
最近小乐帝做AI咨询服务,主要帮助互联网和传统行业从业者了解AI,提升AI认知。起初小乐帝的认知目标客户主要是互联网从业者转AI行业,但在实际的咨询工作中,再一次验证了28法则。
真正有AI咨询需求的互联网人只占小部分,更迫切职业转型和认知升级的传统行业从业者占大多数。大部分咨询客户属于完全不懂AI也不懂互联网,属于实际意义上的“小白”。因此像小乐帝这样的AI咨询师有一定的生存空间。
专家规则与机器学习
机器学习属于人工智能的分支之一,在当代可以说是应用落地最广泛的人工智能技术。提到机器学习就免不了谈机器学习和专家规则的差异。拿常见心脏病检测来讲,从业多年的医生可以根据以往经验对诊断单作出判断,有还是没有心脏病;而机器学习则是根据过往的数据训练出判断的模型,再将需要检测的诊断单输入到模型中生成结果。
前者依赖专家多年积累的经验,叫专家规则,常见的专家规则有:老编辑、老司机、老保安、老会计、老律师。后者代表的则是机器学习训练模型做判断,数据量越大越全越准确。
昨天小乐帝的同学了解到小乐帝做AI咨询后,感叹这个时代让人看不懂了,经验在机器面前没有用了。这是小白的洞察,事实也正如此。AI正快速攻城略地,抢占传统行业靠几十年经验吃饭的人的饭碗。
机器学习平台
小乐帝最近读了一本《机器学习实践应用》,本书算小乐帝入门AI行业以来,读过最接底气和小白友好的机器学习书籍。书中提供了在阿里云机器学习平台PAI上各种常见机器学习案例,得以使小乐帝一试身手。
对比使用PAI平台相较于第四范式先知平台,PAI平台对跑机器学习任务抽象程度没有先知高。例如特征工程这块,PAI平台完成特征抽取至少要经历四个算子处理,而先知平台在一个算子和常用方法中实现。机器学习操作成本确实大幅降低。不过先知并没有类似PAI平台的范例。小白上来使用机器学习平台最大的痛点不是不懂机器学习而是没有现成的数据和案例。这是PAI平台做的好的一点。
小乐帝通过PAI平台心脏病检测讲解机器学习原理和过程(心脏病案例:https://help.aliyun.com/document_detail/34929.html?spm=a2c3w.11007039.0.0.2e7deb41eSGTyU)。
机器学习步骤
机器学习步骤基本上可以划分为数据预处理、特征提取、构建模型、模型评估四个步骤。整体实验流程如下:
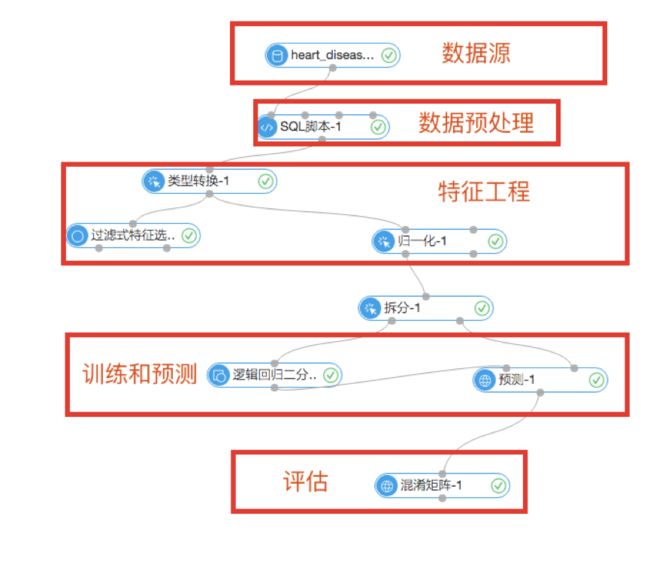
