语言的正则化LSTM用于情感分类
Linguistically Regularized LSTM for Sentiment Classification
摘要
这篇paper解决句子级别的情感分类。尽管各种各样的神经网络模型已经提出,然而,之前的模型要么十分依赖短语级别的注释,大多数有显著地退化表现当训练时只有句子级别的注释;要么不能充分的使用语言的资源(也就是,情感词典,否定词,强度词)。在这篇paper,我们提出简单模型由句子级别注释训练,但也尝试对语言的情感词,否定词,强度词建模。结果显示我们的模型可以在情感表达中捕获情感词,否定词和强度词的语言角色。
1 介绍
情感分类致力于分类文本到情感类别例如正向或负向,或者更细粒的类别例如十分正向,正向,中性等等。已经有各种各样的方法用于这个目的例如基于词典的分类,基于早期机器学习的方法,和最近的神经网络模型例如卷积神经网络CNN,循环神经网络RNN,LSTM以及更多。
尽管这些神经模型有很大的成功,还是有一些瑕疵在之前的研究中。首先树结构的模型例如递归自编码和Tree-LSTM,依赖语法分析树结构和昂贵的短语级别的注释,当仅仅训练句子级别的注释它的表现有大体上的降低。其次,语言知识例如情感词典,否定词或叫negator(如not,never),和强度词或叫intensifier(如very,absolutely),还没有充分的应用到神经模型。
这个研究的目的是发展简单序列模型但是依然尝试充分利用语言资源有利于情感分类。首先,我们试图发展不依赖语法分析树和不需要在现实使用中十分昂股的短语级别注释的简单模型。其次,为了获得有竞争力的表现,简单模型可以受益于语言资源。三个类别的资源将会在这篇paper中被处理:情感词典,否定词,强度词。情感词典提供一个词的预先的极性,可以用来决定例如短语和句子的长文本情感极性。否定词是特别的句子转换者,可以不断地改变情感表达的极性。强度词对于细粒化情感分类十分重要。
为了为情感,否定和强度词等语言角色建模,我们主要的想法是正则化预测当前位置的情感分布和之前或下一个位置之间的不同,在一个序列模型中。例如,如果当前位置是一个否定词not,这个否定词应该对应的改变下一个位置的情感分布。总结下,我们贡献于两个方面:
• 我们发现建模语言情感,否定和强度词的角色可以增强句子级别的情感分类。我们解决这个问题通过在序列LSTM模型上增强激发语言的正则化矩阵。
• 不像之前的模型依赖语法分析结构和昂贵的短语级别的注释,我们的模型是简单和有效率的,但是表现上和现有水平是一样的。
余下paper的组织如下:在接下来的section,我们调查相关工作。在section3,我们简短的介绍LSTM的背景和bi-LSTM的背景,接着仔细的描述语言正则化矩阵用于情感/否定/强度词在section4。实验呈现在section5,结论在section6。
2 相关工作
2.1 神经网络用于情感分析
有许多神经网络被提出用于情感分类。最值得注意的模型可能是迭代自编码神经网络,通过分句迭代建造一个句子的表示。这样的迭代模型经常依赖一个输入文本的树结构,为了获得有竞争力的结果,经常需要所有分句的注释。序列模型,例如,CNN,不需要树结构数据,从而被广泛的采用到情感分类。LSTM模型同样常见于学习句子级别的表示由于它建立前缀和后缀内容模型的能力。LSTM可以一般的应用于序列数据但是还是树结构数据。
