- 两年前用过solr5.1版本的,当时只是简单入个门,拿来在项目里建个全文索引,然后再query,其他什么也没做,还是傻傻地自己去配Tomcat,这次做毕设因为需求而重拾solr,基于作死折腾的原则,肯定要用最新版的啦~,然后。。。还是很顺利踩到坑了,schema相关配置变了。。。配置变了。。。置变了。。。变了。。。了。。。不过还是很快解决了,当然这次打算把集群高可用相关也折腾折腾、还有和mysql之间的配合和索引同步,所以新写一篇看起来不那么low的博客出来(之前写过一篇弱文。。。)
下载和初始化启动
官网下载6.5.1版本的solr,解压
目录说明:
- bin:启动脚本
- contrib:第三方贡献拓展jar包,包括一些第三方分词器
- dist:一些最终生成的jar包,主要是solrj客户端jar包
- docs:文档
- example:一些样例,example-DIH目录下的是一些solr索引core样例
- server:solr服务端工作目录,自带集成jetty插件方式启动solr服务器
-
- solr:solr搜索引擎工作目录,即solr/home
-
- solr-webapp:solr后台管理页面webapp
-
- start.jar:服务端启动jar包
准备工作
- contrib/analysis-extras/lucene-libs:这个目录下是第三方分词器jar,将其拷贝到server/solr-webapp/webapp/WEB-INF/lib下供webapp使用
- dist/solrj-lib:这里是solrj客户端的依赖jar包,使用maven的话用如下坐标即可
org.apache.solr
solr-solrj
6.5.1
- example/example-DIH/solr:该目录下自带了初始的五个索引库core,将其拷贝到server/solr目录下,solr服务端启动才会自动引入core到系统中(solr.xml不要复制)
- server/solr:步骤3拷贝过来的五个core中有conf一系列配置文件可以配置这个core相关参数,后面专门细讲
索引库core配置
到配置好的server/solr目录下,找到db目录为例,db/conf目录下一堆的配置文件,主要配置的为如下:
- db/lib:存放该core需要的额外jar,比如第三方分词器,在该目录下的分词器中的类可以在schema配置时直接全限定类名引入
- db/conf/managed-schema:schema配置文件,该文件为系统REST API配置时系统的合成文件,不建议手动修改
- db/conf/schema.xml:我自己把managed-schema复制一份重命名的,用于手动配置schema
- db/conf/solrconfig.xml:该core的总配置文件
说明
- 系统生成和手动编辑可能产生重叠,系统生成的编辑可能会删除注释或者其他帮助理解域、域类型的关键性的自定义内容。你可能希望通过源码控制标记(配置)文件的版本,或者同时限制手动编辑。
Solrconfig.xml允许Solr schema被定义为“被管理的索引模式”:只能通过Schema API修改schema。- managed-schema是solr开始才有的schema配置文件,它是用来避免API方式配置schema和手动修改schema配置文件之间的冲突(比如说重复字段名),因此这个文件不建议手动修改
- 可以把managed-schema复制一份schema.xml,然后在这个文件手动配置schema
- 这两个schema配置文件solr系统如何识别呢?答案是两个配置是不能同时生效的,系统默认使用managed-schema,支持REST API方式动态配置schema,适合有动态配置schema、field、fieldType之类需求的就使用这个配置,什么都不改即可。
- 若项目没有动态修改schema的需求,那可以使用schema.xml进行配置,在其中可以很方便根据schema配置语法进行个性化自定义,方便编码,若要schema.xml生效,需要按照如下步骤修改db/conf/solrconfig.xml的配置:
- 找到如下配置(6.5.1其实默认没有这个配置,自己直接添加就行):
true
managed-schema
- 替换成:
Schema手动配置Field和FieldType
启动solr
bin/solr start
启动如下:
solr-start.png
浏览器访问 http://localhost:8983/,如下:
