背景知识:
- mach-o文件为基于Mach核心的操作系统的可执行文件、目标代码或动态库,是.out的代替,其提供了更强的扩展性并提升了符号表中信息的访问速度,
- 符号表,用于标记源代码中包括标识符、声明信息、行号、函数名称等元素的具体信息,比如说数据类型、作用域以及内存地址,iOS符号表在dSYM文件中
- 程序构建过程:编译分三步走,对
源文件进行预处理(processing),处理预编译指令,生成.i文件,下一步进行编译,进行词法分析(lex工具识别词法规则语义表)、语法分析和语义分析生成.s汇编文件,最后进行汇编,生成二进制目标文件.o。目标文件再进行链接器链接,形成可执行文件.a或mach-o文件。 - 链接分为动态链接和静态链接,静态链接会将所有目标文件.o全部内容链接到执行文件中,如果另外的执行文件需要其中的功能,也必须全部收录。动态链接为了解决这样的空间浪费问题,只将函数信息链接加入执行文件
- dyld是加载动态链接库的库,该库在加载可执行文件的时候,递归加载所需要的所有动态库。动态库包括iOS操作系统的系统framework,oc的runtime系统libobjc,系统级别的库libSystem,例如libdispatch(GCD)、libsystem_block(Block)
App启动大致流程
对于一个可执行文件来说,它的加载过程是:
分为两大部分:
- pre-main 指的是操作系统开始执行一个可执行文件,并完成进程创建、执行文件加载、动态链接、环境配置
- main 指的是从加载main函数入口以后,到app delegate完成加载回调的过程
操作系统加载App可执行文件
操作系统加载可执行文件,通过fork(创建一个进程)指令在新的空间内来执行可执行文件,加载依赖的可执行文件(mach-o)文件,定位其内部与外部指针引用,例如字符串与函数,执行声明为attribute((constructor))的C函数,加载扩展(Category)中的方法,C++静态对象加载,调用ObjC的+load函数

