参考
golang 函数以及函数和方法的区别
在接触到go之前,我认为函数和方法只是同一个东西的两个名字而已(在我熟悉的c/c++,python,java中没有明显的区别),但是在golang中者完全是两个不同的东西。官方的解释是,方法是包含了接收者的函数。函数叫function,方法叫method
一、函数
1.定义
函数声明包括函数名、形式参数列表、返回值列表( 可省略) 以及函数体。
func name(parameter-list) (result-list) {
body
}
比如
func hypot(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(3,4)) // "5"
正如hypot一样,如果一组形参或返回值有相同的类型,我们不必为每个形参都写出参数类型。下面2个声明是等价的:
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
每一次函数调用都必须按照声明顺序为所有参数提供实参( 参数值)。在函数调用时,Go语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
2.多返回值举例
func findLinks(url string) ([]string, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
if resp.StatusCode != http.StatusOK {
resp.Body.Close()
return nil, fmt.Errorf(
"getting %s: %s", url, resp.Status)
}
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
return nil, fmt.Errorf(
"parsing %s as HTML: %v", url, err)
}
return visit(nil, doc), nil
}
调用多返回值函数时,返回给调用者的是一组值,调用者必须显式的将这些值分配给变量:links, err := findLinks(url)。 如果某个值不被使用,可以将其分配给blank identifier:links, _ := findLinks(url) // errors ignored
3.匿名函数
// squares返回一个匿名函数。
// 该匿名函数每次被调用时都会返回下一个数的平方。
func squares() func() int {
var x int
return func() int {
x++
return x * x
}
}
func main() {
f := squares()
fmt.Println(f()) // "1"
fmt.Println(f()) // "4"
fmt.Println(f()) // "9"
fmt.Println(f()) // "16"
}
squares的例子证明,函数值不仅仅是一串代码,还记录了状态。在squares中定义的匿名内部函数可以访问和更新squares中的局部变量,这意味着匿名函数和squares中,存在变量引用。这就是函数值属于引用类型和函数值不可比较的原因。Go使用闭包( closures) 技术实现函数值,Go程序员也把函数值叫做闭包。
通过这个例子,我们看到变量的生命周期不由它的作用域决定:squares返回后,变量x仍然隐式的存在于f中。
4.可变参数
在声明可变参数函数时,需要在参数列表的最后一个参数类型之前加上省略符号“...”,这表示该函数会接收任意数量的该类型参数。
func sum(vals...int) int {
total := 0
for _, val := range vals {
total += val
}
return total
}
sum函数返回任意个int型参数的和。在函数体中,vals被看作是类型为[] int的切片。sum可以接收任意数量的int型参数。
fmt.Println(sum()) // "0"
fmt.Println(sum(3)) // "3"
fmt.Println(sum(1, 2, 3, 4)) // "10"
在上面的代码中,调用者隐式的创建一个数组,并将原始参数复制到数组中,再把数组的一个切片作为参数传给被调函数。如果原始参数已经是切片类型,我们该如何传递给sum?只需在最后一个参数后加上省略符。下面的代码功能与上个例子中最后一条语句相同。
values := []int{1, 2, 3, 4}
fmt.Println(sum(values...)) // "10"
二、Go语言参数传递是传值还是传引用
先放结论,再慢慢验证:在Go语言中,所有的变量都以值的方式传递。因为指针变量的值是所指向的内存地址,在函数间传递指针变量,是在传递这个地址值,所以依旧被看作以值的方式在传递。Go的引用类型有:通道,映射,切片,接口,函数类型,字符串(Go in Action P92)
1.传指针时
传值的意思是:函数传递的总是原来这个东西的一个副本,一副拷贝。比如我们传递一个int类型的参数,传递的其实是这个参数的一个副本;传递一个指针类型的参数,其实传递的是这个该指针的一份拷贝,而不是这个指针指向的值。
对于int这类基础类型我们可以很好的理解,它们就是一个拷贝,但是指针呢?我们觉得可以通过它修改原来的值,怎么会是一个拷贝呢?下面我们看个例子。
func main() {
i:=10
ip:=&i
fmt.Printf("原始指针的内存地址是:%p\n",&ip)
modify(ip)
fmt.Println("int值被修改了,新值为:",i)
}
func modify(ip *int){
fmt.Printf("函数里接收到的指针的内存地址是:%p\n",&ip)
*ip=1
}
-----------------------
原始指针的内存地址是:0xc42000c028
函数里接收到的指针的内存地址是:0xc42000c038
int值被修改了,新值为: 1
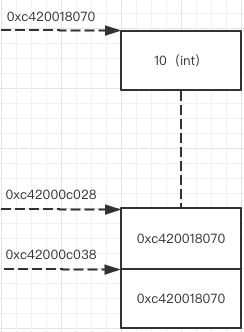
通过上面的图,可以更好的理解。 首先我们看到,我们声明了一个变量i,值为10,它的内存存放地址是0xc420018070,通过这个内存地址,我们可以找到变量i,这个内存地址也就是变量i的指针ip。
指针ip也是一个指针类型的变量,它也需要内存存放它,它的内存地址是多少呢?是0xc42000c028。 在我们传递指针变量ip给modify函数的时候,是该指针变量的拷贝,所以新拷贝的指针变量ip,它的内存地址已经变了,是新的0xc42000c038。
