:是用来描述事件和行动的词,例如:fall 和 eat。在一个句子中,动词通常表示涉及一个或多个名词短语所指示物的关系。
形容词:形容词修饰名词,可以作为修饰符(如:the la rge pizza中的large)或谓语(如:the pizza is large)。英语形容词可以有内部结构(如:t he falling stocks 中的 fall+ing)。
副词:副词修饰动词,指定时间、方式、地点或动词描述的事件的方向(如:the stocks fell quickly 中的 quickly)。副词也可以修饰的形容词(如:Mary’ s teacher was really nice 中的 really)。
英语中还有几个封闭的词类,如介词,冠词(也常称为限定词)(如:the,a),情态动 词(如:should,may),人称代词 (如:she,they)。每个词典和语法对这些词的分类都不同。
三、使用 Python 字典映射词及其属性
略
四、自动标注
1. 默认标注器
为每个标识符分配同样的标记:
# 寻找最可能的标记
tags = [tag for (word, tag) in brown.tagged_words(categories='news')]
nltk.FreqDist(tags).max()
>> 'NN'
raw = 'I do not like eggs and ham, I do not like them Sam I am'
tokens = nltk.word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')# 创建一个将所有词都标注成 NN 的标注器
print(default_tagger.tag(tokens)) # 调用tag()方法进行标注
print(default_tagger.evaluate(brown_tagged_sents)) # 使用默认
默认的标注器给每一个单独的词分配标记,即使是之前从未遇到过的词。碰巧的是,一旦我们处理了几千词的英文文本之后,大多数新词都将是名词。正如我们将看到的,这意味 着,默认标注器可以帮助我们提高语言处理系统的稳定性。
2. 正则表达式标注器
正则表达式标注器基于匹配模式分配标记给标识符。
例如:我们可能会猜测任一以 ed 结尾的词都是动词过去分词,任一以's 结尾的词都是名词所有格。可以用一个正则表达式的列表表示这些:
>>> patterns = [
... (r'.*ing$', 'VBG'), # gerunds
... (r'.*ed$', 'VBD'), # simple past
... (r'.*es$', 'VBZ'), # 3rd singular present
... (r'.*ould$', 'MD'), # modals
... (r'.*\'s$', 'NN$'), # possessive nouns
... (r'.*s$', 'NNS'), # plural nouns
... (r'^-?[0-9]+(.[0-9]+)?$', 'CD'), # cardinal numbers
... (r'.*', 'NN') # nouns (default)
... ]
regexp_tagger = nltk.RegexpTagger(patterns)
print(regexp_tagger.tag(tokens))
print(regexp_tagger.evaluate(brown_tagged_sents))
3. 查询标注器
找出 n 个最频繁的词,存储它们最有可能的标记。 然后就可以使用这个信息作为“查找标注器”(NLTK UnigramTagger)的模型。不在频繁词中的词分配默认标记 NN。
换句话说,先使用查找表,如果它不能指定一个标记就使用默认标注器,这个过程叫做回退。
fd = nltk.FreqDist(brown.words(categories="news"))
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories="news"))
most_freq_words = fd.most_common(100)
likely_tags = dict((word, cfd[word].max()) for (word,times) in most_freq_words)
baseline_tagger = nltk.UnigramTagger(model=likely_tags, backoff=nltk.DefaultTagger('NN'))
print(baseline_tagger.tag(tokens))
print(baseline_tagger.evaluate(brown_tagged_sents))
五、N-gram 标注
1. 一元标注( Unigram Tagging)
一元标注器基于一个简单的统计算法:对每个标识符分配这个独特的标识符最有可能的标记。
例如: 它将分配标记 JJ 给词 frequent ,因为 frequent 用作一个形容词(例 如:a frequent word)比用作一个动词(例如:I frequent this cafe)更常见。
from nltk.corpus import brown
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
unigram_tagger = nltk.UnigramTagger(brown_tagged_sents)
unigram_tagger.tag(brown_sents[2007])
