姓名:吴兆阳 学号:14020199009
转自雷克世界
嵌牛导读:我们一直在研究用于机器人控制的神经网络的基于学习的样本高效方法。对于复杂的、接触点丰富的模拟机器人以及实际应用中的机器人(图1),我们的方法能够学习轨迹跟踪的运动技能,而这一过程仅使用收集自机器人在环境中的随机行为的数分钟数据。在本文中,我们将对该方法和结果进行简要概述。
嵌牛鼻子:机器人运动
嵌牛提问:机器人如何实现自主运动?
嵌牛正文:
样本效率:无模型的VS基于模型的
从经验中学习机器人技能通常属于强化学习的范畴。强化学习算法一般可以分为两类:无模型,即学习策略或值函数;以及基于模型的,即学习动力学模型。虽然无模型深度强化学习算法能够学习广泛的机器人技能,但它们往往会受到高昂的样本复杂性的限制,通常需要数百万个样本才能获得良好的性能表现,而且一次只能学习一项任务。尽管之前的一些研究已经将这些无模型算法应用于现实世界的操作任务中,但这些算法的高度复杂性和不灵活性已经阻碍了它们在现实世界中用于学习运动技能的应用。
基于模型的强化学习算法通常被认为是更有效的样本。然而,为了获得良好的采样效率,这些基于模型的算法通常使用相对简单的函数逼近器,其不能很好地推广到复杂的任务,或者使用高斯过程这样的概率动力学模型,其概括性好,但复杂和高三维的领域,如摩擦接触,会导致不连续的动力学系统。相反,我们使用中等大小的神经网络作为函数逼近器,可以实现出色的样本效率,同时仍然具有足够的表现力,可以用于各种复杂和高维运动任务的推广和应用。
基于模型深度强化学习的神经网络动力学
在我们的研究中,我们的目标是将深度神经网络模型在其他领域中的成功扩展到基于模型的强化学习中。近年来,先前那些将神经网络与基于模型的强化学习相结合的努力还没有实现能够与较简单的模型(例如高斯过程)相媲美的结果。例如,Gu等人观察到,即使是线性模型在合成经验生成方面也能够获得较好的性能表现,而Heess等人则在将涵盖神经网络在内的模型纳入到无模型学习系统中看到了相对适度的益处。我们的方法依赖于一些关键的决策:首先,我们在一个模型预测控制框架内使用已学习的神经网络模型,其中系统可以迭代地重新规划并修正错误;其次,我们使用相对较短的范围预测,以便我们不必依靠这个模型对未来做出非常准确的预测。这两个相对简单的设计决策使得我们的方法能够执行各种各样的运动任务,其中,这些运动任务之前没有使用通用的基于模型的强化学习方法进行演示,即可以直接在原始状态观察中操作。
我们的基于模型的强化学习方法如图2所示。我们保持一个迭代增加的轨迹数据集,并使用该数据集对动态模型进行训练。这个数据集是用随机轨迹进行初始化的。然后,我们通过在使用数据集对神经网络动态模型进行训练、使用模型预测控制器(MPC)和已学习的动态模型收集附加的轨迹以聚合到数据集上之间交替,从而执行强化学习。我们在下面将对这两个组成部分进行讨论。

图2.基于模型的强化学习算法概述
动力学模型
我们将已学习的动力学函数参数化为一个深度神经网络,可以通过一些需要学习的权重进行参数化。我们的动力学函数以当前状态st和动作at作为输入,然后输出预测的状态差st + 1-st。动力学模型本身可以在监督学习环境中进行训练,其中收集的训练数据以成对的输入(st,at)和相应的输出标注(st + 1,st)。
需要注意的是,我们上面所提到的“状态”可以随着智能体的变化而变化,并且可以包括诸如质心位置、质心速度、关节位置以及其他任何我们想选择的可测量数值。
控制器
为了使用一个已学习的动力学模型来完成任务,我们需要定义一个对任务进行编码的奖励函数。例如,标准的“x_vel”奖励可以编码一个前进的任务。对于轨迹追踪的任务,我们制定了一个奖励函数,能够激励靠近轨迹,并沿着轨迹前进。
使用已学习的动力学模型和任务奖励函数,我们建立了一个基于模型的控制器。在每个时间步骤中,智能体通过随机生成K个候选动作序列,使用已学习的动力学模型预测那些动作序列的结果,并选择对应于最高累积奖励的序列(图3),做出到达未来所需H步的规划。然后,我们只执行动作序列中的第一个动作,继而在下一个时间步骤中重复规划过程。这种重新规划使得该方法在学习动力学模型中能够对抗不准确性。

