storm的主要组件
topology是对storm进行程序开发的主要组件,一个topology通常由spout和bolt组成,通过数据流,构成一张有向无环图。
storm在运行过程中,主要实体有三个,分别是:
1.Worker processes
2.Executors (threads)
3.Tasks
Worker process 指supervisor节点中开启的工作进程, Supervisor节点运行过程中,通过supervisor.slots.ports参数配置启动的workers,由于storm集群在运行的过程中采用的是多进程方式,这个进程实际上就是workers的工作进程。可以理解为supervisor是每个服务器的实际管理者,根据slots的配置,启动一定数量的worker来运行topology的spouth或者bolt节点。
Executors (threads) 可以理解为executor就是workers节点中工作的线程,每一个线程都是一个executor.
Tasks 则是运行在线程上的spout或者bolt实例,执行真正的数据处理。
三者的关系可以参见官网的一张图:
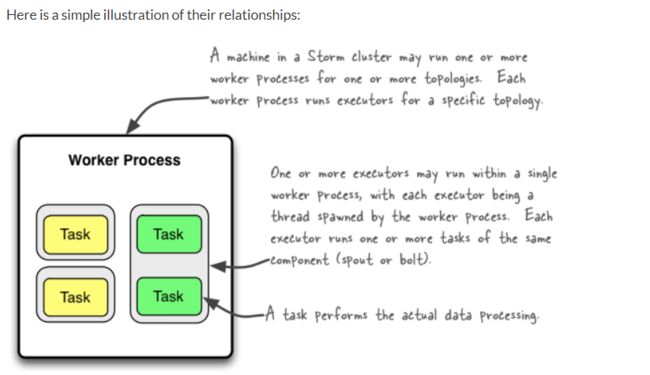
实际上下面这张图更加形象:

一个supervisor中有多个slots,根据slots的配置可以启动多个worker进程,之后通过executor线程运行多个task。task则是spout或者bolt的实例,然后进行数据处理。在0.8以后的版本,executor才被明确的定义为线程。因此在使用storm时要确认每个不通的storm版本文档描述可能不一样。
对于storm上述三个实体,分别可以通过如下参数设置:
Config conf = new Config();
conf.setNumWorkers(2); // 设置worker进程
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // 设置executer线程
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");//通过setNumTasks设置task 的数量。
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
上述代码是官方文档中的一段代码。根据文档描述,上述代码最终的并行度计算为5

