本篇文章是对Exactly once is NOT exactly the same翻译和分析,对流式计算中衡量准确性的三类语义进行了初步的理解。
1、Stream Processing Engines
Distributed event stream processing has become an increasingly hot topic in the area of Big Data. Notable Stream Processing Engines (SPEs) include Apache Storm, Apache Flink, Heron, Apache Kafka (Kafka Streams), and Apache Spark (Spark Streaming). One of the most notable and widely discussed features of SPEs is their processing semantics, with “exactly-once” being one of the most sought after and many SPEs claiming to provide “exactly-once” processing semantics.
There exists a lot of misunderstanding and ambiguity, however, surrounding what exactly “exactly-once” is, what it entails, and what it really means when individual SPEs claim to provide it. The label “exactly-once” for describing processing semantics is also very misleading. In this blog post, I’ll discuss how “exactly-once” processing semantics differ across many popular SPEs andwhy “exactly-once” can be better described as **effectively-once**. I’ll also explore the tradeoffs(权衡) between common techniques used to achieve what is often called “exactly-once.”
注意:精确一次更准确的说法应该是有效一次。
2、Background
Stream processing, sometimes referred to as event processing, can be succinctly described as continuous processing of an unbounded series of data or events.(流处理,有时也称为事件处理,可以简单地描述为对一系列无界数据或事件的连续处理) A stream- or event-processing application can be more or less described as a directed graph and often, but not always, as a directed acyclic graph (DAG).(流或事件处理应用程序可以或多或少地描述为有向图,也可以经常(但不总是)描述为有向无环图(DAG)) In such a graph, each edge represents a flow of data or events and each vertex represents an operator that uses application-defined logic to process data or events from adjacent(邻近的) edges.(每个边表示一个数据流或事件流,每个顶点表示一个操作符,该操作符使用应用程序定义的逻辑来处理来自相邻边的数据或事件) There are two special types of vertices, commonly referenced as sources and sinks. Sources consume external data/events and inject them into the application while sinks typically gather results produced by the application.(有两种特殊类型的顶点,通常称为 sources 和 sinks。sources读取外部数据/事件到应用程序中,而 sinks 通常会收集应用程序生成的结果) Figure 1 below depicts an example a streaming application.
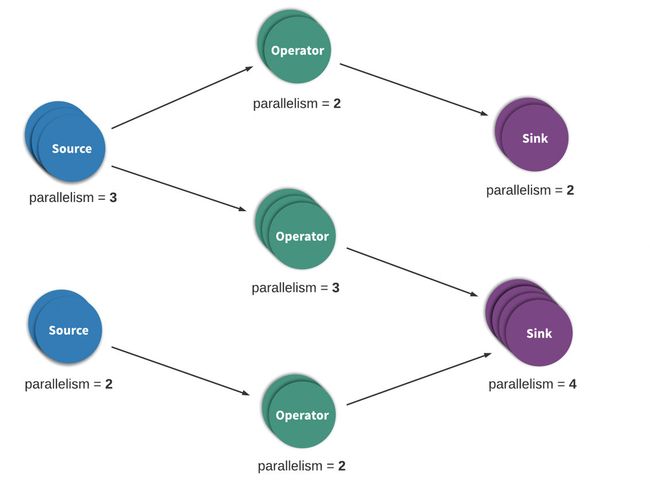
Figure 1. A typical Heron processing topology
An SPE that executes a stream/event processing application usually allows users to specify a reliability mode or processing semantics that indicates which guarantees it will provide for data processing across the entirety of the application graph.(执行流/事件处理应用程序的SPE通常允许用户指定一种可靠性模式或处理语义,该可靠性模式或处理语义指示哪些保证它将为整个应用程序图提供数据处理) These guarantees are meaningful since you can always assume the possibility of failures via network, machines, etc. that can result in data loss.(这些保证是有意义的,因为您总是可以假设通过网络、机器等可能导致数据丢失的故障的可能性) Three modes/labels, at-most-once, at-least-once, and exactly-once, are generally used to describe the data processing semantics that the SPE should provide to the application.
