Flink项目是大数据计算领域冉冉升起的一颗新星。大数据计算引擎的发展经历了几个过程,从第1代的MapReduce,到第2代基于有向无环图的Tez,第3代基于内存计算的Spark,再到第4代的Flink。因为Flink可以基于Hadoop进行开发和使用,所以Flink并不会取代Hadoop,而是和Hadoop紧密结合。
Flink主要包括DataStream API、DataSet API、Table API、SQL、Graph API和FlinkML等。现在Flink也有自己的生态圈,涉及离线数据处理、实时数据处理、SQL操作、图计算和机器学习库等。
发展到第4代的Flink你学习了吗?

推荐一本可以引领你入门Flink的书,《Flink入门与实战》,学习本书需要大家具备一些大数据的基础知识,比如Hadoop、Kafka、Redis、Elasticsearch等框架的基本安装和使用。本书也适合对大数据实时计算感兴趣的读者阅读。可以借鉴我之前的那篇贴子:大数据书单。
目录结构
版权
内容提要
前言
资源与支持
第1章 Flink概述
第2章 Flink快速入门
第3章 Flink的安装和部署
第4章 Flink常用API详解
第5章 Flink高级功能的使用
第6章 Flink State管理与恢复
第7章 Flink窗口详解
第8章 Flink Time详解
第9章 Flink并行度详解
第10章 Flink Kafka Connector详解
第11章 Flink实战项目开发
主要内容:
本书共分11章,每章的主要内容如下。
第1~2章主要针对Flink的原理组件进行分析,其中包括针对Storm、Spark Streaming和Flink这3个实时计算框架进行对比和分析,以及快速实现Flink的入门案例开发。
第3章主要介绍Flink的安装部署,包含Flink的几种部署模式:本地模式、Standalone模式和YARN模式。本章主要针对YARN模式进行了详细分析,因为在实际工作中以YARN模式为主,这样可以充分利用现有集群资源。
第4章主要针对DataStream和DataSet中的相关组件及API进行详细分析,并对Table API和SQL操作进行了基本的分析。
第5~9章主要针对Flink的一些高级特性进行了详细的分析,包含Broadcast、Accumulator、Distributed Cache、State、CheckPoint、StateBackend、SavePoint、Window、Time、Watermark以及Flink中的并行度。
第10章主要介绍常用组件Kafka-Connector,针对Kafka Consumer和Kafka Producer的使用结合具体案例进行分析,并描述了Kafka的容错机制的应用。
第11章介绍Flink在实际工作中的两个应用场景:一个是实时数据清洗(实时ETL),另一个是实时数据报表,通过这两个项目实战可以加深对Flink的理解。
样章赏析:
Flink概述
本章讲解Flink的基本原理,主要包含Flink原理及架构分析、Flink组件介绍、Flink中的流处理和批处理的对比、Flink的一些典型应用场景分析,以及Flink和其他流式计算框架的区别等。
1.1 Flink原理分析
很多人是在2015年才听到Flink这个词的,其实早在2008年,Flink的前身就已经是柏林理工大学的一个研究性项目,在2014年这个项目被Apache孵化器所接受后,Flink迅速成为ASF(Apache Software Foundation)的顶级项目之一。截至目前,Flink的版本经过了多次更新,本书基于1.6版本写作。
Flink是一个开源的流处理框架,它具有以下特点。
分布式:Flink程序可以运行在多台机器上。
高性能:处理性能比较高。
高可用:由于Flink程序本身是稳定的,因此它支持高可用性(High Availability,HA)。
准确:Flink可以保证数据处理的准确性。
Flink主要由Java代码实现,它同时支持实时流处理和批处理。对于Flink而言,作为一个流处理框架,批数据只是流数据的一个极限特例而已。此外,Flink还支持迭代计算、内存管理和程序优化,这是它的原生特性。
由图1.1可知,Flink的功能特性如下。
流式优先:Flink可以连续处理流式数据。
容错:Flink提供有状态的计算,可以记录数据的处理状态,当数据处理失败的时候,能够无缝地从失败中恢复,并保持Exactly-once。
可伸缩:Flink中的一个集群支持上千个节点。
性能:Flink支持高吞吐、低延迟。

图1.1 Flink的功能特性
