前言:自Google发表三大论文GFS、MapReduce、BigTable以来,衍生出的开源框架越来越多,其中Hadoop更是以高可用、高扩展、高容错等特性形成了开源工业界事实标准。Hadoop是一个可以搭建在廉价PC上的分布式集群生态体系,用户可以在不清楚底层运行细节的情况下,开发出自己的分布式应用。但是Hadoop MapReduce由于其设计初衷并不是为了满足循环式数据流处理,因此在多并行运行的数据可复用场景(如:迭代式机器学习、交互式数据处理)中存在诸多的问题,所以Spark应运而生。Spark在传统的Mapreduce计算框架的基础上,将计算单元缩小到更适合并行计算和重复使用的RDD。
一、 什么是RDD?
二、 RDD是怎样形成的?
三、 RDD结构拆分及源码解读
一、 什么是RDD?
RDD(Resilient Distributed Datasets),是Spark最为核心的概念。
从字面上,直译为弹性分布式数据集。所谓“弹性”,一种简单解释是指RDD是横向多分区的,纵向当计算过程中内存不足时可刷写到磁盘等外存上,可与外存做灵活的数据交换;而另一种个人更偏向的解释是RDD是由虚拟数据结构组成,并不包含真实数据本体,RDD使用了一种“血统”的容错机制,在结构更新和丢失后可随时根据血统进行数据模型的重建。所谓“分布式”,就是可以分布在多台机器上进行并行计算。
从空间结构上,可以理解为是一组只读的、可分区的分布式数据集合,该集合内包含了多个分区。分区就是依照特定规则,将具有相同属性的数据记录放在一起。每个分区相当于一个数据集片段。下图简单表示了一个RDD的结构:

RDD是一个只读的有属性的数据集。属性用来描述当前数据集的状态,数据集是由数据的分区(partition)组成,并(由block)映射成真实数据。RDD属性包括名称、分区类型、父RDD指针、数据本地化、数据依赖关系等,主要属性可以分为3类:
- 与其他RDD 的关系(parents)
- 数据(partitioner,checkpoint,storagelevel,iterator)
- RDD自身属性(rddname,sparkcontext,sparkconf)
之后RDD源码解析里详细介绍每个属性。
二、 RDD是怎样形成的?
有需要在Spark内计算的数据即形成RDD,所以开始输入到Spark的数据和经过Spark算子(下文介绍算子)计算过的数据都会形成RDD,包括即将输出的数据也会生成RDD后统一输出的。如图。
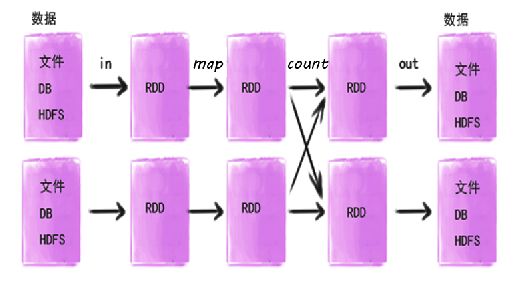
关于RDD的形成, 主要是通过连接物理存储输入的数据集和在已有RDD基础上进行相关计算操作衍生的。下面我们就通过一个大数据开源生态经典的例子(Wordcount)来描述下RDD的产生过程。强大的Scala代码如下。

初识的小伙伴们会感觉很神奇,四行代码就全部搞定了吗,之前的MR代码可是码了一大堆呢……的确如此想学好Spark的小伙伴们,还是要掌握Scala这门语言,废话不多说,简单解释下这几行代码:
第一行,从HDFS上读取in.txt文件,创建了第一个RDD
第二行,按空格分词,扁平化处理,生成第二个RDD,每个词计数为1,生成了第三个RDD。这里可能有人会问,为什么生成了两个RDD呢,因为此行代码RDD经过了两次算子转换(transformation)操作。关于算子这里不多详述,请关注下期文章。
第三行,按每个词分组,累加求和,生成第四个RDD
第四行,将Wordcount统计结果输出到HDFS
整个产生过程如下图所示:

RDD的依赖关系
通过上文的例子可以了解到,一个作业从开始到结束的计算过程中产生了多个RDD,RDD之间是彼此相互依赖的,我们把这种父子依赖的关系,称之为“血统”。如果父RDD的每个分区最多只能被子RDD的一个分区使用,我们称之为(narrow dependency)窄依赖;若一个父RDD的每个分区可以被子RDD的多个分区使用,我们称之为(wide dependency)宽依赖。简单来讲窄依赖就是父子RDD分区间”一对一“的关系,宽依赖就是”一对多“关系,具体理解可参考下图:

那么为什么Spark要将依赖分成这两种呢,下面我们就了解下原因:
首先,从计算过程来看,窄依赖是数据以管道方式经一系列计算操作可以运行在了一个集群节点上,如(map、filter等),宽依赖则可能需要将数据通过跨节点传递后运行(如groupByKey),有点类似于MR的shuffle过程。
其次,从失败恢复来看,窄依赖的失败恢复起来更高效,因为它只需找到父RDD的一个对应分区即可,而且可以在不同节点上并行计算做恢复;宽依赖则牵涉到父RDD的多个分区,恢复起来相对复杂些。
综上, 这里引入了一个新的概念Stage。Stage可以简单理解为是由一组RDD组成的可进行优化的执行计划。如果RDD的衍生关系都是窄依赖,则可放在同一个Stage中运行,若RDD的依赖关系为宽依赖,则要划分到不同的Stage。这样Spark在执行作业时,会按照Stage的划分, 生成一个完整的最优的执行计划。下面引用一张比较流行的图片辅助大家理解Stage,如图RDD¬-A到RDD-B和RDD-F到RDD-G均属于宽依赖,所以与前面的父RDD划分到了不同的Stage中。

三、 RDD结构拆分及源码解读
到这里,相信大家已经对RDD有了大体的了解,但要详细了解RDD的内部结构,请继续耐心往下看。先贴一张RDD的内部结构图

RDD 的属性主要包括(rddname、sparkcontext、sparkconf、parent、dependency、partitioner、checkpoint、storageLevel),下面我们先简单逐一了解下:
1.rddname
即rdd的名称
2.sparkcontext
SparkContext为Spark job的入口,由Spark driver创建在client端,包括集群连接,RddID,创建抽样,累加器,广播变量等信息。
3.sparkconf配置信息,即sc.conf
Spark参数配置信息
提供三个位置用来配置系统:
Spark api:控制大部分的应用程序参数,可以用SparkConf对象或者Java系统属性设置
环境变量:可以通过每个节点的conf/spark-env.sh脚本设置。例如IP地址、端口等信息
日志配置:可以通过log4j.properties配置
4.parent
指向依赖父RDD的partition id,利用dependencies方法可以查找该RDD所依赖的partiton id的List集合,即上图中的parents。
5.iterator
迭代器,用来查找当前RDD Partition与父RDD中Partition的血缘关系。并通过StorageLevel确定迭代位置,直到确定真实数据的位置。迭代方式分为checkpoint迭代和RDD迭代, 如果StorageLevel为NONE则执行computeOrReadCheckpoint计算并获取数据,此方法也是一个迭代器,迭代checkpoint数据存放位置,迭代出口为找到真实数据或内存。如果Storagelevel不为空,根据存储级别进入RDD迭代器,继续迭代父RDD的结构,迭代出口为真实数据或内存。迭代器内部有数据本地化判断,先从本地获取数据,如果没有则远程查找。
6.prisist
rdd存储的level,即通过storagelevel和是否可覆盖判断,
storagelevel分为 5中状态 ,useDisk, useMemory, useOffHeap, deserialized, replication 可组合使用。
if (useOffHeap) {
require(!useDisk, "Off-heap storage level does not support using disk")
require(!useMemory, "Off-heap storage level does not support using heap memory") require(!deserialized, "Off-heap storage level does not support deserialized storage") require(replication == 1, "Off-heap storage level does not support multiple replication") }
persist :
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
// If this is the first time this RDD is marked for persisting, register it
// with the SparkContext for cleanups and accounting. Do this only once.
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
storageLevel = newLevel
this
}
7.partitioner 分区方式
RDD的分区方式。RDD的分区方式主要包含两种(Hash和Range),这两种分区类型都是针对K-V类型的数据。如是非K-V类型,则分区为None。 Hash是以key作为分区条件的散列分布,分区数据不连续,极端情况也可能散列到少数几个分区上,导致数据不均等;Range按Key的排序平衡分布,分区内数据连续,大小也相对均等。
8.checkpoint
Spark提供的一种缓存机制,当需要计算的RDD过多时,为了避免重新计算之前的RDD,可以对RDD做checkpoint处理,检查RDD是否被物化或计算,并将结果持久化到磁盘或HDFS。与spark提供的另一种缓存机制cache相比, cache缓存数据由executor管理,当executor消失了,被cache的数据将被清除,RDD重新计算,而checkpoint将数据保存到磁盘或HDFS,job可以从checkpoint点继续计算。
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
9.storageLevel
一个枚举类型,用来记录RDD的存储级别。存储介质主要包括内存、磁盘和堆外内存,另外还包含是否序列化操作以及副本数量。如:MEMORY_AND_DISK_SER代表数据可以存储在内存和磁盘,并且以序列化的方式存储。是判断数据是否保存磁盘或者内存的条件。
storagelevel结构:
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
综上所述Spark RDD和Spark RDD算子组成了计算的基本单位,并由数据流向的依赖关系形成非循环数据流模型(DAG),形成Spark基础计算框架。
spark 盖中盖五连载
RDD算子详解