目录
1、模拟登陆
1.1 何为Cookie
1.2 登陆分析
1.2.1 解析POST请求
1.2.2 模拟登陆流程
1.3 程序实现
1.3.1 浏览器伪装
1.3.2 获取参数_xsrf
1.3.3 显示验证码
1.3.4 用户登录
1.3.5 Cookie处理
1.3.6 登录接口
2、用户信息爬取
2.1 步骤
2.2 程序实现
(1)查看文件总行数
(2)分割文件
(3)分割结果
3、用户信息进一步爬取
4、后记
1、模拟登陆
1.1 何为Cookie
百度“知乎爬虫”,随之出现的关键词便是Cookie,所以在做知乎爬虫之前我们必须先弄懂到底什么是Cookie。
HTTP是无状态的面向连接的协议,为了保持连接状态,引入了Cookie机制,Cookie是http消息头中的一种属性,包括:
- Cookie名字(Name)
- Cookie的值(Value)
- Cookie的过期时间(Expires/Max-Age)
- Cookie作用路径(Path)
- Cookie所在域名(Domain)
- 使用Cookie进行安全连接(Secure)
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
简而言之,Cookie的作用是用来保持我们的登录状态,这样子我们才可以进行信息爬取。所以接下来第一步我们要了解知乎的登录情况并用程序模拟其登录。
1.2 登陆分析
1.2.1 解析POST请求
打开Chrome按f12打开开发者工具,输入https://www.zhihu.com/ 并刷新,请注意Method为POST的HTTP请求。
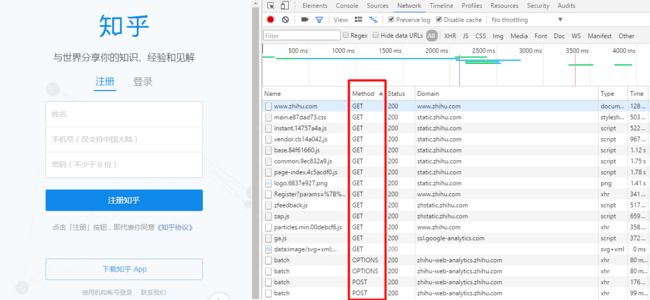
输入账号,密码,找到登陆网址。
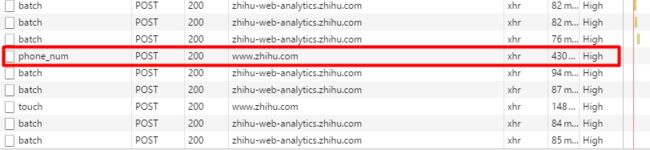
可以看到用手机登录产生phone_num的XHR文件,同理用邮箱则产生email的XHR文件,点击该文件可以看到其POST单如下
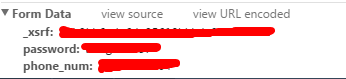
其中_xsrf为Cross Site Request Forgery的缩写(也缩写为CSRF),引用下面解释:
直译过来就是跨站请求伪造的意思,也就是在用户会话下对某个CGI做一些GET/POST的事情——这些事情用户未必知道和愿意做,可以把它想做HTTP会话劫持。
_xsrf是一种知乎的跨域验证方案,举个栗子在A.html页面中存在一个input(hidden),server给这个hideen随机赋值并储存,然后当用户post提交到B.html时验证这个xsrf是否正确。一般用于防止爬虫、恶意提交之类的。那么如何获取_xhrf呢?可以使用HttpWebRequest来模拟,获取html源代码然后找出xhrf。
网站是通过cookie来识别用户的,当用户成功进行身份验证之后浏览器就会得到一个标识其身份的cookie,只要不关闭浏览器或者退出登录,以后访问这个网站会带上这个cookie。如果这期间浏览器被人控制着请求了这个网站的url,可能就会执行一些用户不想做的功能(比如修改个人资料)。因为这个不是用户真正想发出的请求,这就是所谓的请求伪造;因为这些请求也是可以从第三方网站提交的,所以前缀跨站二字。
1.2.2 模拟登陆流程
- 登陆方式
手机登录 API : https://www.zhihu.com/usrLogin/phone_num
邮箱登录 API : https://www.zhihu.com/usrLogin/email - 获取_xsrf值
- 输入账号和密码
- 输入验证码
- 保存Cookie
1.3 程序实现
1.3.1 浏览器伪装
import random
import requests
from bs4 import BeautifulSoup as BS
import time
from PIL import Image # 打开图片
import re
import json
import os
import sys
def getReqHeaders():
'''
功能:随机获取HTTP_User_Agent
'''
user_agents=[
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"]
user_agent = random.choice(user_agents)
req_headers={
'User-Agent':user_agent
}
return req_headers
1.3.2 获取参数_xsrf
def getXsrf(session):
"""
功能:获取参数_xsrf
"""
home_url = "https://www.zhihu.com"
headers = getReqHeaders()
xsrf = BS(session.get(home_url, headers=headers).text, "lxml").find("input", {"name": "_xsrf"})["value"]
return xsrf
该部分主要在于该参数的解析。打开知乎首页之后查看源码可以看到xsrf值。

1.3.3 显示验证码
def showCaptcha(session):
"""
功能:获取验证码本地显示,返回你输入的验证码
"""
captcha_url = "http://www.zhihu.com/captcha.gif?r="+str(int(time.time() * 1000))+"&type=login" #验证码url
r = session.get(captcha_url, headers=getReqHeaders(), verify=True)
with open("code.gif", 'wb') as f:
f.write(r.content)
#显示验证码
try:
print("请查看验证码...")