2.2 应用语言知识到情感分类
语言知识和情感资源,例如情感词典,否定词,和强度词一般对情感分析是有用的。
情感词典一般定义词典入口的先验极性,对基于词典的模型和机器学习方法是有价值的。最近有许多从社会数据和各种语言的情感词典的自动构建的工作。一个值得注意的工作它使用情感词典取句子的情感分数为否定词和情感词的先验情感分数的权重加总,权重由神经网络学习。
否定词对文本表达的情感改进扮演很重要的角色。一些早期否定模型采用反转假设也就是一个否定词反转改良文本的情感值的符号。这个转换假设假设否定词改变情感值通过恒定的数量。由于每个否定词可以影响改良的文本用不同的方式,恒定的数量可以被扩展到否定特别的,更多的,否定词的影响还可以依赖改良的文本的语法和语义。其他方法去否定建模可在【】查看。
一个短语的情感强度表明相关的情感强度,对于细粒化情感分类或排序十分重要。强度词可以改变改进的文本的valence程度(也就是情感强度)。在【】中作者提出一个线性回归模型预测内容词的valence值。在【】中一个基于核的模型提出结合语义信息用于预测情感分数。在SemEval-2016任务7子任务A中,一个学习排序的模型伴随着一个组合策略被提出去预测情感强度分数。语言去昂度不限制于情感或者强度词,而且有许多工作赋予低中高强度规模到形容词例如okay,good,great或者可分级的术语。
在【】中,一个情感解析器被提出,并且作者研究了当一个短语被否定词或强度词改进后情感如何变化。
应用语言正则化到文本分类可在【】看到,其中介绍了三个语言动机的结构正则化基于语法分析数,主题和等级词簇用于文本分类。我们的工作不同于【】应用组lasso正则化到逻辑回归的模型参数,我们的正则化应用在中间输出伴随KL分散。
3 LSTM网络
3.1 LSTM
长短词组记忆被广泛的应用到文本处理。简单地说,在LSTM中,隐藏层h_t和记忆cellc_t是之前c_{t-1}和h_{t-1}和输入向量x_t的一个函数,或者公式化如下:
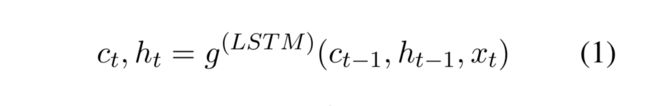
在隐藏层状态h_t \in R^d表示位置t同时还编码之前位置的内容。我们推荐【】阅读更多的细节关于LSTM。
3.2 双向LSTM
在LSTM,每个位置h_t的隐藏层仅仅编码前缀文本在一个向前的方向然而反向的文本没有被考虑。双向LSTM利用两个平行的通道(前向和后向)和拼接两个LSTM的隐藏状态为每个位置的表示。前向和后向LSTM分别公式如下:
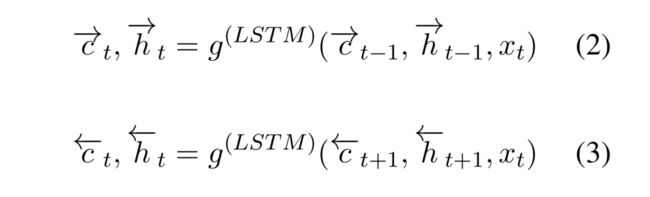
其中g^(LSTM)和公式1一样。特别的,两个LSTM的参数是共享的。整个句子的表示是[\bar → h_n,\bar ← h_1],其中n是句子的长度。在每个位置t,新的表示是h_t = [\bar → h_t,\bar ← h_t,是前向LSTM和后向LSTM的隐藏层的拼接。前向和后向文本可被认为是同时的。
4 语言正则LSTM
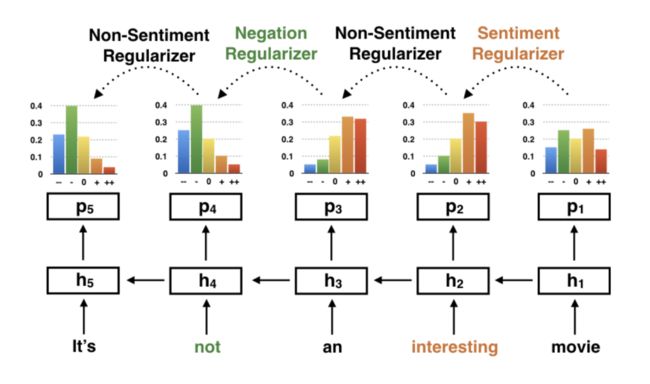