在这里解释一下,高吞吐表示单位时间内可以处理的数据量很大,低延迟表示数据产生以后可以在很短的时间内对其进行处理,也就是Flink可以支持快速地处理海量数据。
1.2 Flink架构分析
Flink架构可以分为4层,包括Deploy层、Core层、API层和Library层,如图1.2所示。
Deploy层:该层主要涉及Flink的部署模式,Flink支持多种部署模式——本地、集群(Standalone/YARN)和云服务器(GCE/EC2)。
Core层:该层提供了支持Flink计算的全部核心实现,为API层提供基础服务。
API层:该层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中流处理对应DataStream API,批处理对应DataSet API。
Library层:该层也被称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。
从图1.2可知, Flink对底层的一些操作进行了封装,为用户提供了DataStream API和DataSet API。使用这些API可以很方便地完成一些流数据处理任务和批数据处理 任务。
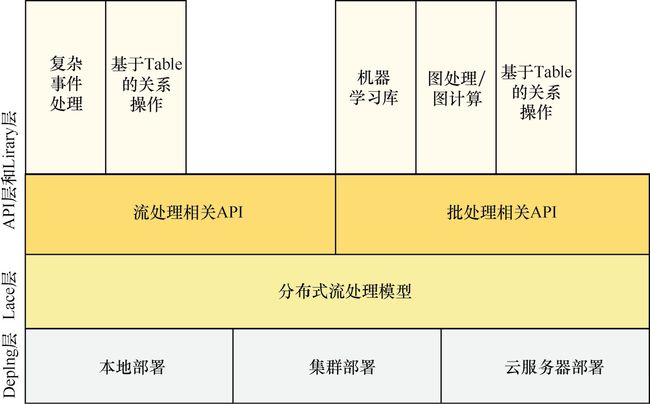
图1.2 Flink架构
1.3 Flink基本组件
读者应该对Hadoop和Storm程序有所了解,在Hadoop中实现一个MapReduce需要两个阶段——Map和Reduce,而在Storm中实现一个Topology则需要Spout和Bolt组件。因此,如果我们想实现一个Flink任务的话,也需要有类似的逻辑。
Flink中提供了3个组件,包括DataSource、Transformation和DataSink。
DataSource:表示数据源组件,主要用来接收数据,目前官网提供了readTextFile、socketTextStream、fromCollection以及一些第三方的Source。
Transformation:表示算子,主要用来对数据进行处理,比如Map、FlatMap、Filter、Reduce、Aggregation等。
DataSink:表示输出组件,主要用来把计算的结果输出到其他存储介质中,比如writeAsText以及Kafka、Redis、Elasticsearch等第三方Sink组件。
因此,想要组装一个Flink Job,至少需要这3个组件。
Flink Job=DataSource+Transformation+DataSink
1.4 Flink流处理(Streaming)与批处理(Batch)
在大数据处理领域,批处理与流处理一般被认为是两种截然不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务。比如,Storm只支持流处理任务,而MapReduce、Spark只支持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,这看似是一个特例,其实不然——Spark Streaming采用了一种Micro-Batch架构,即把输入的数据流切分成细粒度的Batch,并为每一个Batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Storm等完全流式的数据处理方式完全不同。
通过灵活的执行引擎,Flink能够同时支持批处理任务与流处理任务。在执行引擎层级,流处理系统与批处理系统最大的不同在于节点间的数据传输方式。
如图1.3所示,对于一个流处理系统,其节点间数据传输的标准模型是,在处理完成一条数据后,将其序列化到缓存中,并立刻通过网络传输到下一个节点,由下一个节点继续处理。而对于一个批处理系统,其节点间数据传输的标准模型是,在处理完成一条数据后,将其序列化到缓存中,当缓存写满时,就持久化到本地硬盘上;在所有数据都被处理完成后,才开始将其通过网络传输到下一个节点。
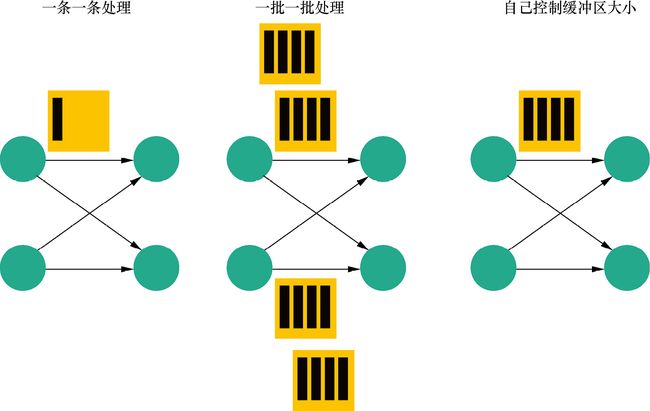
图1.3 Flink的3种数据传输模型
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟和批处理系统对高吞吐的要求。Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。
Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似于前面所提到的流处理系统的标准模型,此时系统可以获得最低的处理延迟;如果缓存块的超时值为无限大,则Flink的数据传输方式类似于前面所提到的批处理系统的标准模型,此时系统可以获得最高的吞吐量。