solr-admin.png
关闭solr
bin/solr stop
关闭如下:
solr-stop.png
集群部署
Solr集群架构图
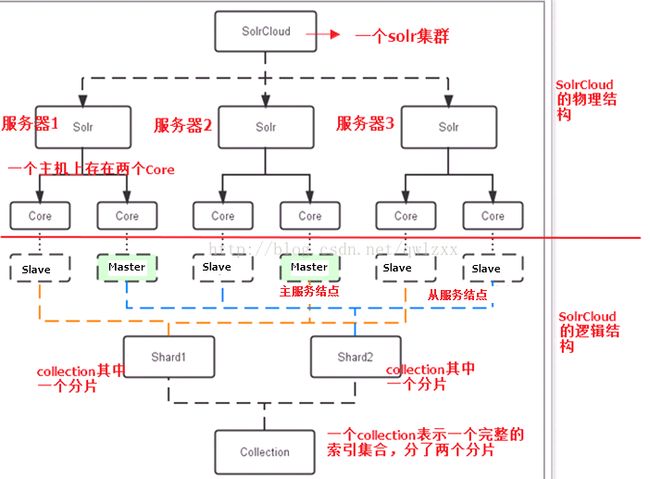
solr-cloud-struct.png
- 图的上半部分是物理结构,一看就清楚,需要关注的是每个机器节点都可以有多个core,这个和下面的逻辑结构有比较大的联系。
- 下半部分逻辑结构:一个Collection就是一个完整的索引集,可以理解为一个索引文件,Shard1和Shard2就是该索引集的多个分片,就是说把完整的一个索引文件分成了多个,类似数据库分库分表,不过你在访问的时候只需要访问Collection即可,内部分片和索引所在的分片位置不需要关心,这样对不同个分片的访问就可以分流到不同机器上就行处理,也避免了单个索引文件无限膨胀的可能。
- 再往上就是副本,每个Shard都可以有多个副本,类比数据库读写分离,写操作由Master节点接收,并自动同步到Slave节点,当一个Master节点宕机,就会自动选举一个Slave节点重新承担Master的功能,这里的每个副本就如图所示,对应每个Solr节点的一个Core,这样逻辑和物理之间的联系就建立起来了。
高可用
- SolrCloud集群由ZooKeeper进行协调,集群中所有节点使用ZooKeeper中共有的配置文件,这样就能保证各个节点之间的配置统一。
- SolrCloud节点宕机、Master选举等都通过ZooKeeper的分布式协调实现,所以说SolrJ的访问地址也是ZooKeeper的地址。
SolrCloud集群部署
- 这里比较重要了,由于Solr的版本间兼容性较差,又因为我这是当前最新版,因此在集群部署过程中遇到很多坑,主要是查的资料各种版本都有,还分成tomcat和jetty两种部署方式,搞得我在试验各种方案的过程中浪费了很多时间,好在最后让我找到了一个比较可靠的博客,很详细地用最简单的jetty方式部署,其实从各方面性能看,jetty不比tomcat差,而且现在都流行直接nginx反向代理和负载均衡以及微服务,我反而更喜欢jetty了。。。
- 先贴教程:Solr6.0.1概念和集群部署
- ZooKeeper集群部署,这在我之前的博客有,需要的自行查看,我就直接那部署好的ZooKeeper来用而已:ZooKeeper配置和学习笔记
- 官网下载solr-6.5.1.tgz,解压并到该目录下
- 上传配置文件到ZooKeeper(之后整个集群所有机器就是共用这套配置文件了):
./bin/solr zk -z localhost:2181/solr -upconfig -n solr -d example/example-DIH/solr/solr
参数说明:
-upconfig 表示把你的配置文件上传到ZooKeeper集群
-n configName 指定这个配置的名称,solr管理页面会用到
-d confdir 要上传的配置文件在本地的地址,默认使用解压的example/example-DIH/solr/solr即可,若有配置需求的,可实现修改相应的配置,再上传到ZooKeeper(配置方法同上面的单节点模式)
-z zkHost Zookeeper集群地址
- 把刚才解压的整个solr-6.5.1目录额外复制两份(伪分布式,你若有多台机器可考虑真实分布式部署)
- 启动solr节点服务:
./bin/solr start -c -m 1g -z localhost:2181/solr -p 8983
参数说明:
-c:cloud模式启动
-m:最大内存使用
-z:zookeeper集群地址
-p:启动服务端口
- 相同方式启动另外两个节点:(端口号错开)
solr-2/bin/solr start -c -m 1g -z localhost:2181/solr -p 8984
solr-2/bin/solr start -c -m 1g -z localhost:2181/solr -p 8985
- 浏览器访问:http://localhost:8983/solr/#/
-
如图创建Collection:
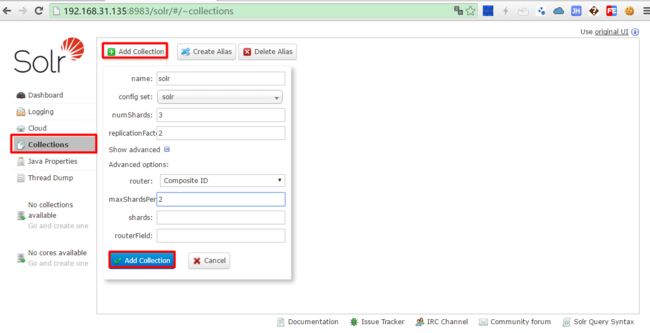 solr6.0.1-collections-addCollection.png
solr6.0.1-collections-addCollection.png
- 配置参数说明:
name: 待创建Collection的名称
config set: collection在zookeeper中的配置目录
numShards: 分片的数量
replicationFactor: 复制副本的数量
maxShardsPerNode:默认值为1,注意三个数值:numShards、replicationFactor、liveSolrNode,一个正常的solrCloud集群不容许同一个liveSolrNode上部署同一个shard的多个replic,因此当maxShardsPerNode=1时,numShards*replicationFactor>liveSolrNode时,报错。因此正确时因满足以下条件:
numShards*replicationFactor-
查看各个节点和分片的关系图:
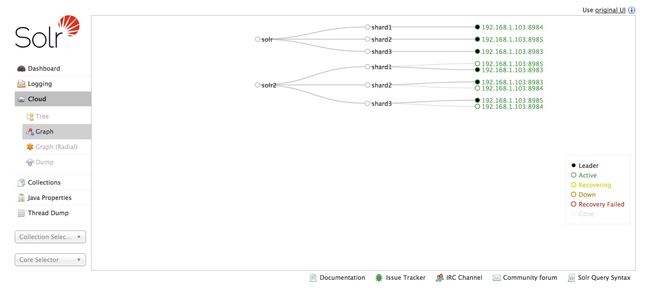 solr-6.5.1-collection-graph.png
solr-6.5.1-collection-graph.png
- 至此,SolrCloud集群部署完成。
- 可以看到solr2这个Collection有shard1、shard2、shard3三个分片,每个分片有两个副本,一个Master、一个Slave,黑点为当前处于Master的副本节点。
这时候我们随便打开一个solr节点的目录server/solr,如下:
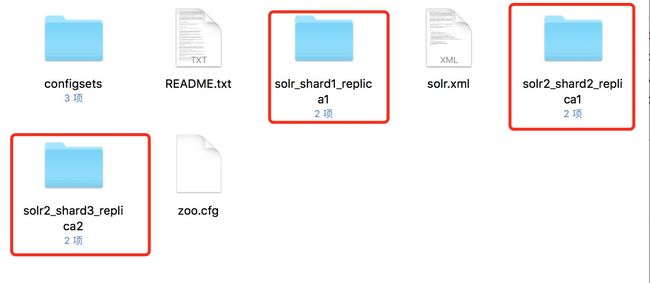 solr-6.5.1-node-date.png
solr-6.5.1-node-date.png可知,刚才管理界面创建的Collection节点的分片以core的形式存在于每个节点的core列表目录下,进入其中一个文件夹查看:
 solr-6.5.1-node-date-dir.png
solr-6.5.1-node-date-dir.png只有core.properties和data,上面的单节点模式每个core目录下还有lib和conf的,但是这里没有,下面图示说明:
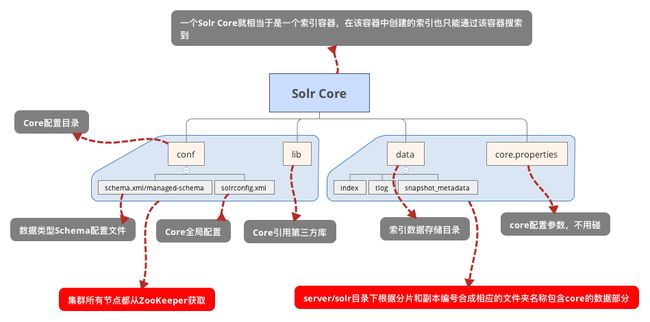 Solr-Cloud-Core.png
Solr-Cloud-Core.png
客户端访问操作
单节点访问
/**
* Solrj客户端工具类,实现对Solr服务的创建索引和查找操作
*
* @author linyuqiang 2017/05/10
*/
public class SolrClient {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* Solr本地地址
*/
private String url = "http://localhost:8983/solr/db";
//查询字符串key
private String searchKey = "text_all";
private boolean highlighting = true;
private String highlightingPre = "";
private String highlightingPost = "";
private String highlightingField = "content";
// Solr客户端对象
private HttpSolrClient client;
public SolrClient open() {
// 1.创建SolrServer对象,以下这两个是线程安全的SolrServer实现类
// CommonsHttpSolrServer 基于Http协议进行C/S数据交互
// EmbeddedSolrServer
// 内嵌式,只要设定好solr的home目录即可实现和solr的交互,不需要开启solr的服务器,本地交互
client = new HttpSolrClient(url);
client.setSoTimeout(10000); // socket read timeout
client.setConnectionTimeout(1000);
client.setDefaultMaxConnectionsPerHost(100);
client.setMaxTotalConnections(100);
client.setFollowRedirects(false); // defaults to false
// allowCompression defaults to false.