这个paper的中心想法是建模情感,否定和强度词的语言角色在句子级别的情感分类上通过正则化句子邻近位置的输出。例如在Fig 1,句子“It’s not an interesting movie”,预测的情感分布在“an interesting movie2”和“interesting movie”应该分别相近,当预测的情感分布在“interesting movie”应该相当不同于之前的位置(在后向方向)(“movie”)只要一个情感词(“in- teresting”) 出现。
我们提出一个一般正则化和三个特别正则化基于下列语言观察:
•非情感正则化: 如果两个相近位置都是非意见词,这两个位置的情感分布应该互相靠近。尽管不是总是正确(也就是肥皂剧),这个假设大多数都正确。
•情感正则化: 如果这个词是一个词典中的情感词,当前位置的情感分布应该重大的不同于之后或之前的位置。我们接近这个现象用一个情感类别特别转换分布。
•否定正则化: 否定词例如“not”和“never”是关键的情感转换器:一般的它们转换情感极性从正向end到负向end,但是有时依赖否定词和它们修饰的词。这个否定正则化建模这个语言现象随着一个特别否定转换矩阵。
•强度正则化: 强度词例如“vary”和“extremely”改变一个句子标的的valence程度:例如,从正向到非常正向。建模这个影响相当重要对于细粒化情感分类,并且情感正则化被设计为用公式表示这个影响通过特别词转换矩阵。
更正式的,预测的情感分布(p_t基于h_t,查看公式5)在位置t应该语言正则化依赖前一个(t-1)和后一个(t+1)的位置。为了增强模型产生连贯的预测,我们插入一个新的loss术语到原始的cross entropy loss:
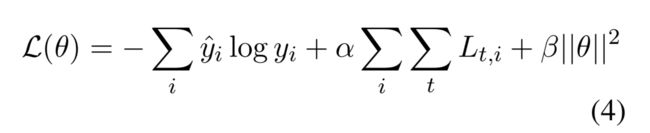
其中\bar y_i是金分布对于句子i,y_i是预测分布,L_t,i是其中一个句子i的正则化或者正则化的组合,是一个正则术语的权重,是句子中词位置。
值得注意 我们不考虑否定和强化词的修正范围去保持提出的模型的简单性。否定范围分辨率是另一个复杂的问题已经被【】广泛的学习,超过了这个工作的范围。代替的,我们凭借序列LSTM用于编码周围的内容在给定的位置。
4.1 非情感正则化矩阵(NSR)
这个正则化矩阵不应该非常约束邻近位置的情感分布,如果额外的输入词x_t不是一个情感词,公式如下:
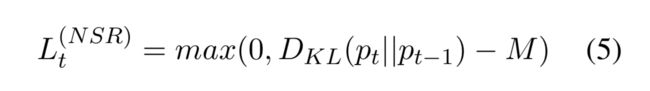
其中M是一个用于margin的超参数,p_t是位置t的状态的预测分布,(也就是h_t),而且D_{KL}(p||q)是一个对称的KL分歧定义如下:
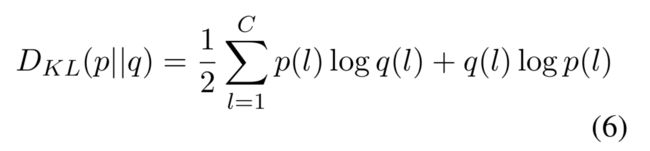
其中p,q是在情感标记l上的分布,C是标记的数量。
4.2 情感正则化矩阵(SR)
这个情感正则化矩阵约束邻近位置的句子分布应该因此drift,如果输入词是一个情感词。让我们再看这个例子“It’s not an interesting movie”。在位置t=2(反向方向)我们看到一个正向词“interesting”所以预测分布将会更正向,相比于在位置t=1(movie)。这是一个情感drift的问题。
为了解决情感drift问题,我们提出一个极性shift分布s_c \in R^C对于每个词典中定义的情感类别。例如,一个情感词典可能有类别标签例如强负向、弱负向、弱正向、强正向,且对每个类别,有一个shift分布会被这个模型学习。这个情感正则矩阵表明如果当前的词是一个情感词,这个情感分布drift应该对比之前的位置观察,具体如下:
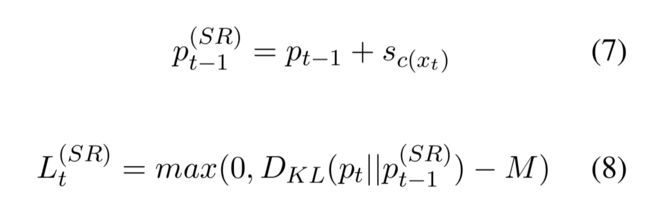
其中p^{(SR)}_{t-1}是考虑了shift情感分布相符于位置t的状态后的drift情感分布,c(x_t)是词x_t的先验情感类别,且s_c \in \theta是一个需要优化的参数,但是也可以随着先验知识固定设置。注意到这种方法的所有同样情感类别的词共享同样的drifting distribution,但在一个精确的设置中,我们可以学习一个shifting distribution对每个情感词,如果有可用的大规模数据集。
4.3 否定正则化矩阵(NR)
这个否定正则化方法如何否定词shift这个更改的文本的情感分布。当输入x_t是一个否定词,这个情感分布应该因此shifted/reversed。然而,这个否定角色比情感词更复杂,例如not good和not bad中的not有不同的角色在极性改变中。前一个改变为否定的极性,后一个改变为中性。
为了尊敬这个复杂的否定影响,我们提出一个转换矩阵T_m \in R^{C×C}用于每个否定词m,且这个矩阵将会被模型学习。这个正则化矩阵认为如果当前位置是一个否定词,这个当前位置的情感分布应该紧邻下一个或前一个位置伴随着转换。
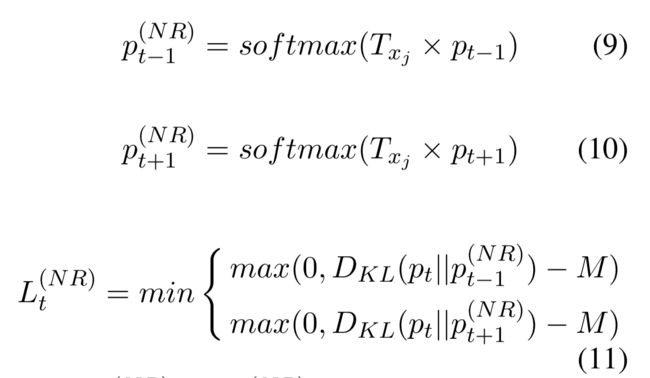
其中和是情感分布在转换之后,是转换矩阵为了一个否定词,一个训练中被学习的参数。总的,我们训练m各转换矩阵对于m个否定词。如此negator-specific转换一致于每个否定词有它独立的否定反应的发现。
4.4 强度正则化(IR)
一个短语的情感强度表明相关情感的强度,对于细粒化情感分类或排序相当重要。强化因子可以改变内容词的valence程度。这个强度正则化矩阵建模了如何强化词影响短语或句子的情感valence。
这个强度影响的表达和否定正则化矩阵一样,但是拥有不同的参数。对每个强化词,有一个转换矩阵去赋予不同强化器的不同角色在情感drift时。简短的,我们将不会重复这个公式。
4.5 应用语言正则化到双向LSTM
去保持我们提议的简单性,我们不考虑否定词和强化词的修正范围,也是一个有挑战的问题在NLP团体。然而,我们可以减轻问题通过杠杆双向LSTM。
对于单个LSTM,我们采用一个反向LSTM从句子的后向前。这是因为,在最多的时候,否定词和强度词的修正的词通常在修正文本的右侧。但有时修正的词否定词和强度词的左边。为了解决这个问题,我们采用双向LSTM并让模型决定应该选择哪边。
正式的,双向LSTM,我们计算一个转换情感分布在前向LSTM的p_{t-1}和在后向LSTM的p_{t+1},计算两个分布上当前位置分布的最小距离,公式如下:
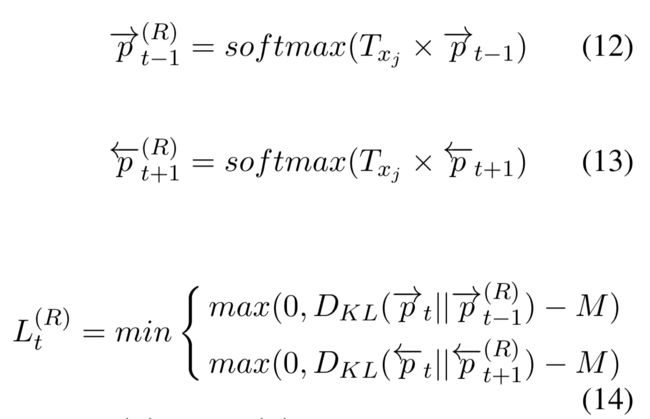
其中p^{(R)}_{t-1}和p^{(R)}_{t+1}是分别由前一个分布p_{t-1}和下一个分布p_{t+1}转换的情感分布。注意到R \in {NR,IR}表明否定和强度正则化的公式化。
由于相同的考虑,我们相似的重新定义L^{(NSR)}_t和L^{SR}_t伴随双向LSTM。公式相同,为了简化省略。
4.6 讨论