图3.使用已学习动力学模型模拟多个候选动作序列的过程示意图,预测其结果,并根据奖励函数选择最佳动作序列。
结果
我们首先在各种MuJoCo智能体上评估了我们的方法,包括游泳者、half-cheetah和蚂蚁。图4显示,使用我们的已学习动力学模型和MPC控制器,智能体能够遵循一组稀疏的路标所定义的路径。此外,我们的方法只用了几分钟的随机数据对已学习的动力学模型进行训练,显示了它的样本效率。
请注意,使用这种方法的话,我们只需要对模型进行一次训练,且仅需要改变奖励函数,就可以在运行时将模型应用于各种不同的期望轨迹,而不需要单独的特定于任务的训练。
图4:蚂蚁、游泳者和猎豹的移动轨迹结果。每个智能体为了执行这些不同的轨迹而使用的动力学模型仅经过一次训练,且仅使用随机收集的训练数据。
我们方法中的哪些方面对取得良好的性能表现至关重要?我们首先考察了MPC规划范围H的变化。图5表明,如果范围太短的话性能会受到影响,可能是由于不可恢复的贪婪行为。对于half-cheetah而言,如果范围太长的话性能也会受到影响,主要是因为已学习动力学模型中的不准确性。图6显示了一个用于单一100步预测的已学习动力学模型,显示某些状态元素的开环预测最终偏离了基本事实。因此,一个中等的规划范围最好避免贪婪行为,同时最小化不准确模型所带来的不利影响。
我们还改变了用来训练动力学模型的初始随机轨迹的数量。图7显示,虽然较多数量的初始训练数据能够导致较高的初始性能,但是数据聚合能够使得即使是低数据初始化实验也能运行以至达到较高的最终性能水平。这突出显示了强化学习的策略数据是如何提高采样效率的。
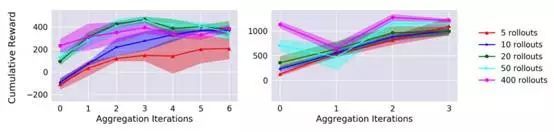
图7:通过使用不同数量的初始随机数据进行训练的动力学模型所获得的任务性能表现曲线图。
值得注意的是,基于模型的控制器的最终性能仍然远低于无模型学习器(当无模型学习器经过数千次的经验训练时)。这种次优的性能表现有时被称为“模型偏差(model bias)”,并且是基于模型的强化学习中的一个已知问题。为了解决这个问题,我们还提出了一种混合的方法,结合了基于模型和无模型的学习,以消除收敛的渐近偏差(asymptotic bias),尽管这是要以附加的经验为代价的。这种混合的方法,以及其他分析,论文中皆有详述。
学习在现实世界中运行

图8:VelociRoACH的长度为10厘米,重量约为30克,每秒可以移动27个身体长度,并使用两个电机来控制所具有的六条腿。
由于我们的基于模型的强化学习算法可以使用比无模型算法更少的经验来学习运动步态,因此可以直接在真实世界中的机器人平台上对其进行评估。在其他研究中,我们研究了这种方法是如何完全从现实世界的经验中进行学习的,从而完全从零开始获取一个millirobots(图8)的运动步态的。
对于许多应用来说,Millirobots由于其体积小和制造成本低而成为十分具有前途的机器人平台。然而,控制这些millirobots是非常困难的,主要是由于它们的动力不足、功率限制和大小等局限性。虽然手动控制器有时可以控制这些millirobots,但是它们往往在动力学机动和复杂的地形上遇到困难。因此,我们利用上面的基于模型的学习技术来使VelociRoach millirobot进行轨迹追踪。图9显示,我们的基于模型的控制器在经过17分钟的随机数据训练后,可以精确地遵循高速轨迹。
图9:使用我们的基于模型的学习方法,VelociRoACH能够遵循各种期望轨迹。
为了分析模型的泛化能力,我们收集了地毯和聚苯乙烯泡沫塑料地形上的数据,继而对该方法进行了评估,如表1所示。正如预期的那样,当基于模型的控制器在与训练期间相同的地形上执行时表现得非常好,表明模型将地形的知识结合在内。然而,当模型在来自两个地形的数据中进行训练时,性能会下降,这可能表明,我们需要进行更多的研究从而开发出能够用于学习适用于多种任务环境的模型的算法。表2显示,随着越来越多的数据被用于训练动力学模型,性能将会不断提高,这是一个令人鼓舞的迹象,表明我们的方法将会随着时间的推移而不断改进(与手动解决方案不同)。

表1:用不同类型的数据进行训练以及在不同表面上执行轨迹追踪的模型的成本
我们希望这些结果展示了基于模型的方法在采样效率机器人学习领域的未来前景,并鼓励在这一方面进行更多的研究。