Flume简介
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统
核心概念:
Agent:一个agent就是一个JVM进程,一个agent中包含多个sources和sinks。
Client:生产数据。
Source:从Client收集数据,传递给Channel。
Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
Sink:从Channel收集数据,运行在一个独立线程。
Events:可以是日志记录、avro对象等。
基本结构:
Flume以agent为最小的独立运行单位。单agent由Source、Sink和Channel三大组件构成,
如下图:

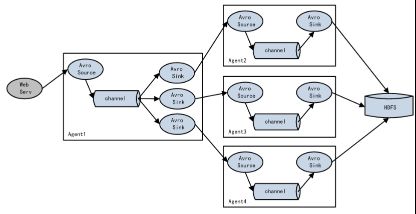
复杂结构:
Flume agent可以根据需求配置成多种形式的拓扑结构
Agent顺序连接

Agent联合

多路复用

网络流:
Flume支持Avro、Thrift、Syslog、Netcat流数据采集
Source

主要参数配置

其中threads决定最多有多少个线程来处理RPC请求

通过org.jboss.netty实现,启动一个Netty Server来提供RPC服务
socketChannelFactory:主要负责生产网络通信相关的Channel和ChannelSink实例,NIO Server端一般使用NioServerSocketChannelFactory,用户也可以定制自己的ChannelFactory。
pipelineFactory:主要用来对传输数据的处理,由于对数据的处理属于业务相关,用户应自己实现ChannelPipelineFactory,然后往ChannelPipelineFactory添加自定义的Handler

启动Netty的Server端时都会设置两个ExecutorService对象,我们都习惯用boss,worker两个变量来引用这两个对象。在Netty的里面有一个Boss,他开了一家公司(开启一个服务端口)对外提供业务服务,它手下有一群做事情的workers。Boss一直对外宣传自己公司提供的业务,并且接受(accept)有需要的客户(client),当一位客户找到Boss说需要他公司提供的业务,Boss便会为这位客户安排一个worker,这个worker全程为这位客户服务(read/write)。如果公司业务繁忙,一个worker可能会为多个客户进行服务。

Spooling Directory Source
监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到spool目录下的文件不可以再打开编辑;不具备目录递归功能。另外需要一个程序对监测目录定期维护,如:备份文件、删除错误文件等。
主要参数配置
spoolDir:监听目录
deletePolicy:当文件中数据全部读取到channel后,源文件处理(立即删除或者重命名)
batchSize:source缓存大小
deserializer:序列化,默认按行划分event,可自定义序列化规则
Channel

Channel说明
MemoryChannel: 所有的events被保存在内存中。优点是高吞吐。缺点是容量有限并且Agent死掉时会丢失内存中的数据。
FileChannel: 所有的events被保存在文件中。优点是容量较大且死掉时数据可恢复。缺点是速度较慢。
上述两种Channel,优缺点相反,分别有自己适合的场景。然而,对于大部分应用来说,我们希望Channel可以同提供高吞吐和大缓存。美团开发DualChannel:
DualChannel:基于 MemoryChannel和 FileChannel开发。当堆积在Channel中的events数小于阈值时,所有的events被保存在MemoryChannel中,Sink从MemoryChannel中读取数据; 当堆积在Channel中的events数大于阈值时, 所有的events被自动存放在FileChannel中,Sink从FileChannel中读取数据。这样当系统正常运行时,我们可以使用MemoryChannel的高吞吐特性;当系统有异常时,我们可以利用FileChannel的大缓存的特性。
多路复用
一种是用来复制(Replication),另一种是用来分流(Multiplexing)。Replication方式,可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的。Multiplexing方式是根据特定类型分流,每个channel中数据是不同的,适合做类型区分。
Sink

HDFS Sink
把events写入HDFS中,目前支持文本文件和SequenceFile,同时支持数据压缩。文件可以根据运行时间、消息数目和文件大小同时作用来控制文件关闭和新建。
主要参数配置
hdfs.path:路径
hdfs.rollInterval:多长时间新建文件
hdfs.rollSize:多大时新建文件
hdfs.rollCount:有多少条消息时新建文件
hdfs.batchSize:批量写入hdfs的event个数
hdfs.fileType:文件类型,支持SequenceFile、DataStream和CompressedStream
hdfs.threadsPoolSizeflume:操作hdfs的线程数(包括新建,写入等)
Kafka Sink
可以把数据发布到一个Kafka topic,有效得整合Flume与Kafka
主要参数配置
topic:对应Kafka的topic
batchSize:批量写入Kafka的event个数
Other Kafka Producer Properties:其它Kafka参数
内部负载均衡
负载均衡片处理器提供在多个Sink之间负载平衡的能力。实现支持通过round_robin(轮询)或者random(随机)参数来实现负载分发,默认情况下使用round_robin,但可以通过配置覆盖这个默认值。还可以通过集成AbstractSinkSelector类来实现用户自己的选择机制。
故障转移
FailoverSink Processor会通过配置维护了一个优先级列表。保证每一个有效的事件都会被处理。
故障转移的工作原理是将连续失败sink分配到一个池中,在那里被分配一个冷冻期,在这个冷冻期里,这个sink不会做任何事。一旦sink成功发送一个event,sink将被还原到live 池中。
在这配置中,要设置sinkgroups processor为failover,需要为所有的sink分配优先级,所有的优先级数字必须是唯一的,这个得格外注意。此外,failover time的上限可以通过maxpenalty 属性来进行设置。