2. 一般的 N-gram 的标注
一个 n-gram 标注器是一个 unigram 标注器的一般化,它的上下文是当前词和它前面 n- 1 个标识符的词性标记。如下图所示:要选择的标记是圆圈里的 tn,灰色阴影的是上下文。
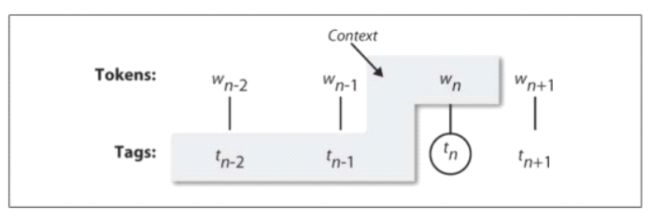
在上面的n-gram 标注器的例子中,让 n= 3,也就是说,考虑当前词的前两 个词的标记。一个 n-gram 标注器挑选在给定的上下文中最有可能的标记。
# 一般的N-gram标注器(代码为二元)
size = int(len(brown_tagged_sents)*0.9)
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size+1:]
bigram_tagger = nltk.BigramTagger(train_sents)
print(bigram_tagger.tag(tokens))
print(bigram_tagger.evaluate(test_sents))
3. 组合标注器
解决精度和覆盖范围之间的权衡的一个办法是尽可能的使用更精确的算法,但却在很多 时候落后于具有更广覆盖范围的算法。例如:可以按如下方式组合 bigram 标注器、uni gram 标注器和一个默认标注器:
- 尝试使用二元标注器标注标识符。
- 如果二元标注器无法找到一个标记,尝试一元标注器。
- 如果一元标注器也无法找到一个标记,使用默认标注器。
大多数NLTK标注器允许指定一个回退标注器。回退标注器自身可能也有一个回退标注器:
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents,backoff=t0)
t2 = nltk.BigramTagger(train_sents,backoff=t1)
t2.evaluate(test_sents)
注意:对于例如trigram的标注器会使用前两个标识符的词性,但有时会遇到前两个词是上一句话的最后一个单词和句子结尾的标点符号。通常,前一句结尾的词的类别和下一句的开头的词性没有什么关系,为了避免这种跨句子边界标注的问题,常通过已标记的tagged_sents(也就是按句子进行处理的语料)来训练标注器。
六、标注生词
标注生词的方法仍然是回退到一个正则表达式标注器或一个默认标注器。这些都无法利用上下文。因此,如果标注器遇到词blog,训练过程中没有看到过,它会分配相同的标记,不论这个词出现的上下文是the blog还是to blog。我们怎样才能更好地处理这些生词,或词汇表以外的项目?
一个有用的基于上下文标注生词的方法是限制一个标注器的词汇表为最频繁的 n 个词, 使用 5.3 节中的方法替代每个其他的词为一个特殊的词 UNK。训练时,一个 unigram 标注器可能会学到 UNK 通常是一个名词。然而,n-gram 标注器会检测它的一些其他标记中的上下文。例如:如果前面的词是 to(标注为 TO),那么 UNK 可能会被标注为一个动词。
七、存储标注器
在大语料库上训练一个标注器可能需要大量的时间。没有必要在每次我们需要的时候训练一个标注器,很容易将一个训练好的标注器保存到一个文件以后重复使用。让我们保存我们的标注器t2到文件t2.pkl。
# 保存
from pickle import dump
output = open('t2.pkl', 'wb')
dump(t2, output, -1)
output.close()
# 加载
from pickle import load
input = open('t2.pkl', 'rb')
tagger = load(input)
input.close()
八、 基于转换的标注
n-gram标注器的一个潜在的问题是它们的n-gram表(或语言模型)的大小。如果使用各种语言技术的标注器部署在移动计算设备上,在模型大小和标注器准确性之间取得平衡是很重要的。使用回退标注器的n-gram标注器可能存储trigram和bigram表,这是很大的稀疏阵列,可能有数亿条条目。
第二个问题是关于上下文。n-gram标注器从前面的上下文中获得的唯一的信息是标记,虽然词本身可能是一个有用的信息源。n-gram模型使用上下文中的词的其他特征为条件是不切实际的。在本节中,我们考察Brill标注,一种归纳标注方法,它的性能很好,使用的模型只有n-gram标注器的很小一部分。
Brill标注是一种基于转换的学习,以它的发明者命名。一般的想法很简单:猜每个词的标记,然后返回和修复错误。在这种方式中,Brill标注器陆续将一个不良标注的文本转换成一个更好的。与n-gram标注一样,这是有监督的学习方法,因为我们需要已标注的训练数据来评估标注器的猜测是否是一个错误。然而,不像n-gram标注,它不计数观察结果,只编制一个转换修正规则列表。
Brill标注的的过程通常是与绘画类比来解释的。假设我们要画一棵树,包括大树枝、树枝、小枝、叶子和一个统一的天蓝色背景的所有细节。不是先画树然后尝试在空白处画蓝色,而是简单的将整个画布画成蓝色,然后通过在蓝色背景上上色“修正”树的部分。以同样的方式,我们可能会画一个统一的褐色的树干再回过头来用更精细的刷子画进一步的细节。Brill标注使用了同样的想法:以大笔画开始,然后修复细节,一点点的细致的改变。
让我们看看下面的例子:
The President said he will ask Congress to increase grants to states for vocation al rehabilitation.
