本文到这里就结束了,喜欢的朋友可以帮忙转发和关注一下,感谢支持!
为了感谢支持我的朋友!整理了一份Java高级架构资料、Spring源码分析、Dubbo、Redis、Netty、zookeeper、Spring cloud、分布式等资。
本号专注Java源码分析。喜欢底层源码的朋友可以来交流探讨。交流群:818491202 验证:33
的需求,它用于唯一标识一个业务对象、一个资源、或者一个消息等等。在数据库中,唯一ID一般是用来做为一个数据的主键。看过前面介绍MySQL索引原理的文章的朋友应该知道,主键对于数据库的重要性不言而喻。
在单机场景下,要得到一个全局唯一的ID是非常容易的,你可以使用数据库的自增功能。
但是如果在分布式的场景下,想要构建构建一个全局唯一的ID就有些不一样。因为分布式系统一般是高并发场景,那自然不适合使用单机数据库的自增功能了。如果你的技术选型恰好是MySQL这样的“非分布式数据库”,那就得参考一下业界常见的分布式全局唯一ID生成策略了。
UUID
UUID全称是Universally Unique Identifier,翻译过来叫通用唯一识别码。标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:9628f6e9-70ca-45aa-9f7c-77afe0d26e05,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范《A Universally Unique IDentifier (UUID) URN Namespace》,分别称为UUID的5个版本。
在JDK自带的UUID类可以产生版本3和版本4的UUID。所以这里简单介绍一下版本3和版本4的UUID的生成方式。
UUID版本3:通过计算name和namespace的MD5散列值得到。
UUID版本4:根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。

也有在线生成UUID的网站,如果你的项目上用到了UUID,可以用来生成临时的测试数据。
www.uuidgenerator.net/
UUID的优势是实现起来很简单,用JDK原生的API即可得到。劣势是与基于b-Tree引擎的数据库的主键索引策略不太符合,不适合作为高性能需求的场景下的数据库主键。
基于Redis实现
都用分布式了,多半要上个缓存。用缓存的话,可能会使用Redis。Redis的INCR函数在单机上是原子操作,可以保证唯一且递增。
单机Redis可能无法支撑高并发。而如果使用Redis集群,如何保证ID的唯一性呢?可以使用步长的方式。比如有5个Redis节点组成的集群,它们生成的ID分别为:
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25
类snowflake方案
Twitter利用Zookeeper实现了一个全局ID生成的服务snowflake。其生成ID的数据结构如下图所示:
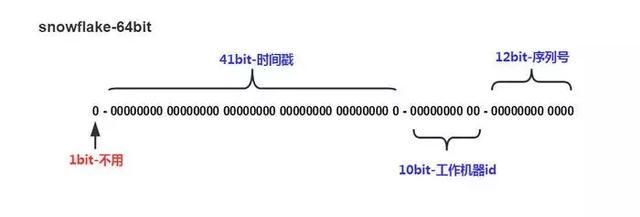
共64位,正好对应Java中的long型,第一个符号位不用,然后41位用于表示时间戳。后续10位用来表示节点的id,如果是多机房节点,可以划分前5位用来表示机房id,后5位用来表示每个机房下的机器的id。最后12位用来表示序列号,这样可以做到同一毫秒,同一机器生成多个id,12位算下来最多支持4096个。
这里的时间戳并不是当前时间的Time Stamp,而是当前时间相对于起始时间的差值。如果基于毫秒来计算的话,41位大约可以用69年。
snowflake算法有许多变种。可以根据自己的实际情况调整位数的分配,比如时间戳占42位,机器id占9位。42位时间戳就可以用138年等。
百度的UidGenerator和美团的Leaf都是基于snowflake的变种。
snowflake是一种比较好的生成ID方式,保证全局唯一,且支持高并发。而且是long类型的,趋势递增,可以用于数据库主键。还可以根据时间来排序。
但也有其缺点,就是强依赖服务器的时钟,如果服务器的时钟出现回拨(比如闰秒或者NTP同步),就会导致ID重复。
美团的Leaf解决了时钟回拨的问题,具体流程如下图,可以了解一下:

其他方式
当然,还有一些其他的ID生成方案,比如:
滴滴:时间+起点编号+车牌号
淘宝订单:时间戳+用户ID
其他电商:时间戳+下单渠道+用户ID,有的会加上订单第一个商品的ID。
MongoDB的ID:也算是类snowflake的一种。通过“时间+机器码+pid+inc”共12个字节,4+3+2+3的方式最终标识成一个24长度的十六进制字符。
总结
如果不用于数据库主键,建议直接用UUID。
如果想要用来做数据库主键,又没有使用分布式数据库(比如TiDB、MongoDB等),可以考虑使用snowflake算法,建议使用美团的Leaf。
数据库中间件sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID),sharding-jdbc没有给出解决方案,如果用户想要强化,需要自行扩展。
关注公众号领资料
搜索公众号【Java耕耘者】,回复【Java】,即可获取大量优质电子书和一份Java高级架构资料、Spring源码分析、Dubbo、Redis、Netty、zookeeper、Spring cloud、分布式等视频资料