写在前面的话
Stay Hungry Stay Foolish!!!
每天进步一点点!!!
《每日一读》是博主每日学习的一篇文章所记录的笔记,大多数是提取文章中关键内容而成;文章类型不限,内容不限。
意义:培养自己的阅读能力,学习更多的知识
郑重声明:如果涉及到文章侵权深感抱歉,请及时联系我我会第一时间删除,谢谢!!
总结
收获:
- 去中心化的节点通信:很好的将现实中找人的模式来实现。
- 距离计算使用XOR的巧妙之处
正文
- How we built a BitTorrent-like P2P network from scratch
背景
三位IT大神由于对P2P网络及分布式系统感兴趣,于是就用Ruby开发了BitTorrent(BT)的系统。
ps:值得学习的精神,从事IT行业的人员不得不具备的一个元素,否则很容易被后浪给拍死
研究
P2P网络的两代网络架构:
1) 集中式系统:通过中央索引服务器来索引到所有文件信息,这里举例的是Napster
- 中央索引服务器:包含所有Node持有的文件信息
- Node节点:存储了文件信息

【缺点】
- 中央服务器易受攻击
- 存在单点故障的风险
- 缺乏可扩展性
2)去中心化系统:每个Node节点充当客户端/服务端,维护自己的文件查找索引片段;Node之间可通信
典型系统:BitTorrent、Gnutella、Freenet

建设
P2P网络构建的基础条件:
- 分布式哈希表(DHT)
- 文件切分/索引机制
- 节点通信机制
分布式哈希表
几种分布式哈希表
- Chord
- Pastry
- Apache Cassandra
- Kademlia
这里选用的是Kademlia,原因:
- 普及率
- 最简单的远程过程调用
- 信息的自动传播
涉及到的概念:
- 节点
- 路由表
- 桶(buckets)
- 异或距离
- 路由算法
- 远程过程调用(remote procedure calls, RPC)
Kademlia
一个Kademlia由许多节点组成
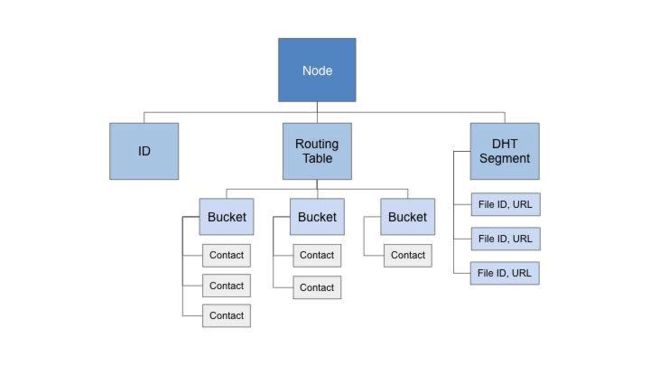
1)节点信息:
- 具有唯一的160位ID
- 维护包含其他节点联系信息的路由表:路由表被划分为
桶,其包含与当前节点的特定距离的节点的联系信息- 联系信息包含其他节点的ID、IP地址和端口号
- 维护较大的分布式哈希表中那些自己的段
- 通过4个远程过程调用与其他节点通信
2)节点通信:
-
PING:探活 -
FIND NODE:需要特定节点的ID;- 查找过程:路由表查找,并返回一组最接近的该ID的联系节点
-
FIND VALUE:需要特定文件的ID;- 查找过程:从分布式哈希表段中查找,找到则返回value;否则返回最接近该文件ID的联系节点列表
-
STORE:在分布式哈希表段中存储key/value对(file_id/location),并更新彼此的联系信息
3)寻找对等点和文件
如果一个节点要从网络中检索一条信息(一个文件),其过程为:
- 该节点发送 FIND VALUE 的远程过程调用到它自己的联系节点子集,这些联系节点的 ID 与它要查找的文件的 ID“最为接近”。
- 如果任何接收节点在其分布式哈希表段中有这个 ID,则它们将返回相应的 value,
- 否则,它们将返回更接近所查询的 value 的节点列表。
4)距离的计算
节点之间的距离定义为节点ID的按位异或(XOR)
注:之后的运算基于4位秘钥空间的节点(只有0~15的ID是可能的)
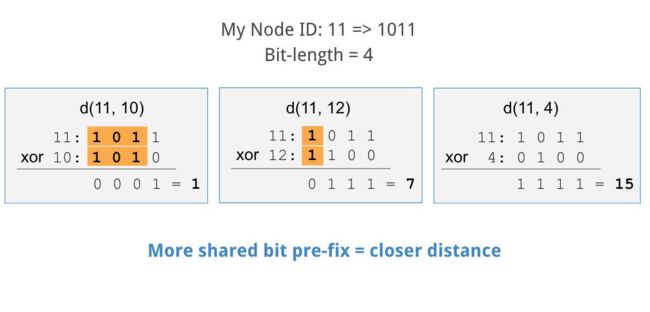
XOR度量的一个重要特征:如果节点 ID 和当前节点的 ID 的二进制表示所共有的位相同个数越多,那么计算得到的 XOR 结果就越小。
ps:使用XOR最大的意义莫过于能更好的划分桶,使得一个桶中的ID具有连续性,联系程度越高
5)网络及路由表
Kademlia网络是由二叉树构成,其查找的时间复杂度为O(log n)
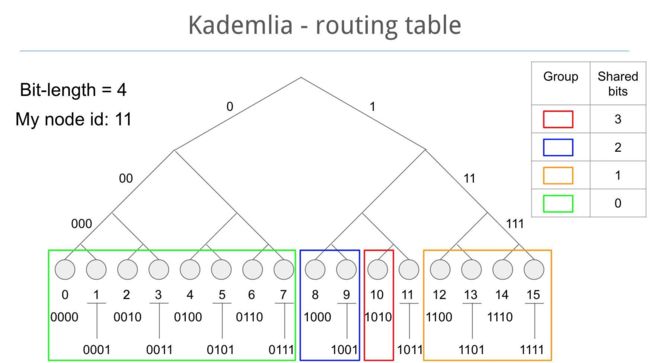
路由表:之前提到路由表被划分为桶,桶划分的过程:
划重点:每个桶中包含了一定距离的节点,而距离就是共享位长度,是通过节点ID和当前ID进行XOR运算得到
举个栗子,假设当前节点ID为11,则桶分布为:
- bukets0:0-7
- bukets1:12-15
- bukets2:8-9
- bukets3:10
解释:其 ID 与当前节点共享前 3 位前缀的节点存储在一个桶中,而 ID 与当前节点共享前 2 位前缀的节点存储在另一个桶中,以此类推。
11的二进制为:1011
10的二进制为:1010,与1011共享位为3位
8-9共享位为2位
12-15共享位为1位
0-7共享位为0位
6)文件切分和检索
文件切分是将文件切分成更小的片段,命名为切片,并将 files/names 记录在一个清单文件(即种子)中,这样它们就可以按照适当的顺序检索和重新合并。
文件切分提高了 P2P 网络的分布性和可靠性,因为多个节点可以存储共享文件的部分或全部切片。如果包含切片下载信息的节点离线了,此时可以从不同的源检索该切片信息。
文件切分还可以节省网络带宽,共享潜在大文件的负载分布在许多节点中。