我们的模型通过数学运算解决这些语言因素,伴随shifting distribution向量或者转换矩阵参数化。在这个情感正则化,这个情感shifting反应通过一个class-specific分布参数化(如果有更多数据,还可以word-specific)。在否定和强度正则化矩阵下,反应伴随word-specific转换矩阵参数化。这是为了尊重否定词和强度词是如何shift情感表达的机制是相当复杂和高度依赖单个词的事实。否定/强度反应还依赖修正文本的语法和语义,然而,为了简单性我们凭借序列LSTM去编码周围文本在这个paper中。我们部分的处理这个修正范围问题通过应用最小化运算在公式11和14中,和双向LSTM。
5 实验
5.1 数据集和情感词典
两个数据集被用到评估提出的模型:影评(MR)其中每个句子标注两个分类正向和负向,和Stanford Sentiment Treebank(SST)伴随五个类别{very negative, negative, neutral, pos- itive, very positive}。注意到SST提供phrase-level标注在所有内节点,但我们仅仅使用sentence-level标注由于我们的目标之一是避免昂贵的phrase-level标注。
这个情感词典包括两个部分。第一部分来自MPQA,其中包括5153个情感词,每个有极性评分。第二部分由SST数据集(所有情感词)的叶节点和6886个极性词(除去中性词)构成。我们结合这两个部分并忽略有冲突情感标记的词,并产生一个9750个词和4个情感标记的词典。对于否定词和强度词,我们人工收集这些由于数量小,其中一些展示在Table 2。
5.2 实验设置具体细节
为了使得他人可以重现我们的结果,我们呈现我们的模型所有的细节。我们采用Glove向量作为词embedding V的初始设置。对每个情感类别(s_c)的shifting vector,和为了否定和强化的转换矩阵(T_m)是初始化为初值。其他隐藏层参数(W^{(*)}),U^{(*)},S初始为Uniform(0,1/sqrt(d)),其中d是隐藏表示的维度,我们设置为d=300。我们采用adaGrad训练模型,学习率为0.1。值得注意的是,我们采用随机梯度下降更新词embedding(V),随着一个学习率0.2,但没有momentum。
最优设置对α and β分别是0.5和0.0001。在训练中,我们以0.5的概率在softmax层之前采用dropout运算。训练时采用mini-batch,每个batch包括25个样例。在训练3000mini-batch后,(大约9epoch在MR上和10epoch在SST上),我们选择验证数据集上模型结果最好的作为最终表现。

5.3 全部对比
我们包括了一个基准方法,列下:
RNN/RNTN:由【】提出的在语法分析上的RNN,和Recursive Tensor Neural Network采用张量在不同维度的子节点向量之间去建模相关性。
LSTM/Bi-LSTM:LSTM和双向变量就如之前介绍的。
Tree-LSTM:树结构LSTM引入记忆cell和门到树结构神经网络。
CNN:卷积神经网络产生句子表示通过卷积和池化运算。
CNN-Tensor:在【】,这个卷积运算被替代为张量积和一个动态规划被应用到枚举所有skippable trigram在一个句子中。十分强的结果被呈现。
DAN:Deep Average Netword平均一个句子的所有词向量并连接一个MLP层到输出层。