Here’s a loose definition of those different processing semantics(通常使用三种模式/标签(最多一次,至少一次和完全一次)来描述SPE应该提供给应用程序的数据处理语义)
3、At-most-once(最多一次)
This is essentially a “best effort” approach(这本质上是一种“尽力而为”的方法). Data or events are guaranteed to be processed at most once by all operators in the application.(应用程序中的所有操作符保证最多一次处理数据或event) This means that no additional attempts will be made to retry or retransmit events if it was lost before the streaming application can fully process it(这意味着,如果流应用程序在完全处理事件之前丢失了事件,则不会再尝试重试或重新传输事件). Figure 2 illustrates an example of this.

Figure 2. At-most-once processing semantics
4、At-least-once(至少一次)
Data or events are guaranteed to be processed at least once by all operators in the application graph(这意味着,如果流应用程序在完全处理事件之前丢失了事件,则不会再尝试重试或重新传输事件). This usually means an event will be replayed or retransmitted from the source if the event is lost before the streaming application fully processed it.(这通常意味着如果事件在流应用程序完全处理它之前丢失,则将从源重播或重新传输该事件) Since it can be retransmitted, however, an event can sometimes be processed more than once, thus the at-least-once term.(然而,由于可以将其重新传输,因此事件有时可以进行多次处理,因此,至少一次) Figure 3 illustrates an example of this. In this case, the first operator initially fails to process an event, then succeeds upon retry, then succeeds upon a second retry that turns out to have been unnecessary.(图3举例说明了这一点。在这种情况下,第一个操作符最初无法处理事件,然后重试成功,然后再重试成功,最后发现没有必要进行第二次重试)
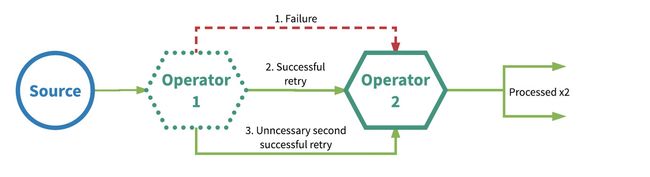
Figure 3. At-least-once processing semantics
5、Exactly-once(精确一次)
Events are guaranteed to be processed “exactly once” by all operators in the stream application, even in the event of various failures.(即使在发生各种故障的情况下,流应用程序中的所有操作符也保证只处理一次事件)
Two popular mechanisms(机制) are typically used to achieve “exactly-once” processing semantics.
Distributed snapshot/state checkpointing(分布式快照或者是状态检查点)At-least-once event delivery plus message deduplication(至少一次事件传递以及消息重复数据删除)
5.1、Distributed snapshot/state checkpointing
The distributed snapshot/state checkpointing method of achieving “exactly-once” is inspired by the Chandy-Lamport distributed snapshot algorithm.1(实现“完全一次”的分布式快照/状态检查点方法是受Chandy-Lamport分布式快照算法启发的。) With this mechanism, all the state for each operator in the streaming application is periodically checkpointed, and in the event of a failure anywhere in the system, all the state of for every operator is rolled back to the most recent globally consistent checkpoint.(流应用程序中每个操作符的所有状态都是定期检查点的,当系统中任何地方出现故障时,每个操作符的所有状态都回滚到最近的全局一致检查点) During the rollback, all processing will be paused.(在回滚期间,所有处理将被暂停) Sources are also reset to the correct offset corresponding to the most recent checkpoint.(source也被重置为与最近的检查点相对应的正确偏移量) The whole streaming application is basically rewound to its most recent consistent state and processing can then restart from that state(整个流处理应用程序基本上被重新恢复到最近的一致状态,然后处理可以从该状态重新启动). Figure 4 below illustrates the basics of this mechanism.