// Server side must support gzip or deflate for this to have any effect.
client.setAllowCompression(true);
return this;
}
/**
* 查找,分页查询
*
* @param qString 查找字符串
* @return 返回查询结果列表
*/
public List search(String qString, Integer pageNum, Integer pageSiez) {
try {
SolrQuery query = new SolrQuery(searchKey + ":" + qString);// 查询字符串
query.setStart((pageNum - 1) * pageSiez);// 设置查询开始下标
query.setRows(pageSiez);// 查询行数
//高亮配置
query.setHighlight(highlighting);
query.setHighlightSimplePre(highlightingPre);
query.setHighlightSimplePost(highlightingPost);
query.addHighlightField(highlightingField);
QueryResponse response = client.query(query);// 获取查询返回对象
SolrDocumentList docs = response.getResults();// 获取查询得到的所有Document
//查询高亮信息
Map>> highlightings = response.getHighlighting();
List list = new ArrayList();
for (SolrDocument doc : docs) {
// 获取每个Document的详细信息
SolrjMessage message = new SolrjMessage();
message.setId((String) doc.getFieldValue("id"));
message.setUrl((String) doc.getFieldValue("url"));
//高亮信息
List hights = highlightings.get(message.getId() + "").get(highlightingField);
StringBuilder highlighting = new StringBuilder();
for (int i = 0; i < hights.size(); i++) {
highlighting.append(hights.get(i)).append(" ");
}
message.setHighlighting(highlighting.toString());
list.add(message);
}
//其他查询信息
NamedList responseHeader = response.getResponseHeader();
SimpleOrderedMap params = (SimpleOrderedMap) responseHeader.get("params");