img = Image.open("code.gif")
img.show()
except:
print("请打开下载的验证码文件code.gif")
该部分主要在于验证码API的地址。
1.3.4 用户登录
def usrLogin():
"""
功能:登录
"""
session = requests.session()
account = input("请输入账户名:")
password = input("请输入密码:")
showCaptcha(session)
captcha = input("请输入验证码:")
xsrf = getXsrf(session)
#确定账户类型
if re.search(r'^1\d{10}$', account):
print("使用手机登录中...")
type="phone_num"
login_url="https://www.zhihu.com/login/phone_num"
elif re.search(r'(.+)@(.+)', account):
print("使用邮箱登录中...")
login_url="https://www.zhihu.com/login/email"
type="email"
else:
print("账户格式错误!")
sys.exit(1)
login_data = { '_xsrf':xsrf
,type:account
,'password':password
,'rememberme':'true'
,'captcha':captcha
}
res = session.post(login_url, data=login_data, headers=getReqHeaders(), verify=True)
content = int((res.json())['r'])
if content==0:
print("登录成功")
saveCookies()
os.remove("code.gif")
session = readCookies()
return session
else:
print("登陆失败!")
print(res.json())
1.3.5 Cookie处理
保存与读取cookies,在检测到本地存在Cookies之后选择是否重新登录,如不则读取该Cookies。
def saveCookies():
with open("./"+"zhiHuCookies",'w')as f:
json.dump(session.cookies.get_dict(),f)
def readCookies():
session = requests.session()
with open("./"+"zhiHuCookies") as f:
cookies = json.load(f)
session.cookies.update(cookies)
return session
def reUsrLogin():
"""
功能:若存在cookies文件,则可先清除后重新登录也可直接读取该cookies文件
"""
print("如想清除cookies文件,请输入1,否则请输入0:")
check_value = input()
if check_value=='1':
os.remove('zhiHuCookies')
print("重新登录...")