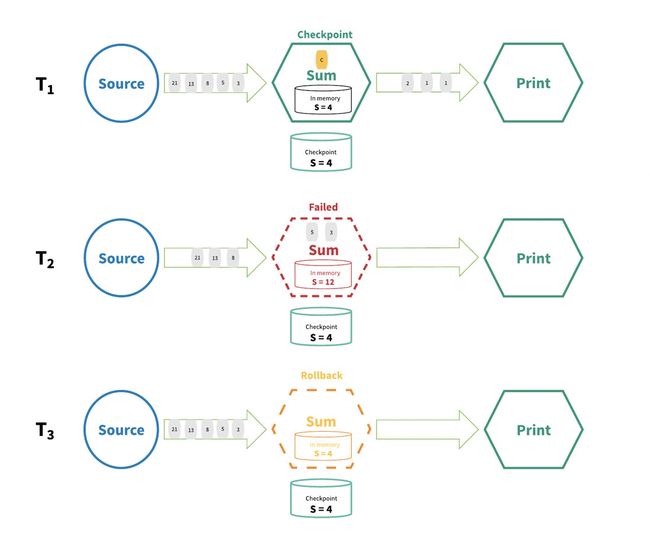
Figure 4. Distributed snapshot
In Figure 4,
the streaming application is working normally at T1 and the state is checkpointed.(流应用程序在T1下正常工作,状态为检查点。)
At time T2, however, the operator fails to process an incoming datum. At this point, the state value of S = 4 has been saved to durable storage, while the state value S = 12 is held in the operator’s memory.(但是在T2时,Operator不能处理输入的数据。此时,状态值S = 4被保存到持久存储中,而状态值S = 12保存在操作符的内存中。)
In order to overcome this discrepancy, at time T3 the processing graph rewinds the state to S = 4 and “replays” each successive state in the stream up to the most recent, processing each datum(基准点). (为了克服这种差异,在时间T3处,处理图将状态后退到S = 4,并将流中的每个连续状态“重播”到最新的,处理每个数据的状态。)
The end result is that some data have been processed multiple times, but that’s okay because the resulting state is the same no matter how many rollbacks have been performed.(最终的结果是,有些数据已经处理了多次,但是这没有关系,因为不管执行了多少回滚,结果状态都是相同的。)
5.2、At-least-once event delivery plus message deduplication
Another method used to achieve “exactly-once” is through implementing at-least-once event delivery in conjunction with event deduplication on a per-operator basis.(另一种实现精确一次的方法是在每个operation的基础上实现至少一次事件交付和事件重复数据删除) SPEs utilizing this approach will replay failed events for further attempts at processing and remove duplicated events for every operator prior to the events entering the user defined logic in the operator.(使用此方法的spe将重播失败事件,以便进一步尝试处理,并在事件进入操作符中用户定义的逻辑之前删除每个操作符的重复事件。) This mechanism requires that a transaction log be maintained for every operator to track which events it has already processed.(该机制要求为每个操作符维护一个事务日志,以跟踪它已经处理的事件) SPEs that utilize a mechanism like such are Google’s MillWheel2 and Apache Kafka Streams. Figure 5 illustrates the gist of this mechanism.
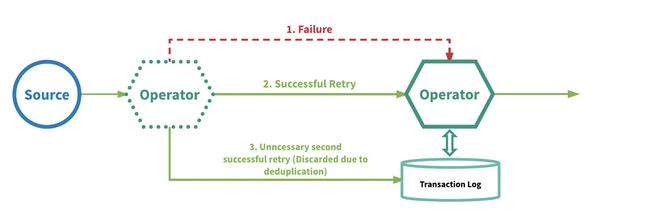
Figure 5. At-least-once delivery plus deduplication
6、Is exactly-once really exactly-once?