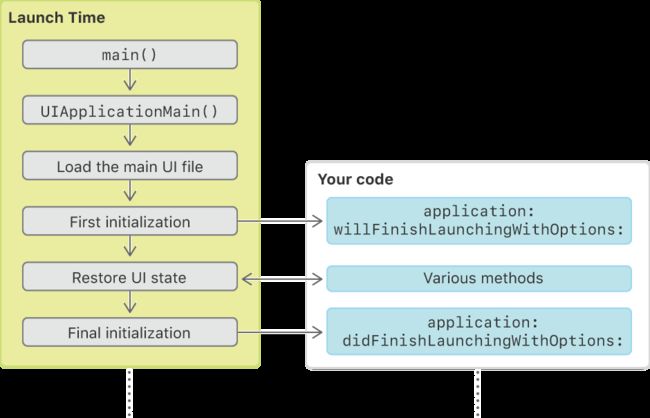
基本流程:
App 开始启动后,系统首先加载可执行文件(自身 App 的所有 .o 文件的集合),然后加载动态链接器 dyld,dyld 是一个专门用来加载动态链接库的库。 执行从 dyld 开始,dyld 从可执行文件的依赖开始,递归加载所有的依赖动态链接库。
动态链接库包括:iOS 中用到的所有系统 framework,加载 OC runtime 方法的 libobjc,系统级别的 libSystem,例如 libdispatch(GCD) 和 libsystem_blocks (Block)。
dyld加载动态库
动态链接库的加载过程主要由dyld来完成,dyld是苹果的动态链接器。
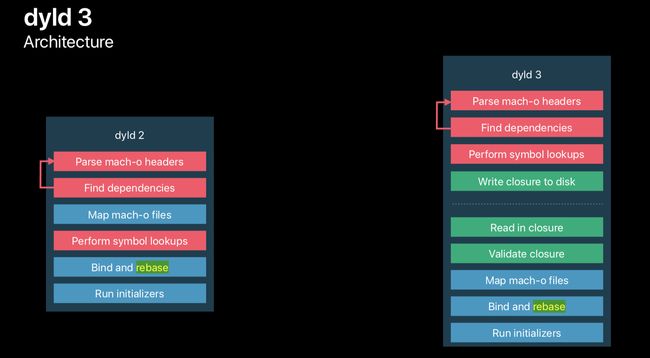
- 系统先读取App的可执行文件(Mach-O文件)里的mach-o headers
- dyld去初始化运行环境,从里面获得动态依赖,开启缓存策略,加载程序相关依赖库(其中也包含我们的可执行文件),并对这些库进行链接,最后调用每个依赖库的初始化方法,在这一步,runtime被初始化。当所有依赖库的初始化后,轮到最后一位(程序可执行文件)进行初始化。
- 检查和确认符号表的是否存在和正确
- Map所有mach-o文件,用来整体统计变量声明、函数调用等信息
- 进行bind操作,对从其他库的引用的符号、函数等,进行其内存地址进行修正绑定
- 进行rebase操作,对自身库内部的引用进行修正
- 进行runtime系统初始化,会对项目中所有类进行类结构初始化,然后调用所有的load方法。
- 最后dyld返回main函数地址,main函数被调用,我们便来到了熟悉的程序入口。
当加载一个 Mach-O 文件 (一个可执行文件或者一个库) 时,动态链接器首先会检查共享缓存看看是否存在其中,如果存在,那么就直接从共享缓存中拿出来使用。每一个进程都把这个共享缓存映射到了自己的地址空间中。这个方法大大优化了 OS X 和 iOS 上程序的启动时间。
Mach-O 镜像文件
官方文档:
https://developer.apple.com/library/archive/documentation/Performance/Conceptual/CodeFootprint/Articles/MachOOverview.htm
Mach-O是OS X中二进制文件的本机可执行格式,是传送代码的首选格式。可执行格式确定二进制文件中的代码和数据被读入内存的顺序。代码和数据的排序会影响内存使用和分页活动,从而直接影响程序的性能。段的大小通过其包含的所有段中的字节数来度量,并向上舍入到下一个虚拟内存页边界。
Mach-O二进制文件被组织成segements。每个segement包含一个或多个部分。每个部分都有不同类型的代码或数据。segement始终从页面边界开始,但section不一定是页面对齐的。因此,segement终是4096字节或4千字节的倍数,其中4096字节是最小大小。
Mach-O可执行文件的segement和section根据其预期用途命名。segement名称的约定是使用以双下划线开头的全大写字母(例如,TEXT); section名称的约定是使用以双下划线开头的全小写字母(例如, text)。
Mach-O可执行文件中有几个可能的segements,但只有两个与性能有关:__TEXT段和__DATA段。
The __TEXT Segment: Read Only
__TEXT segment是包含可执行代码和常量数据的只读区域。按照惯例,编译器工具创建具有至少一个只读__TEXT segment的每个可执行文件。由于该段是只读的,因此内核可以将__TEXT segment直接从可执行文件映射到内存中一次。当segment被映射到内存时,它可以在所有进程之间共享其内容。 (这主要是框架和其他共享库的情况。)只读属性还意味着构成__TEXT segment的页面永远不必保存到后备存储。如果内核需要释放物理内存,它可以丢弃一个或多个__TEXT页面,并在需要时从磁盘重新读取它们。
__TEXT segment的主要部分,sections分布
- __text 已编译的可执行文件的机器代码
- __const 一般的常量数据
- __cstring 文字字符串常量(源代码中的引用字符串)
- __picsymbol_stub 动态链接器(dyld)使用的与位置无关的代码存根例程
The __DATA Segment: Read/Write
__DATA segment 包含可执行文件的非常量变量。该 segement 是可读写的,因为它是可写的,所以对于与库链接的每个进程,逻辑上复制静态库或其他动态共享库的__DATA段。当内存页面可读写时,内核会使其变为copy-on-write。此技术可以做到,动态库是在内存中共享的,可以被其他各个进程访问,但因为__DATA Segment是可读可写的,就会通过某一进程对共享的_DATA Segment有写操作的时候,再进行单独的_DATA内存空间复制。
__DATA segment 有许多部分,其中一些仅由动态链接器使用。下面 列出了可以出现在__DATA segment 中的一些更重要的部分。有关段的完整列表,请参阅Mach-O运行时体系结构。
- __data 初始化的全局变量(例如int a = 1;或static int a = 1;)。
- __const 需要重定位的常量数据(例如,char * const p =“foo”;)
- __bss 未初始化的静态变量(例如,static int a;)。
- __common 未初始化的外部全局变量(例如,int a;外部功能块)。
- __dyld 占位符部分,由动态链接器使用。
- __la_symbol_ptr lazy符号指针。可执行文件调用的每个未定义函数的符号指针。
- __nl_symbol_ptr 非lazy符号指针。可执行文件引用的每个未定义数据符号的符号指针。
Mach-O 性能影响
Mach-O可执行文件的__TEXT segment和__DATA segment的组成与性能有直接关系。优化这些sections的技术和目的是不同的。但是,它们的共同目标是:提高内存使用效率。
最典型的Mach-O的文件由可执行代码组成,在__TEXT,__text当中。如__TEXT segment,该__TEXT是只读的,并直接映射到可执行文件,所以如果内核需要回收某些__text页面占用的物理内存,就不必将页面保存到back store再将其分页。它只需要释放内存,并在后面代码引用的时候从磁盘重新读回。虽然这比交换内存分页的成本低,因为这只是一个磁盘访问,而不是两个内存分页的交换 , 但这仍然很损耗性能,特别是如果必须从磁盘重新创建许多页面。
对于这种情况的改进,是通过程序重新排序来改进代码的引用位置,如改进参考位置中所述。该技术将方法和功能组合在一起,具体取决于它们的执行顺序,调用频率以及它们相互调用的频率。如果__text部分组中的页面以这种方式逻辑上起作用,则它们不太可能被多次释放和读回。例如,如果将所有启动时初始化函数放在一个或两个页面上,则在发生初始化后不必重新创建页面。
与__TEXT段不同,__DATA可以写入段,因此段中的页面__DATA不可共享。框架中的非常量全局变量可能会对性能产生影响,因为与框架链接的每个进程都会获得这些变量的副本。解决这个问题的主要解决办法是尽可能多的非恒定的全局变量尽可能转移到__TEXT,__const通过宣布他们部分const。减少共享内存页面描述了此技术和相关技术。这通常不是应用程序的问题,因为应用程序中的__DATA部分不与其他应用程序共享。
编译器将不同类型的非常量全局数据存储在段的不同部分中__DATA。这些类型的数据是未初始化的静态数据和符号与未声明的“暂定定义”的ANSI C概念一致extern。未初始化的静态数据位于__bss段的__DATA部分中。暂定的符号在__common 该__DATA部分。
该 ANSI C和 C ++标准指定系统必须将未初始化的静态变量设置为零。(未初始化的其他类型的未初始化数据。)由于未初始化的静态变量和临时定义符号存储在单独的部分中,因此系统需要以不同方式对待它们。但是当变量位于不同的部分时,它们更有可能最终出现在不同的内存页面上,因此可以单独进行交换,从而使代码运行速度变慢。如减少共享内存页面中所述,这些问题的解决方案是在段的一个部分中合并非常量全局数据__DATA。
ObjC Runtime
dyld的加载过程会初始化Runtime系统,在此阶段,有相当多的优化工作可以做