缓存块的超时值也可以设置为0到无限大之间的任意值,缓存块的超时阈值越小,Flink流处理执行引擎的数据处理延迟就越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
1.5 Flink典型应用场景分析
Flink主要应用于流式数据分析场景,目前涉及如下领域。
实时ETL:集成流计算现有的诸多数据通道和SQL灵活的加工能力,对流式数据进行实时清洗、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。
实时报表:实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。
监控预警:对系统和用户行为进行实时检测和分析,以便及时发现危险行为。
在线系统:实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、无线智能推送领域有大量的应用。
Flink在如下类型的公司中有具体的应用。
优化电商网站的实时搜索结果:阿里巴巴的基础设施团队使用Flink实时更新产品细节和库存信息(Blink)。
针对数据分析团队提供实时流处理服务:通过Flink数据分析平台提供实时数据分析服务,及时发现问题。
网络/传感器检测和错误检测:Bouygues电信公司是法国著名的电信供应商,使用Flink监控其有线和无线网络,实现快速故障响应。
商业智能分析ETL:Zalando使用Flink转换数据以便于将其加载到数据仓库,简化复杂的转换操作,并确保分析终端用户可以更快地访问数据(实时ETL)。
1.6 流式计算框架对比
Storm是比较早的流式计算框架,后来又出现了Spark Streaming和Trident,现在又出现了Flink这种优秀的实时计算框架,那么这几种计算框架到底有什么区别呢?下面我们来详细分析一下,如表1.1所示。
表1.1 流式计算框架对比(略)
在这里对这几种框架进行对比。
模型:Storm和Flink是真正的一条一条处理数据;而Trident(Storm的封装框架)和Spark Streaming其实都是小批处理,一次处理一批数据(小批量)。
API:Storm和Trident都使用基础API进行开发,比如实现一个简单的sum求和操作;而Spark Streaming和Flink中都提供封装后的高阶函数,可以直接拿来使用,这样就比较方便了。
保证次数:在数据处理方面,Storm可以实现至少处理一次,但不能保证仅处理一次,这样就会导致数据重复处理问题,所以针对计数类的需求,可能会产生一些误差;Trident通过事务可以保证对数据实现仅一次的处理,Spark Streaming和Flink也是如此。
容错机制:Storm和Trident可以通过ACK机制实现数据的容错机制,而Spark Streaming和Flink可以通过CheckPoint机制实现容错机制。
状态管理:Storm中没有实现状态管理,Spark Streaming实现了基于DStream的状态管理,而Trident和Flink实现了基于操作的状态管理。
延时:表示数据处理的延时情况,因此Storm和Flink接收到一条数据就处理一条数据,其数据处理的延时性是很低的;而Trident和Spark Streaming都是小型批处理,它们数据处理的延时性相对会偏高。
吞吐量:Storm的吞吐量其实也不低,只是相对于其他几个框架而言较低;Trident属于中等;而Spark Streaming和Flink的吞吐量是比较高的。
官网中Flink和Storm的吞吐量对比如图1.4所示。
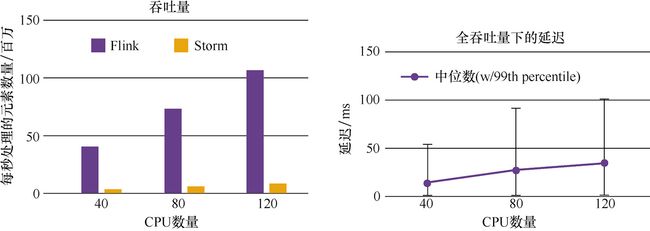
图1.4 Flink和Storm的吞吐量对比
1.7 工作中如何选择实时计算框架
前面我们分析了3种实时计算框架,那么公司在实际操作时到底选择哪种技术框架呢?下面我们来分析一下。
需要关注流数据是否需要进行状态管理,如果是,那么只能在Trident、Spark Streaming和Flink中选择一个。
需要考虑项目对At-least-once(至少一次)或者Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择Storm。
对于小型独立的项目,并且需要低延迟的场景,建议使用Storm,这样比较简单。
如果你的项目已经使用了Spark,并且秒级别的实时处理可以满足需求的话,建议使用Spark Streaming
要求消息投递语义为Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用Flink。