(总统表示他将要求国会增加拨款给各州用于职业康复。)
我们将学习到两个规则的运作:
- 当前面的词是 TO 时,替换 NN 为 VB
- 当下一个标记是 NNS 时,替换 TO 为 IN
下图说明了这一过程,首先使用 unigram 标注器标注, 然后运用规则修正错误:

在此表中,我们看到两个规则。所有这些规则由以下形式的模板产生:“ 替换 T1 为 T2在上下文 C 中。” 典型的上下文是之前或之后的词的内容或标记,或者当前词的两到三个词 范围内出现的一个特定标记。在其训练阶段,T1,T2 和 C 的标注器猜测值创造出数以千计 的候选规则。每一条规则都根据其净收益打分:它修正的不正确标记的数目减去它错误修改的正确标记的数目。
Brill 标注器的另一个有趣的特性:规则是语言学可解释的。与采用潜在的巨大的 n-gra m 表的 n-gram 标注器相比,我们并不能从直接观察这样的一个表中学到多少东西,而 Brill 标注器学到的规则可以。
Brill标注器演示:标注器有一个“X→Y如果前面的词是Z”的形式的模板集合;这些模板中的变量是创建“规则”的特定词和标记的实例;规则的得分是它纠正的错误例子的数目减去正确的情况下它误报的数目;除了训练标注器,演示还显示了剩余的错误:
nltk.tag.brill.demo()
Training Brill tagger on 80 sentences...
Finding initial useful rules...
Found 6555 useful rules.
B |
S F r O | Score = Fixed - Broken
c i o t | R Fixed = num tags changed incorrect -> correct
o x k h | u Broken = num tags changed correct -> incorrect
r e e e | l Other = num tags changed incorrect -> incorrect
e d n r | e
------------------+-------------------------------------------------------
12 13 1 4 | NN -> VB if the tag of the preceding word is 'TO'
8 9 1 23 | NN -> VBD if the tag of the following word is 'DT'
8 8 0 9 | NN -> VBD if the tag of the preceding word is 'NNS'
6 9 3 16 | NN -> NNP if the tag of words i-2...i-1 is '-NONE-'
5 8 3 6 | NN -> NNP if the tag of the following word is 'NNP'
5 6 1 0 | NN -> NNP if the text of words i-2...i-1 is 'like'
5 5 0 3 | NN -> VBN if the text of the following word is '*-1'
...
>>> print(open("errors.out").read())
left context | word/test->gold | right context
--------------------------+------------------------+--------------------------
| Then/NN->RB | ,/, in/IN the/DT guests/N
, in/IN the/DT guests/NNS | '/VBD->POS | honor/NN ,/, the/DT speed
'/POS honor/NN ,/, the/DT | speedway/JJ->NN | hauled/VBD out/RP four/CD
NN ,/, the/DT speedway/NN | hauled/NN->VBD | out/RP four/CD drivers/NN
DT speedway/NN hauled/VBD | out/NNP->RP | four/CD drivers/NNS ,/, c
dway/NN hauled/VBD out/RP | four/NNP->CD | drivers/NNS ,/, crews/NNS
hauled/VBD out/RP four/CD | drivers/NNP->NNS | ,/, crews/NNS and/CC even
P four/CD drivers/NNS ,/, | crews/NN->NNS | and/CC even/RB the/DT off
NNS and/CC even/RB the/DT | official/NNP->JJ | Indianapolis/NNP 500/CD a
| After/VBD->IN | the/DT race/NN ,/, Fortun
ter/IN the/DT race/NN ,/, | Fortune/IN->NNP | 500/CD executives/NNS dro
s/NNS drooled/VBD like/IN | schoolboys/NNP->NNS | over/IN the/DT cars/NNS a
olboys/NNS over/IN the/DT | cars/NN->NNS | and/CC drivers/NNS ./.