session = usrLogin()
else:
session = readCookies()
return session
1.3.6 登录接口
def login():
"""
主函数
"""
if os.path.exists('zhiHuCookies'):
session = reUsrLogin()
else:
session = usrLogin()
return session
2、用户信息爬取
2.1 步骤
- 通过
session = login()获取session,利用该session进行请求; - 构建知乎个人首页网址:https://www.zhihu.com/people/+userID ,即每个用户都有自己的ID,只需要获取ID之后用户ID之后便可爬取用户信息;
- 解析个人数据,可以看到个人首页源码中存在一个div的数据标签,这样子我们只需发送请求之后便可将其解析成json文件。
2.2 程序实现
import html
session = login()#获取登录session
home_url = "https://www.zhihu.com"
usr_id = '/people/kinson-17'
def getUsrInfo(usr_id,curr_ip):
"""
获取用户信息
"""
#### (1)获取数据
usr_url = home_url+usr_id
content = session.get(usr_url, headers=getReqHeaders()).text
soup = BS(content, 'html.parser')
data = soup.find('div', attrs={'id': 'data'})
if data is None:
data = None
else:
data = data['data-state']
data = html.unescape(data) # 对转义 html 字符进行处理
data = BS(data, 'html.parser').text # 去除夹杂的 html 标签
#### (2)数据解析
try:
# 防止解析到的 JSON 格式错误而引发异常
json_data = json.loads(data)
except ValueError:
print('[error]解析到错误的 json 数据')
entities = json_data['entities']
# 提取各个用户信息
users = entities['users']
user_token = (list(users.keys()))[0]
user = users[user_token]
# 提取目标用户的个人信息
usr_avatarUrlTemplate = None # 用户头像
usr_urlToken = None # 用户标识
usr_name = None # 用户名
usr_headline = None # 用户自我介绍
usr_locations = [] # 用户居住地
usr_business = None # 用户所在行业
usr_employments = [] # 用户职业经历
usr_educations = [] # 用户教育经历
usr_description = None # 用户个人描述
usr_sinaWeiboUrl = None # 用户新浪微博 URL
usr_gender = None # 用户性别
usr_followingCount = None # 正在关注用户的数目
usr_followerCount = None # 关注者的数目
usr_answerCount = None # 该用户回答问题的数目
usr_questionCount = None # 用户提问数目
usr_voteupCount = None # 用户获得赞同的数目
if 'avatarUrlTemplate' in user:
usr_avatarUrlTemplate = user['avatarUrlTemplate']
if 'urlToken' in user:
usr_urlToken = user['urlToken']
if 'name' in user:
usr_name = user['name']
if 'headline' in user:
usr_headline = user['headline']
if 'locations' in user:
for location in user['locations']:
usr_locations.append(location['name'])
if 'business' in user:
usr_business = user['business']['name']
if 'employments' in user:
for employment in user['employments']:
elem = {}
if 'job' in employment:
job = employment['job']['name']
elem.update({'job': job})
if 'company' in employment:
company = employment['company']['name']
elem.update({'company': company})
usr_employments.append(elem)
if 'educations' in user:
for education in user['educations']:
if 'school' in education:
school = education['school']['name']
usr_educations.append(school)
if 'description' in user:
usr_description = user['description']
if 'sinaWeiboUrl' in user:
usr_sinaWeiboUrl = user['sinaWeiboUrl']
if 'gender' in user:
usr_gender = user['gender']
if 'followingCount' in user:
usr_followingCount = user['followingCount']
if 'followerCount' in user:
usr_followerCount = user['followerCount']
if 'answerCount' in user:
usr_answerCount = user['answerCount']
if 'questionCount' in user:
usr_questionCount = user['questionCount']
if 'voteupCount' in user:
usr_voteupCount = user['voteupCount']
# 构造用户信息实体
user_info = {'avatarUrlTemplate': usr_avatarUrlTemplate,
'urlToken': usr_urlToken,
'name': usr_name,
'headline': usr_headline,
'locations': usr_locations,
'business': usr_business,
'employments': usr_employments,
'educations': usr_educations,
'description': usr_description,
'sinaWeiboUrl': usr_sinaWeiboUrl,
'gender': usr_gender,
'followingCount': usr_followingCount,
'followerCount': usr_followerCount,
'answerCount': usr_answerCount,
'questionCount': usr_questionCount,
'voteupCount': usr_voteupCount}
return user_info

3、用户信息进一步爬取
为了能够进一步爬取用户信息,我们可以通过爬取自己信息==》关注人信息==》关注人的关注人...这样子不断爬取下去,在此我们将实现个人关注人的信息。
import math
def getFollowingList(usr_info):
"""
返回用户所关注的用户ID
"""
usr_id = '/people/'+usr_info['urlToken']
home_url = "https://www.zhihu.com"
page_num = "?page="
following = "/following"
following_count = usr_info['followingCount']
if following_count<=20:
max_num = 1
else:
max_num = math.ceil(following_count/20)
usr_id_list = []
for num in range(1,max_num+1):
following_url = home_url+usr_id+following+page_num+str(num)
res = session.get(following_url, headers=getReqHeaders())
content = res.text
soup = BS(content, 'html.parser')
usr_ids = soup.find_all('h2', {'class': 'ContentItem-title'})
for usr_id in usr_ids:
usr_id_list.append((usr_id.div.span.div.div.a["href"]))
return usr_id_list
4、后记
本文章只实现模拟登陆、用户信息爬取与解析、用户的关注者ID(以便进一步爬取)的数据爬取功能,可以完善的地方颇多,后续争取时间继续完善。
个人Github
个人博客DebugNLP
欢迎各路同学互相交流