Neural Context-Sensitive Lexicon:NCSL对待一个句子的情感分数为权重加总的句子中词的初始分数其中权重通过神经网络学习。

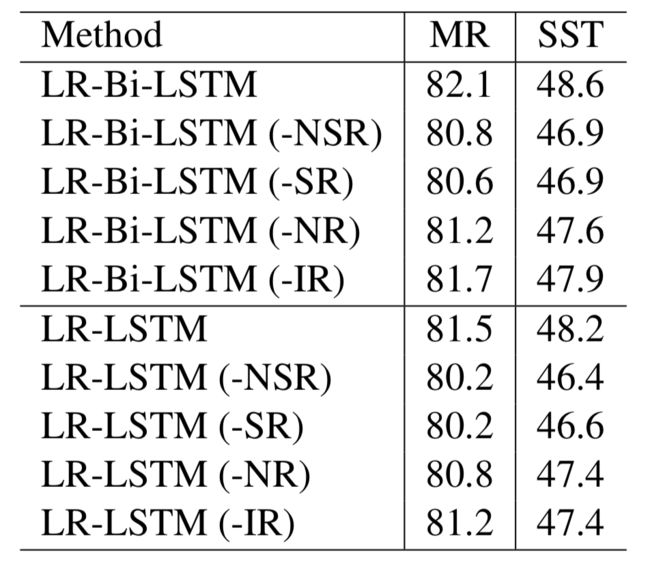
首先,我们评估我们的模型在MR数据集,结果展示在Table 3。我们有如下观察:
首先,LR-LSTM和LR-Bi-LSTM表现好于他们的对应(81.5%vs77.4%和82.1%vs79.3%,分别),证明语言正则化的有效性。
其次,LR-LSTM和LR-Bi-LSTM表现一点点好于Tree-LSTM但Tree-LSTM杠杆一个constituency树结构当我们的模型是一个简单序列模型。作为将来的工作,我们将会采用如此正则化到树结构模型。
最后,在MR数据集上,我们的模型略微好于CNN。
对于细粒化情感分类,我们评估我们的模型在SST数据集伴随5个情感分类 { very negative, negative, neutral, positive, very positive} ,从而我们可以评估强度词的情感shifting结果。这个结果展示在Table 3。我们有如下观察:
首先,语言正则化LSTM和Bi-LSTM由于它的对比。值得注意LR-Bi-LSTM(训练伴随着仅仅句子级别的标注)更好于使用短语级别注释训练的Bi-LSTM。这表示LR-Bi-LSTM可以避免繁重的短语级别的注释但依然获得相当的结果。
其次,我们的模型比得上Tree-LSTM但是我们的模型不依赖一个语法分析树且更简单,因此更有效率。更多,对于Tree-LSTM,这个模型十分依赖短语级别标注,不然表现相当多的降低。
最后,在SST数据集,我们的模型好于CNN,DAN和NCSL。我们推测CNN-Tensor的好的表现可能由于张量积的运算,所有skippable trigram的枚举和拼接的所有池化层的表示用于最后分类。
5.4 不同正则化的结果
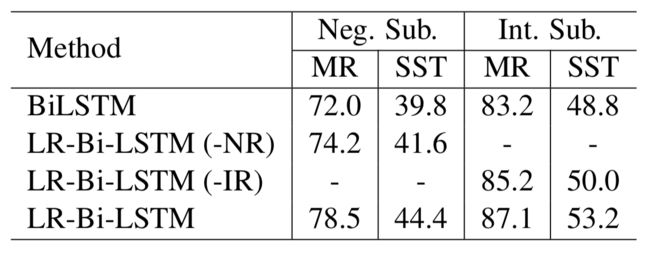
为了展现每个单独的正则化的结果,我们执行消融实验。每次,我们移除一个正则化矩阵并观察结果变化如何。首先,我们执行这个实验在整个数据集,并实验在子数据集仅仅包括否定词或强度词。
这个实验结果展示在Table 4,其中我们可以看到non-sentiment regularizer(NSR)和sentiment regularizer(SR)扮演关键的角色,这个negation regularizer和intensity regularizer是有效的,但是没有NSR和SR重要。这可能是因为仅仅14%的句子包括negation词在测试集,23%包括intensity词,因此我们更多的评估这个模型在两个子集,展示在Table 5。
这个实验在子集展示在:1)伴随着linguistic regularizer,LR-Bi-LSTM在这些数据集上十分优于Bi-LSTM;2)当negation regularizer从模型中被移除,在MR和SST子集上表现极大降低;3)相似的观察可以发现依据intensity regularizer。
5.5 Negation Regularizer结果