Now let’s reexamine what the “exactly-once” processing semantics really guarantees to the end user. The label “exactly-once” is misleading in describing what is done exactly once.(现在让我们重新审视『精确一次』处理语义真正对最终用户的保证。『精确一次』这个术语在描述正好处理一次时会让人产生误导)
Some might think that “exactly-once” describes the guarantee to event processing in which each event in the stream is processed only once.(有些人可能认为『精确一次』描述了事件处理的保证,其中流中的每个事件只被处理一次)
In reality, there is no SPE that can guarantee exactly-once processing. To guarantee that the user-defined logic in each operator only executes once per event is impossible in the face of arbitrary failures, because partial execution of user code is an ever-present possibility.(实际上,没有SPE可以保证精确的一次处理。要保证每个操作符中的用户定义逻辑只针对每个事件执行一次是不可能的,因为随时都可能出现部分执行用户代码的情况。)
So what does SPEs guarantee when they claim “exactly-once” processing semantics? If user logic cannot be guaranteed to be executed exactly once then what is executed exactly once? When SPEs claim “exactly-once” processing semantics, what they’re actually saying is that they can guarantee that updates to state managed by the SPE are committed only once to a durable backend store.(那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储)
Both mechanisms described above use a durable backend store as a source of truth that can hold the state of every operator and automatically commit updates to it. (上面描述的两种机制都使用持久的后端存储作为真实性的来源,可以保存每个算子的状态并自动向其提交更新)
For mechanism 1 (distributed snapshot/state checkpointing), this durable backend state is used to hold the globally consistent state checkpoints (checkpointed state for every operator) for the streaming application.(对于机制 1 (分布式快照 / 状态检查点),此持久后端状态用于保存流应用程序的全局一致状态检查点(每个算子的检查点状态)
For mechanism 2 (at-least-once event delivery plus deduplication), the durable backend state is used to store the state of every operator as well as a transaction log for every operator that tracks all the events it has already fully processed.(对于机制 2 (至少一次事件传递加上重复数据删除),持久后端状态用于存储每个算子的状态以及每个算子的事务日志,该日志跟踪它已经完全处理的所有事件)
The committing of state or applying updates to the durable backend that is the source of truth can be described as occurring exactly-once.(提交状态或对作为真实来源的持久后端应用更新可以被描述为恰好发生一次) Computing the state update/change, i.e. processing the event that is executing arbitrary user -defined logic on the event, however, can happen more than once if failures occur, as mentioned above(如上所述,计算状态更新/更改,即处理在事件上执行任意用户定义的逻辑的事件,如果发生故障,则可能会发生多次(如上所述)). In other words, the processing of an event can happen more than once but the effect of that processing is only reflected once in the durable backend state store.(换句话说,事件的处理可以发生多次,但是处理的效果只在持久后端状态存储中反映一次) Here at Streamlio, we’ve decided that effectively-once is the best term for describing these processing semantics.
7、Distributed snapshot versus at-least-once event delivery plus deduplication
From a semantic point of view, both the distributed snapshot and at-least-once event delivery plus deduplication mechanisms provide that same guarantee. Due to differences in implementation between the two mechanisms, however, there are significant performance differences.(从语义的角度来看,分布式快照和至少一次事件交付加上重复数据删除机制都提供了相同的保证。但是,由于这两种机制的实现方式不同,性能也有很大差异。)
The performance overhead of mechanism 1 (distributed snapshot/state checkpointing) on top of the SPE can be minimal since the SPE is essentially sending a few special events alongside regular events through all the operators in the streaming application, while state checkpointing can be performed asynchronously in the background.(在SPE之上的机制1(分布式快照/状态检查点)的性能开销可以最小化,因为SPE本质上通过流式处理程序中的所有运算符发送一些特殊事件以及常规事件,而状态检查点在后台可以异步执行) For large streaming applications, however, failures may happen more frequently, causing the SPE to need to pause the application and roll back the state of all operators, which will in turn impact performance(然而,对于大型流应用程序,故障可能发生得更频繁,导致SPE需要暂停应用程序并回滚所有操作符的状态,这反过来又会影响性能). The larger the streaming application, the more likely and thus more frequently failures can occur, and in turn, the more significantly the performance of the streaming application will be impacted(流应用程序越大,故障发生的可能性就越大,因此故障发生的频率也就越高,反过来,流应用程序的性能受到的影响也就越大). However, again, this mechanism is very non-intrusive and demands minimal additional resources impact to run.(但是,这种机制是非侵入性的,并且运行时对额外资源的影响很小。)