# 基于转换的标注器
from nltk.tbl.template import Template
from nltk.tag.brill import Pos, Word
from nltk.tag import untag, RegexpTagger, BrillTaggerTrainer
size = int(len(brown_tagged_sents)*0.9)
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size+1:]
# baseline
unigram_tagger = nltk.UnigramTagger(train_sents)
# 建立转换的标注器
#clear any templates created in earlier tests
Template._cleartemplates()
templates = [Template(Pos([-1])), Template(Pos([-1]), Word([0]))]
#construct a BrillTaggerTrainer
tt = BrillTaggerTrainer(unigram_tagger, templates, trace=3)
tagger1 = tt.train(train_sents, max_rules=10)
# 查看规则
print(tagger1.rules()[1:3])
print(tagger1.evaluate(test_sents))
九、中文标注小demo
例子来自于 zzulp 处,基于Unigram训练一个中文词性标注器,语料使用网上可以下载得到的人民日报98年1月的标注资料:语料下载
# coding=utf-8
import nltk
lines = open('199801.txt', "r", encoding='utf-8').readlines()
all_tagged_sents = []
for line in lines:
sent = line.split()
tagged_sent = []
for item in sent:
pair = nltk.str2tuple(item)
tagged_sent.append(pair)
if len(tagged_sent)>0:
all_tagged_sents.append(tagged_sent)
train_size = int(len(all_tagged_sents)*0.8)
x_train = all_tagged_sents[:train_size]
x_test = all_tagged_sents[train_size:]
tagger = nltk.UnigramTagger(train=x_train,backoff=nltk.DefaultTagger('n'))
tokens = nltk.word_tokenize(u'我 认为 不丹 的 被动 卷入 不 构成 此次 对峙 的 主要 因素。')
tagged = tagger.tag(tokens)
print(tagged)
print(tagger.evaluate(x_test)) #0.871
十、如何确定一个词的分类
1. 形态学线索
一个词的内部结构可能为这个词分类提供有用的线索。举例来说:-ness是一个后缀,与形容词结合产生一个名词,如happy → happiness, ill → illness。如果我们遇到的一个以-ness结尾的词,很可能是一个名词。同样的,-ment是与一些动词结合产生一个名词的后缀,如govern → government和establish → establishment。
英语动词也可以是形态复杂的。例如,一个动词的现在分词以-ing结尾,表示正在进行的还没有结束的行动(如falling, eating)。-ing后缀也出现在从动词派生的名词中,如the falling of the leaves(这被称为动名词)。
2. 句法线索
另一个信息来源是一个词可能出现的典型的上下文语境。例如,假设我们已经确定了名词类。那么我们可以说,英语形容词的句法标准是它可以立即出现在一个名词前,或紧跟在词be或very后。
3. 语义线索
一个词的意思对其词汇范畴是一个有用的线索。例如:名词的众所周知的一个定 义是根据语义的:“一个人、地方或事物的名称。”在现代语言学,词类的语义标准受到怀疑, 主要是因为它们很难规范化。然而,语义标准巩固了我们对许多词类的直觉,使我们能够在不熟悉的语言中很好的猜测词的分类。
例如:如果我们都知道荷兰语词 verjaardag 的意思与 英语词 birthday 相同,那么我们可以猜测 verjaardag 在荷兰语中是一个名词。然而,一些修 补是必要的:虽然我们可能翻译 zij is vandaag jarig as it’s her birthday today,词 jarig 在荷兰语中实际上是形容词,与英语并不完全相同。
参考:
- Python自然语言处理
- https://blog.csdn.net/zzulp/article/details/77164988
- https://www.cnblogs.com/AsuraDong/archive/2017/06/13/6995808.html