为了更远的揭示negation词的语言角色,我们对比一个短语对的带和不带否定词的预测的情感分布。这个情感结果执行在MR展示在Fig. 2。每个点表示一个短语对,(例如,[1 − y, y] = softmax(T_nw ∗ [1 − x,x])其中[1 − x,x]是一个在[negative, positive]的情感分布,x是不带negator的短语的正向分数且y是带negator的短语的情感分布,T_{nw}是转换矩阵对于否定词nw,公式9。对于查看我们模型的细节结果,我们有如下描述:
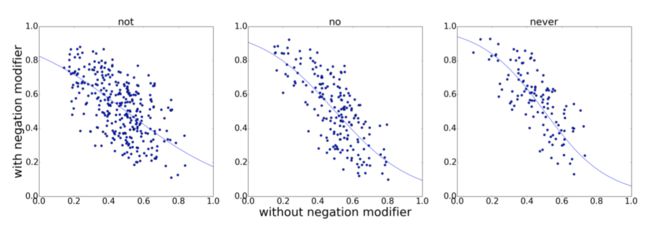
首先,没有点在右上和坐下块,表明否定词一般转换十分正向后十分负向短语到其他极性。特别的短语包括not very good, not too bad。
其次,左上和右下的点分别表明否定结果:改变负向到正向和正向到负向。特别的短语包括never seems hopelessly (up-left), no good scenes (bottom-right), not interesting (bottom-right)等等。还有一些正向/负向短语转换到中性情感例如 not so good, and not too bad。
最后,点在中心表明中性短语保持中性情感伴随着否定词。特别的短语包括not at home, not here,其中否定词改进非情感词。
5.6 强化正则矩阵的结果
进一步揭示强度词的语言角色,我们执行实验在SST数据集,展示在Figure 3。我们展示矩阵表明在被强化词修正以后情感如何转换。每个cell(m_ij)中的数据表明多少情感标记为i的短语被预测但是有强度词的预测的短语改变标记到j。例如,cell的m_21的数字20在第二个矩阵,表示这里有20个短语预测伴随一个负向类别,但是预测改变到十分负向在被强度词修正后。

第一个矩阵的结果表明,对于most,有21/21/13/12个短语在被强度词修正后情感转换了,从负向到十分负向(most irresponsible picture),正向到十分正向(most famous author),中性到负向(most plain),中性到正向(most closely)。
还有许多短语保留原情感在被强度词修正后,对于十分正向/负向短语,短语被强度词修正依然保持强情感。对于左边的短语,他们进入三个分类:首先被强度词修正的词是非情感词,例如most of us, most part;第二,强度词不够强到转换情感,例如 most complex(from neg. to neg.), most traditional (from pos. to pos.);第三,我们的模型伴随强度词没有转换情感例如most vital, most resonant film。
6 总结和将来工作
我们呈现语言正则化的LSTM用于句子级别的情感分类。提出的模型处理情感词、否定词、强度词的sentient转换结果。更多,我们模型是序列LSTM从而不依赖语法分析树结构而且不需要昂贵的短语级别的注释。结果表明我们明星可以处理情感词、否定词。强度词的语言角色。
为了提出模型的保存简单性,我们不考虑否定词和强度词的修正范围,尽管我们部分处理这个问题通过应用一个最小化运算(公式11,公式14)和双向LSTM。将来工作,我们计划应用语言正则化到tree-LSTM去处理范围问题由于语法分析书更简单明确描述修正范围。