Mechanism 2 (at-least-once event delivery plus deduplication) may require a lot more resources, especially storage(机制2(至少一次事件交付加上重复数据删除)可能需要更多的资源,特别是存储。). With this mechanism, the SPE would need to be able to track every tuple that has been fully processed by every instance of an operator to perform deduplication as well as perform the deduplication itself for every event.(使用这种机制,SPE将需要能够跟踪操作符的每个实例已经完全处理过的每个元组,以便执行重复数据删除,以及为每个事件执行重复数据删除本身。) This can amount to a huge amount of data to keep track of, especially if the streaming application is large or if there are many applications running. There is also performance overhead associated with every event at every operator to perform the deduplication(每个操作员执行重复数据消除的每个事件都会产生性能开销). With this mechanism, however, the performance of the streaming application is less likely to be impacted by the size of the application.(流式应用不太可能受到应用大小的影响)
-
- 1、With mechanism 1, a global pause and state rollback needs to occur if any failures occur on any operator; (使用机制1,如果任何操作符发生任何故障,则需要执行全局暂停和状态回滚)
-
- 2、with mechanism 2, the effects of a failure are much more localized. When a failure occurs in an operator, events that might have not been fully processed are just replayed/retransmitted from an upstream source.(对于机制2,故障的影响更加局限。当操作员发生故障时,可能只是从上游源重放/重传了可能尚未完全处理的事件) The performance impact is isolated to where the failure happened in the streaming application and will cause little impact to the performance of other operators in the streaming application.(性能影响被隔离到流应用程序中发生故障的地方,对流应用程序中其他操作符的性能影响很小) The pros and cons of both mechanisms from a performance standpoint are listed in the tables below.(从性能的角度来看,这两种机制的优缺点列在下面的表中。)
Distributed snapshot/state checkpointing
| Pros优点 | Cons缺点 |
|---|---|
| Little performance and resource overhead (性能和资源开销很少) | Larger impact to performance when recovering from failures (从故障中恢复对性能的影响更大) |
| Potential impact to performance increases as topology gets larger (随着拓扑变大,对性能的潜在影响会增加) |
At-least-once delivery plus deduplication
| Pros(优点) | Cons(缺点) |
|---|---|
| Performance impact of failures are localized (故障对性能的影响已本地化) | Potentially need large amounts of storage and infrastructure to support (潜在需要大量的存储和基础架构来支持) |
| Impact of failures does not necessarily increase with the size of the topology (故障的影响不一定随拓扑的大小而增加) | Performance overhead for every event at every operator (每个操作员的每个事件的性能开销) |
Though there are differences between the distributed snapshot and at-least-once event delivery plus deduplication mechanisms from a theoretical point of view, both can be reduced to at-least-once processing plus idempotency.(尽管从理论上讲,分布式快照和至少一次事件交付加上重复数据删除机制之间存在差异,但两者都可以简化为至少一次处理加上幂等性) For both mechanisms, events will be replayed/retransmitted when failures occur (implementing at-least-once), and through state rollback or event deduplication, operators essentially become idempotent when updating internally managed state.(对于这两种机制,都将在发生故障时(至少一次实现)重播/重传事件,并且通过状态回滚或事件重复数据删除,操作员在更新内部管理状态时实质上将成为幂等。)
8、Conclusion
In this blog post, I hope to have convinced you that the term “exactly-once” is very misleading. Providing “exactly-once” processing semantics really means that distinct updates to the state of an operator that is managed by the stream processing engine are only reflected once(提供精确的一次处理语义实际上意味着对由流处理引擎管理的操作符状态的不同更新只反映一次). “Exactly-once” by no means guarantees that processing of an event, i.e. execution of arbitrary user-defined logic, will happen only once.(确切地说,一次并不能保证事件的处理,即任意用户定义逻辑的执行只发生一次) Here at Streamlio, we prefer the term effectively once for this guarantee because processing is not necessarily guaranteed to occur once but the effect on the SPE-managed state is reflected once(在Streamlio中,对于这种保证,我们更倾向于使用“有效一次”这个术语,因为处理并不一定保证只发生一次,但是对spe管理状态的影响只反映一次). Two popular mechanisms, distributed snapshot and dessage deduplication, are used to implement exactly/effectively-once processing semantics. (两种流行的机制,即分布式快照和dessage重复数据删除,用于实现精确/有效的一次处理语义)Both mechanisms provide the same semantic guarantees to message processing and state updates but there are nonetheless differences in performance(这两种机制为消息处理和状态更新提供了相同的语义保证,但在性能上仍然存在差异). This post is not meant to convince you that either mechanism is superior to the other, as each has its pros and cons.
References
1. Chandy, K. Mani and Leslie Lamport. Distributed snapshots: Determining global states of distributed systems. ACM Transactions on Computer Systems (TOCS) 3.1 (1985): 63-75.
2. Akidau, Tyler, et al. MillWheel: Fault-tolerant stream processing at internet scale. Proceedings of the VLDB Endowment 6.11 (2013): 1033-1044.