在实际的项目经验中,机器学习开始之前要获取特征列表(如下图)。机器学习本质上是拿过去的数据预测未来的数据。这里有个前提就是机器学习实际上是根据事物过去的特征和结果预测未来的特征对应的结果。因此在拿到原始数据后提取特征就非常重要,数据和特征决定了机器学习的上限。相应地,特征列表起到业务指向的作用,用于从业务理解角度更好提取特征。
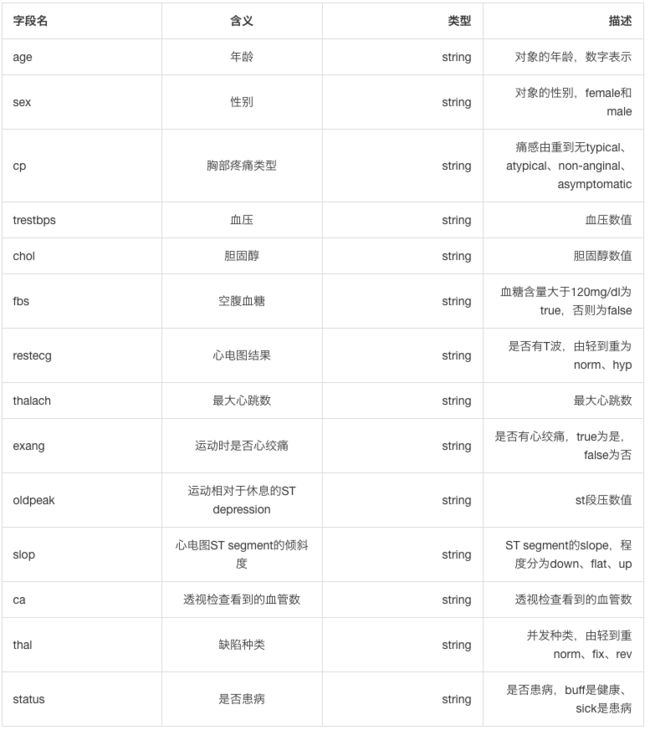
数据预处理
拿到原始数据后,在原始数据算子中查看数据,会发现各个数据项取值情况。计算机在底层采用的0-1二进制运算,字符串信息是无法被计算机很好的解析的,因此数据预处理,可以理解为将数据处理成对计算机更友好的方式,用于后续机器学习步骤。
原始数据如下:
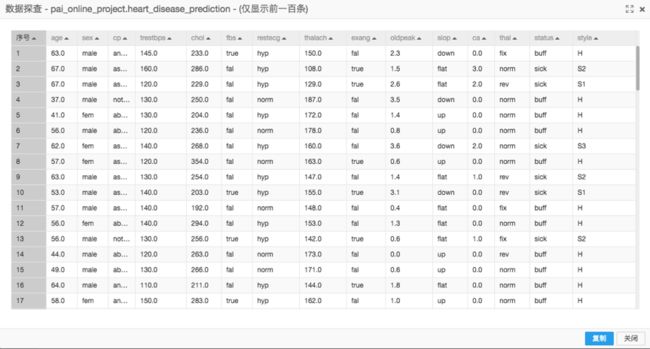
数据预处理更多是将原始字段通过if-else
SQL语句将原始数据处理成计算机可理解的数值数据。
数据预处理SQL语句:
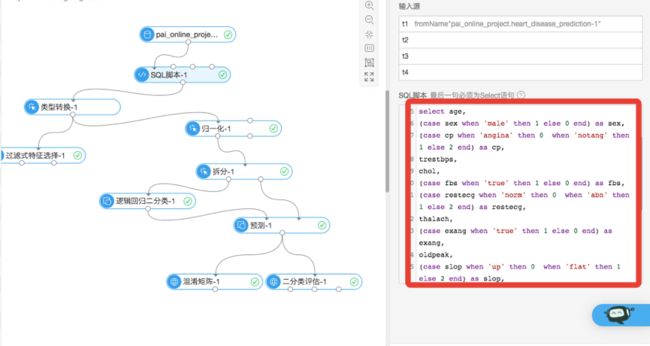
经过数据处理后,原始字符串值变为数值型数值。通常情况下,数据不会太理想,还会存在去噪等问题,但本质上都是将数据处理成对计算机更友好的方式。

特征提取
PAI平台案例中特征提取步骤主要做了确定目标值、确定特征类型和归一化的事情。实际机器学习工作中,特征工程或特征提取这一步骤是最耗人力和起效果的机器学习步骤。
在机器学习中,人工智能中的人工主要体现在特征提取这一步。
机器学习本质上是通过机器来计算一个函数的问题,函数的自变量是输入数据,函数的因变量是输出结果。为了通过机器来训练这个函数,就需要确定因变量即目标值,目标值指定了,自变量也相应地确定了,剩下的就是求解函数的过程。
归一化是在以上的基础上,为了提高计算出函数速度而做的事情,通过更小的时间和算力代价计算出函数(模型)。有兴趣了解更多可参照:https://www.cnblogs.com/LBSer/p/4440590.html
归一化后的数据都在0-1之间:

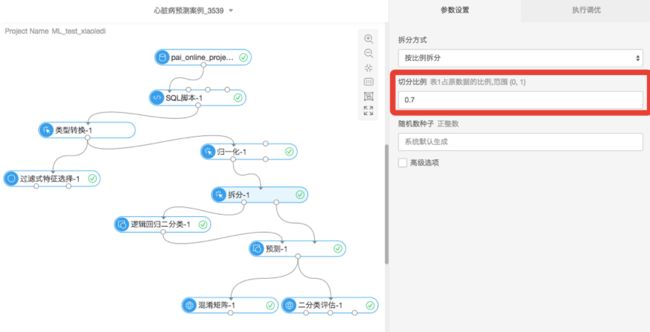
数据拆分
通常来讲,将用于机器学习的数据拆分为两部分:训练集和测试集。训练集数据用于训练模型用,测试集数据则在模型训练完成后,测试模型效果。本案例采用按比例拆分的方式训练集:测试集=7:3。经过拆分算子拆分数据后,70%数据用于训练模型,30%用户测试模型进行模型预测。