NamedList 集群访问
- client对象的初始化方式改变,其他创建索引、删除索引、搜索的代码都和单节点一样。
/**
* ZooKeeper地址
*/
private String zookeeperUrl = "{zookeeperHost}:2181/solr";
//查询字符串key
private String searchKey = "name";
private boolean highlighting = true;
private String highlightingPre = "";
private String highlightingPost = "";
private String highlightingField = "content";
// Solr客户端对象
private CloudSolrClient client;
public CloudSolrClient1 open() {
// 1.创建SolrServer对象,以下这两个是线程安全的SolrServer实现类
// CommonsHttpSolrServer 基于Http协议进行C/S数据交互
// EmbeddedSolrServer
// 内嵌式,只要设定好solr的home目录即可实现和solr的交互,不需要开启solr的服务器,本地交互
client = new CloudSolrClient(zookeeperUrl);
client.setSoTimeout(10000); // socket read timeout
//指定Collection名称
client.setDefaultCollection("solr");
client.setZkClientTimeout(30000);
client.setZkConnectTimeout(30000);
client.setSoTimeout(30000);
return this;
}
管理界面使用说明
-
Collection管理界面,可以添加、删除、查看、别名Collection
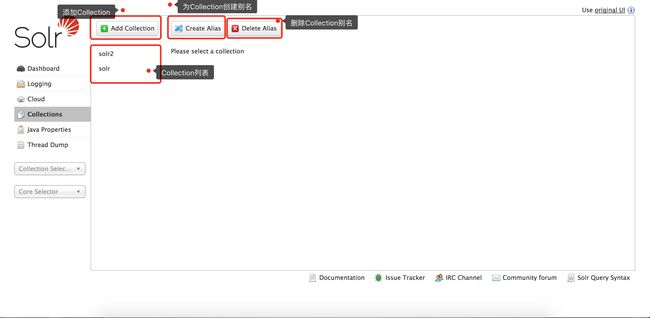 Collection-manager.png
Collection-manager.png -
选中其中一个Collection可以进行操作的菜单栏
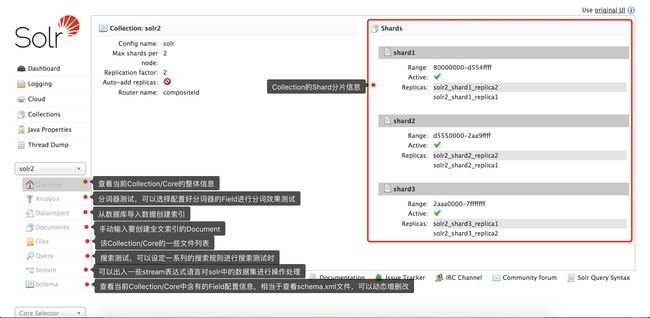 solr-6.5.1-overview.png
solr-6.5.1-overview.png -
分词器测试页面,可以对自己配置的分词器手动输入字符串进行分词结果测试
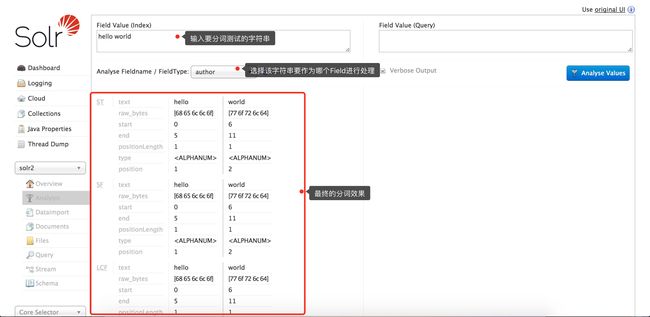 solr-6.5.1-analysis.png
solr-6.5.1-analysis.png -
手动输入document的测试页面,使用不多
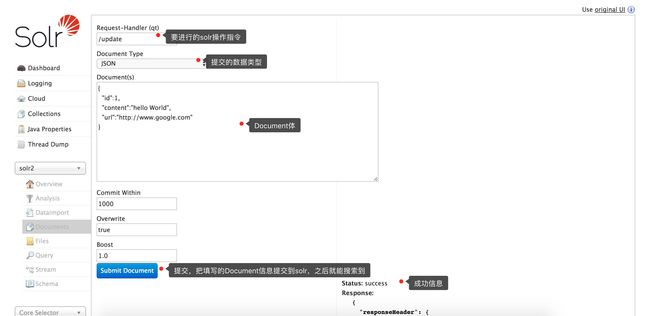 solr-6.5.1-document.png
solr-6.5.1-document.png -
查看当前Collection的配置文件列表,使用不多