过程:
- 计算文件内容的
SHA1哈希值作为ID,ID被用作种子的文件名,扩展名为”.xro“ - 原始文件被切分成
1MB块,如果文件小于1MB,则切分为原始文件大小的50% - 切片被写入磁盘,名称即为其内容的
SHA1哈希值;并将名称按顺序写入种子文件,以及原始文件名和文件大小 - 种子和切片位置信息通过 STORE 远程过程调用广播给对等节点。对于每个 shard/manifest,宿主节点在自己的路由表中查找与文件 ID 最接近的节点。这些对等节点都接收包含文件的 ID 和位置的 STORE 远程过程调用。
种子内容json格式:
{
// 真实的文件名
"file_name" : "",
// 文件大小
"length" : 1000,
"pieces" : [
// 切片顺序写入的SHA1哈希值
]
}
开发
开发策略:从本地环境模拟并扩展网络应用到真实网络
1)测试模式:
- 本地沙箱测试
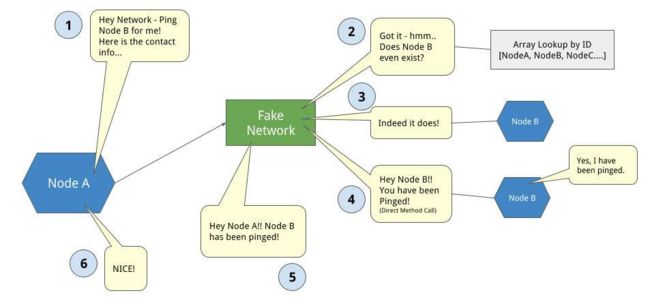
-
Fake Network Adapter(伪网卡):本质上是一个由其他节点组成的数组,带有一些用于查找和远程过程调用代理的方法。
2)HTTP远程调用
-
Real Network Adapter (真网卡):从所提供的联系节点信息和对应于远程过程调用的路由中列出的 IP / 端口处理一个 HTTP Post 请求,可能包括请求主体中的相关数据——请求节点的联系信息、查询信息等。
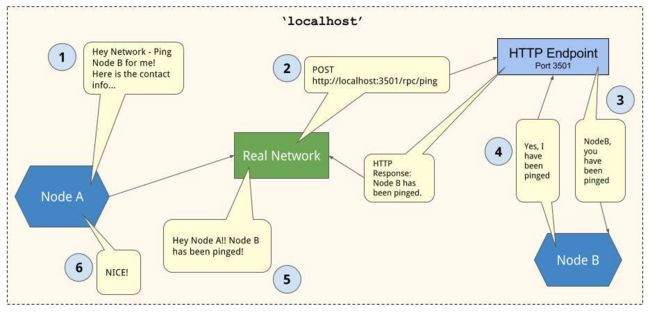
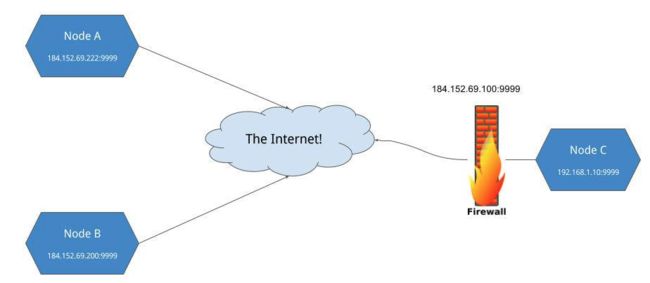
3)RPC/HTTP在互联网环境下传递
-
Ngrok:第三方隧道服务
4)灵活的节点实例化和启动脚本
- 节点广播机制
系统架构

顶级对象是 XorroNode,它是一个模块化的 Sinatra 应用程序。
每个 XorroNode 包含:
- 一个单独的 Kademlia 节点,负责维护自己的路由表和分布式哈希表。
- 用于向其他节点发起远程过程调用的网卡。
- 用于从其他节点、Web UI 和文件传输接收远程过程调用的 Sinatra 端点。
- 用于文件接收、切分和清单文件的创建。