小乐帝做的推荐业务采用机器学习排序时,由于训练的数据存在时序关系,因此拆分时需要考虑避免穿越的问题。就好比说拿2018年的数据训练模型来预测抗日战争是否胜利,总能得出正确的结果,但对预测未来并没有什么作用。这就是穿越的问题,不能得到泛化能力足够强预测未来的模型。
构建模型
模型可以理解为F(x,y,…)=z即构建一个函数,通过输入自变量,输出因变量。工业界80%以上模型采用线性模型。采用线性模型的好处在于时间和资源消耗都线性增长,复杂度可控。
本案例中采用的逻辑回归算法生成的模型本质上仍是线性模型类似z=ax+by+…,只是模型输出值控制在[0,1]之间。这样每次输出结果小于0.5归为1即患心脏病,输出结果大于0.5则不患心脏病。实现预测心脏病的功能。
模型评估
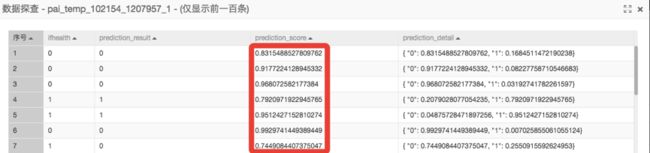
实际模型评估采用AUC作为评估指标,AUC取值[0.5,1]之间。取值0.5代表随机预测,1代表完美预测。AUC越高,模型效果越好,预测越准确。
案例中采用了二分类评估算子从多个维度评估模型效果。实际应用中模型效果上限依赖于原始数据质量和特征工程能力。推荐业务中通常0.7以上即属于比较理想的情况了。

推荐系统与心脏病预测
推荐系统排序环节也是采用机器学习实现,与本文案例中心脏病预测所不同的是,推荐系统排序环节是将进入模型评估的数据进行打分,根据打分由高到低进行排序,生成推荐结果。心脏病预测仅需将打分结果映射为0或1即可。
劲爆消息:
随着移动互联网退潮和经济就业形势日趋严峻,AI如火如荼。很多互联网从业者和非互联网朋友都有转型或了解AI的打算。
但受困于自学或看书蜻蜓点水,不落地,无法建立有效认知,更妄谈入行AI或未来不被机器取代。
中国这两年房地产暴涨,让多少人意识到了认知升级多么重要,现如今就不能错过AI提升认知的机会了。
为此小乐帝作为【一线AI产品经理】和【科技优秀作者】提供AI推荐系统一对一咨询服务,服务内容主要包含:
1.AI推荐系统原理与实践经验
2.机器学习原理与实践经验
3.AI产品经理主要职责
4.当前AI发展行业现状
5.面对AI浪潮你应该做些什么?
一次收费399元(支持线上+线下约见),迅速提升你的AI认知,让你率先看到未来。不再因认知错过潮流,成为时代弄潮儿。
预约咨询请关注微信公众号【产品经理读书会】,并在后台留言预约。
「产品经理读书会」
专注于爱读书爱思考的产品人提供读书推荐、产品思考、以书会友的环境
欢迎爱读书的产品人分享产品道路上的感悟
投稿邮箱:[email protected]