 solr-6.5.1-files.png
solr-6.5.1-files.png -
搜索查询测试页面,支持分页、排序、高亮、过滤等查询参数的配置,执行按钮点击之后可以在右边页面查看查询的结果信息
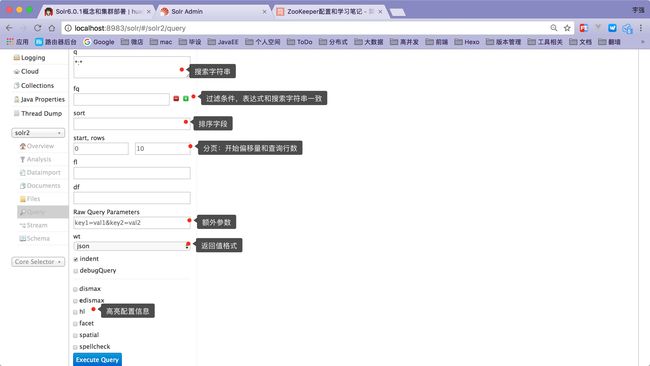 solr-6.5.1-query.png
solr-6.5.1-query.png -
Schema管理页面,可以增加、删除、查看三种类型的Field
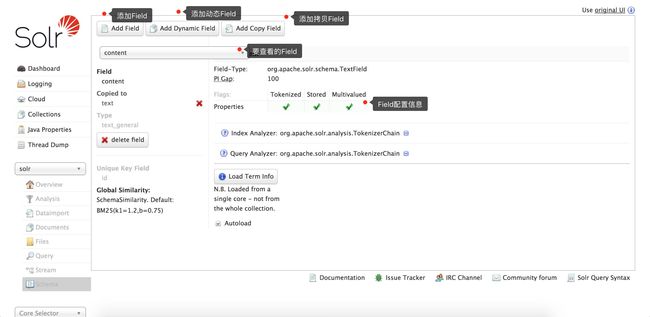 solr-6.5.1-schema.png
solr-6.5.1-schema.png -
选中其中一个Core可以进行操作的菜单栏
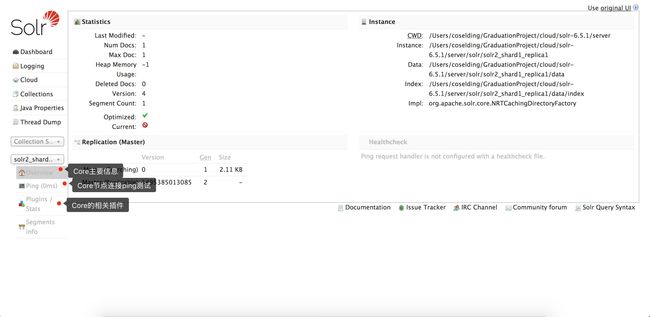 solr-6.5.1-core.png
solr-6.5.1-core.png
数据库索引同步
- solrconfig.xml配置数据导入加载类:
solr-data-config.xml
- 要放在
之前
- 相同目录下创建solr-data-config.xml配置数据库连接信息:
- 很简单,照抄小改就行,用jdbc四要素进行连接,delta相关参数是增量导入用的,solr内部维护好上次导入的id和时间戳,这次增量导入就根据内部维护的时间戳进行对比,把变化的部分重新导入到solr。
- 需要注意的是
标签的name属性要在solr的该core的schema进行相应的配置,保证这些field是存在的才能正常运行。
-
server/solr-webapp/webapp/WEB-INF/lib放入mysql的jdbc驱动包 - 清空该Core中的所有数据,或者新建一个全新的Core
-
到solr管理页面导入数据即可:
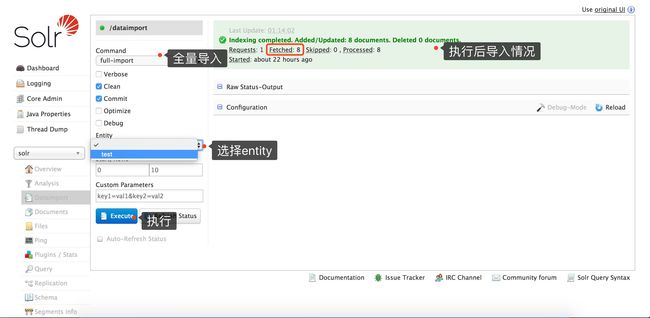 solr-6.5.1-dataimport.png
solr-6.5.1-dataimport.png
其他用到的命令
- 本地配置同步到ZooKeeper:(一个个文件同步)
./server/scripts/cloud-scripts/zkcli.sh -zkhost localhost:2181 -cmd putfile /solr/configs/solr/solrconfig.xml example/example-DIH/solr/solr/conf/solrconfig.xml
- 重新加载solr集群的节点配置:(同步ZooKeeper之后免重启集群,重新加载配置信息)
http://localhost:8983/solr/admin/collections?action=RELOAD&name=solr
- 从数据源导入数据到Solr
http://localhost:8983/solr/solr2/dataimport?command=full-import&commit=ture
感谢
- Solr6 Schema.xml配置
- Solr6.5 集群搭建、数据库数据导入solr、分词器配置
- Solr6.0.1概念和集群部署
- Solr6 as JDBC Data Source
- 一些Solr的RESTful API