姓名:张安琪 学号:17021211235
转载自:https://www.leiphone.com/news/201804/hZ1uSgcFri2Hwja6.html,有删节。
【嵌牛导读】:内存是大脑和计算机的主要部件。在很多深度学习领域,我们通过和记忆匹配来扩展深度网络的能力,例如,提问与回答,我们先记忆或存储事先处理的信息,然后使用这些信息回答问题。
【嵌牛鼻子】:神经网络 深度学习 内存
【嵌牛提问】:深度学习中与内存进行交互的基本方法是什么
【嵌牛正文】:
内存是大脑和计算机的主要部件。在很多深度学习领域,我们通过和记忆匹配来扩展深度网络的能力,例如,提问与回答,我们先记忆或存储事先处理的信息,然后使用这些信息回答问题。
我们通过将神经网络连接到外部存储资源来扩展神经网络的功能,通过记忆过程与这些资源进行交互。
在外行看来,我们创建了一个记忆结构,通常是数组,我们向记忆结构中写入或从其中读取数据。听起来很简单:但事实并非如此。首先,我们没有无限的存储空间用来保存我们遇到的图片或声音,我们是通过相似性或相关性来访问信息(并不完全匹配)。在这篇文章中,讨论了如何使用NTM来处理信息。我们之所对这篇论文感兴趣,主要是因为在包括NLP和元学习等很多研究领域,她都是一个重要的起点。
记忆结构
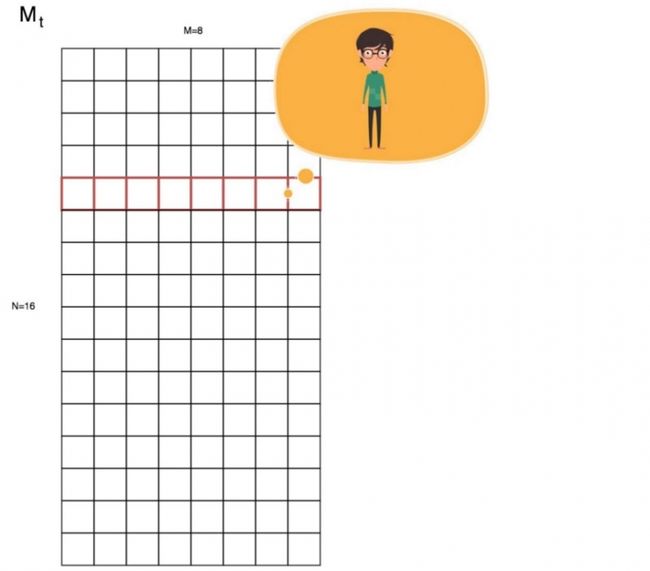
我们的记忆结构Mt包含N行,M个元素。每行代表一条信息(记忆),例如,你对表兄的描述。

读取
通常编程中,我们使用Mt[i]访问记忆。但对于人工智能来说,我么通过相似性获取信息。所以我们推出了一个使用权重的阅读机制,也就是说,我们得到的结果是内存的加权和。
所有权值总和等于1。
你可能立即会问这样做的目的是什么。让我们通过一个例子来解释。一个朋友递给你一杯饮料,它尝起来有点像茶,并感觉像牛奶,通过提取茶和牛奶的记忆资料,应用线性代数方法得出结论:它是珍珠奶茶。听起来很神奇,但在单词潜入中,我们也使用了相同的线性代数来处理关系。在其他的例子比如提问和回答中,基于累计的知识来合并信息是非常重要的。一个记忆网络会让我们很好的达成目标。
我们如何创建这些权值呢? 当然,需要依靠深度学习。控制器从输入信息中提取特征(kt),我们利用它计算权值。例如,你打电话时,不能立即分辨出对方的声音,这个声音很像你的表弟,但有似乎又像你的哥哥。通过线性代数,我们可能分辨出他是你的高中同学,即便那个声音完全不像你记忆中的样子。

通过计算权值w,对比kt和我们每条记忆的相似性,我们用余弦相似性计算出了一个分数K。
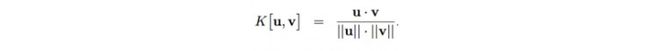
这里, u是我们提取的特征量kt,v代表我们内存中的每一行。
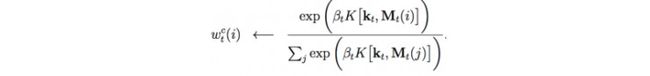
我们将softmax函数应用于分数K,来计算权值w。 βt 被添加进来用于放大或缩小分数的差异。 例如,如果它大于1,就放大差异。w基于相似性检索信息,我们称之为内容寻址。
写入
我们如何将信息写入记忆。在 LSTM中,一个记忆单元的内部状态由之前的状态和当前输入值共同决定。借用相同的情形,记忆的写入过程也是由之前的状态和新的输入组成。这里我们先清除部分之前的状态:
et是一个清除向量。 (计算过程就像LSTM中的输入门一样)
然后,我们写入新的信息。
at是我们想添加的值。
这里,通过产生w的控制器,我们可以向记忆中写入或读取信息。
来源https://arxiv.org/pdf/1410.5401.pdf

寻址机制
我们的控制器通过计算w来提取信息,但是采用相似性(内容寻址)来提取信息还不够强大。
补充
w表示我们记忆中当前的焦点(注意力)。在内容寻址中,我们的关注点只基于是新的输入。然而,这不足以解释我们最近遇到的问题。例如,你的同班同学在一小时之前发信息给你,你应该可以很容易 回想起他的声音。在获取新的信息时我们如何利用之前的注意力?我们根据当前的焦点和之前的焦点 计算出合并权值。是的,这挺起来有点像LSTM或GRU中的遗忘门。
根据之前的焦点和当前输入计算出g。
卷积变换
卷积变换完成焦点的变换。它并不是特地为深度学习设计的。相反,她揭示了NTM如何执行像复制与排序这样的基础算法。例如,不用通过访问w[4],我们想把每个焦点移动3行,也就是 w[i] ← w[i+3]。
在卷积变换中,我们可以将需要的焦点移动到指定的行,即w[i] ←卷积(w[i+3], w[i+4], w[i+5] ) 。通常,卷积仅仅是行的线性加权和: 0.3 × w[i+3] + 0.5 × w[i+4] + 0.2 × w[i+5]。
这是焦点变换的数学公式:

在很多深度学习模型中,我么忽略这一步或者设置s(i)为 0,s(0) = 1例外。
锐化
我们的卷积移位就像一个卷积模糊滤波器。所以在有需要时,我们会对权值采用用锐化技术,达到模糊的效果,γ将会是在锐化焦点时控制器输出的另一个参数。
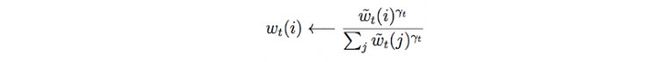
小结
我们使用权值w从记忆中检索信息。w包括这些因素:当前输入,以前的交点,可能的变换与模糊。这里是系统框图,其中控制器输出必要的参数,这些参数用于在不同的阶段计算w。