这过程包括:
- 所有类型的定义和注册,Objective-C的类不是编译器决定的,是运行时动态载入到全局表中的
- 非脆弱的ivars变量抵消更新,修改实例变量的内存地址偏移问题
- 分类替换并添加到方法列表中,将分类中的方法加载到方法列表中
- 确认选择器全局唯一
Initializers 阶段
在Runtime系统加载以后,开始进行初始化

- Objc的+load()函数
- C++的构造函数属性函数 形如attribute((constructor)) void DoSomeInitializationWork()
- 非基本类型的C++静态全局变量的创建(通常是类或结构体)(non-trivial initializer) 比如一个全局静态结构体的构建,如果在构造函数中有繁重的工作,那么会拖慢启动速度
pre-main阶段分析
从上面可以得出以下几个结论,影响该阶段启动时间的因素如下:
- Mach-O可执行文件的加载和内存重新分配规划,对于其segment和section进行虚拟内存的分页管理的调度
- dyld动态链接内存中的公共镜像,在运行时进行检查共享数据和链接调用
- Runtime的初始化,包括class注册、category加载、变量对齐等
- C++静态对象和全局变量的加载
- ObjeC所有load函数的调用加载
优化措施:
- 减少ObjC的类膨胀问题,清理没有使用的类,合并松散无用的类
- 减少静态变量的声明和初始化的分离
static int x;
static short conv_table [128];
//更换为
static int x = 0;
static short conv_table [128] = {0};
减少静态变量的使用
- 减少符号表的导出
通过设置-exported_symbols_list或-unexported_symbols_lis来限制符号表的导出,从而减少dyld的工作量 - 去除没有使用的动态库依赖,明确所依赖的frameworks是require还是optional,optional会动态进行额外检查
- 删除没有用的方法
- 减少+load函数的实现,并减少在其中操作的逻辑
- 对某些经常调用的代码进行二进制化,生成静态库,多使用静态库代替动态库,将多个静态库框架,集中制作成静态framework,从而能够减少dyld的链接工作
关于冷启动和热启动的不同如下:

main阶段

从上图可以得到,影响main阶段的启动时间因素是:
- AppDelegate代理的加载生命周期回调
- Application Window的布局、绘制和加载
- RootViewController的加载
优化点: - 压缩和减小启动图片
- 尽量不使用storyboard或者是nib来布局rootViewController
- 在didFinishLaunchingWithOptions阶段,尽可能减少阻塞代码的执行,可以利用多线程进行加载逻辑的处理,注意多线程对主线程同步阻塞可能造成的黑屏问题
- 将非同步需求的初始化逻辑进行异步加载