可以推导出如下公式:
并行度 = sum(实际的executers总数)/workers总数
为什么要用实际的executers总数 而不是 parallelism 之和呢?实际上上述代码过于简单,掩盖了不少问题。下面通过一段代码,进行实验验证。
代码
SimpleSpout
package com.dhb.storm.example.parallel;
import lombok.extern.slf4j.Slf4j;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import static java.lang.Thread.currentThread;
@Slf4j
public class SimpleSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private TopologyContext context;
private AtomicInteger atomicInteger;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
this.context = context;
this.atomicInteger = new AtomicInteger(0);
log.warn("SimpleSpout->open:hashcode:{}->thread:{},taskID->{}",
this.hashCode(),currentThread(),context.getThisTaskId());
}
@Override
public void nextTuple() {
int i = this.atomicInteger.incrementAndGet();
if(i <= 10) {
log.warn("SimpleSpout->nextTuple:hashcode:{}->thread:{},taskID:{},Value:{}",
this.hashCode(),currentThread(),context.getThisTaskId(),i);
this.collector.emit(new Values(i));
}
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("i"));
}
@Override
public void close() {
log.warn("SimpleSpout->close:hashcode:{}->thread:{},taskID->{}",
this.hashCode(),currentThread(),context.getThisTaskId());
}
}
SimpleBolt
package com.dhb.storm.example.parallel;
import lombok.extern.slf4j.Slf4j;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import java.util.Map;
import static java.lang.Thread.currentThread;
@Slf4j
public class SimpleBolt extends BaseBasicBolt {
private TopologyContext context;
@Override
public void prepare(Map stormConf, TopologyContext context) {
this.context = context;
log.warn("SimpleBolt->prepare:hashcode:{},thread:{},taskID:{}",
this.hashCode(),currentThread(),context.getThisTaskId());
}
@Override
public void cleanup() {
log.warn("SimpleBolt->cleanup:hashcode:{},thread:{},taskID:{}",
this.hashCode(),currentThread(),context.getThisTaskId());
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
Integer i = input.getIntegerByField("i");
log.warn("SimpleBolt->execute:hashcode:{},thread:{},taskID:{},value:{}",
this.hashCode(),currentThread(),context.getThisTaskId(),i);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
SimpleToplogy
package com.dhb.storm.example.parallel;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
@Slf4j
public class SimpleToplogy {
/**
* @param args
* toplogly name
* component prefix
* workers
* spout executor size (parallel hint)
* spout task size
* bolt executor size (parallel hint)
* bplt task size
*/
public static void main(String[] args) {
if (7 > args.length) {
throw new IllegalArgumentException("The arguement is Illegal.");
}
final Options options = Options.build(args);
log.warn("Toplogly-Options",options);
final TopologyBuilder builder = new TopologyBuilder();
String spoutName = options.getPrefex()+"SimpleSpout";
builder.setSpout(spoutName, new SimpleSpout(), options.getSpoutPallelHint())
.setNumTasks(options.getSpoutTasks());
builder.setBolt(options.getPrefex() + "-SimpleBolt", new SimpleBolt(), options.getBoltPallelHint())
.setNumTasks(options.getBoltTasls()).shuffleGrouping(spoutName);
final Config config = new Config();
config.setNumWorkers(options.getWorkers());
try {
log.warn("==================================================");
log.warn("******** The toplogly {} is submitted.**********",options.getTopploglyName());
log.warn("==================================================");
StormSubmitter.submitTopology(options.getTopploglyName(),config,builder.createTopology());
} catch (AlreadyAliveException |InvalidTopologyException |AuthorizationException e) {
e.printStackTrace();
}
}
@Data
private static class Options {
private final String topploglyName;
private final String prefex;
private final int workers;
private final int spoutPallelHint;
private final int spoutTasks;
private final int boltPallelHint;
private final int boltTasls;
static Options build(String[] args) {
return new Options(args[0],args[1],Integer.parseInt(args[2]),
Integer.parseInt(args[3]),Integer.parseInt(args[4]),
Integer.parseInt(args[5]),Integer.parseInt(args[6]));
}
}
}
注:上述代码需要依赖lombok
现在对上述代码,打包之后,部署到storm集群上进行测试。
用例1
storm jar storm-in-action-trunk-jar-with-dependencies.jar com.dhb.storm.example.parallel.SimpleToplogy tp1 tp1 1 2 1 2 1
1个worker,对于spout和bolt,分别启动2个executor和1个task,此时的执行结果见下图:

可以发现,虽然指定了2个executer线程,但是spout和bolt都只启动了一个executer。难道是因为worker只有1个的缘故吗,因此改变worker的数量,进行第二组测试。
用例2
storm jar storm-in-action-trunk-jar-with-dependencies.jar com.dhb.storm.example.parallel.SimpleToplogy tp2 tp2 2 2 1 2 1
2个worker,对于spout和bolt,分别启动2个executor和1个task,此时的执行结果见下图:

此时,由于增加了2个worker,storm只是分别在不同的wokrer上启动了spout和bolt,而spout和bolt的executer还是1。由此可以发现,executer的数量与task的数量有关系,与worker没有关系。当executer的数量大于worker的数量时,系统对于空闲的executer不会启动,只会根据task的数量,启动有用的executer。实际上这也能理解,就是storm集群在启动topology时做了优化,一部分无用的线程就不会被启动,以节约系统开销。
用例3
storm jar storm-in-action-trunk-jar-with-dependencies.jar com.dhb.storm.example.parallel.SimpleToplogy tp3 tp3 2 2 2 2 2
2个worker,对于spout和bolt,分别启动2个executor和2个task,此时的执行结果见下图:

根据结果可以发现,此时对于spout和bolt的executer均是2,也进一步说明,只有当executer的数量小于等于task时才有意义。
另外,如果不对task进行设置,系统将默认按1个executer分配1个task来启动。
对于storm并行度及配置参数的影响,可以参考这篇文章:
https://www.cnblogs.com/quchunhui/p/8271349.html

上图中很好的说明了storm各参数设置的结果。
结论
我们可以得到如下结论:
1.有3个参数可以对storm对topology的task数量产生影响。
2.当executer的数量大于task的数量时,没有意义,系统会优化掉(不启动)分不到task的executer。
3.task数量一经设置不可改变,executer的数量则可以通过rebalance来改变。
4.如果不设置executer的数量,只通过设置task的数量,并不能提高并发度,反而会造成大量的任务串行,降低效率。