不管是0xc42000c028还是0xc42000c038,我们都可以称之为指针的指针,他们指向同一个指针0xc420018070,这个0xc420018070又指向变量i,这也就是为什么我们可以修改变量i的值。
2.迷惑Map
了解清楚了传值和传引用,但是对于Map类型来说,可能觉得还是迷惑,一来我们可以通过方法修改它的内容,二来它没有明显的指针。
func main() {
persons:=make(map[string]int)
persons["张三"]=19
mp:=&persons
fmt.Printf("原始ma`p的内存地址是:%p\n",mp)
modify(persons)
fmt.Println("map值被修改了,新值为:",persons)
}
func modify(p map[string]int){
fmt.Printf("函数里接收到map的内存地址是:%p\n",&p)
p["张三"]=20
}
运行打印输出:
原始map的内存地址是:0xc42000c028
函数里接收到map的内存地址是:0xc42000c038
map值被修改了,新值为: map[张三:20]
两个内存地址是不一样的,所以这又是一个值传递(值的拷贝),那么为什么我们可以修改Map的内容呢?先不急,我们先看一个自己实现的struct。
func main() {
p:=Person{"张三"}
fmt.Printf("原始Person的内存地址是:%p\n",&p)
modify(p)
fmt.Println(p)
}
type Person struct {
Name string
}
func modify(p Person) {
fmt.Printf("函数里接收到Person的内存地址是:%p\n",&p)
p.Name = "李四"
}
运行打印输出:
原始Person的内存地址是:0xc4200721b0
函数里接收到Person的内存地址是:0xc4200721c0
{张三}
我们发现,我们自己定义的Person类型,在函数传参的时候也是值传递,但是它的值(Name字段)并没有被修改,我们想改成李四,发现最后的结果还是张三。
这也就是说,map类型和我们自己定义的struct类型是不一样的。我们尝试把modify函数的接收参数改为Person的指针。
func main() {
p:=Person{"张三"}
modify(&p)
fmt.Println(p)
}
type Person struct {
Name string
}
func modify(p *Person) {
p.Name = "李四"
}
在运行查看输出,我们发现,这次被修改了。我们这里省略了内存地址的打印,因为我们上面int类型的例子已经证明了指针类型的参数也是值传递的。 指针类型可以修改,非指针类型不行,那么我们可以大胆的猜测,我们使用make函数创建的map是不是一个指针类型呢?看一下源代码:
// makemap implements a Go map creation make(map[k]v, hint)
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If bucket != nil, bucket can be used as the first bucket.
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
//省略无关代码
}
通过查看src/runtime/hashmap.go源代码发现,的确和我们猜测的一样,make函数返回的是一个hmap类型的指针hmap。也就是说map===hmap。 现在看func modify(p map)这样的函数,其实就等于func modify(p *hmap),和我们前面第一节什么是值传递里举的func modify(ip *int)的例子一样,可以参考分析。
所以在这里,Go语言通过make函数,字面量的包装,为我们省去了指针的操作,让我们可以更容易的使用map。这里的map可以理解为引用类型,但是记住引用类型不是传引用。
3.chan类型
chan类型本质上和map类型是一样的,这里不做过多的介绍,参考下源代码:
func makechan(t *chantype, size int64) *hchan {
//省略无关代码
}
chan也是一个引用类型,和map相差无几,make返回的是一个*hchan。
4.slice
slice和map、chan都不太一样的,一样的是,它也是引用类型,它也可以在函数中修改对应的内容。
func main() {
ages:=[]int{6,6,6}
fmt.Printf("原始slice的内存地址是%p\n",ages)
modify(ages)
fmt.Println(ages)
}
func modify(ages []int){
fmt.Printf("函数里接收到slice的内存地址是%p\n",ages)
ages[0]=1
}
运行打印结果,发现的确是被修改了,而且我们这里打印slice的内存地址是可以直接通过%p打印的,不用使用&取地址符转换。
这就可以证明make的slice也是一个指针了吗?不一定,也可能fmt.Printf把slice特殊处理了。
func (p *pp) fmtPointer(value reflect.Value, verb rune) {
var u uintptr
switch value.Kind() {
case reflect.Chan, reflect.Func, reflect.Map, reflect.Ptr, reflect.Slice, reflect.UnsafePointer:
u = value.Pointer()
default:
p.badVerb(verb)
return
}
//省略部分代码
}
通过源代码发现,对于chan、map、slice等被当成指针处理,通过value.Pointer()获取对应的值的指针。
// If v's Kind is Slice, the returned pointer is to the first
// element of the slice. If the slice is nil the returned value
// is 0. If the slice is empty but non-nil the return value is non-zero.
func (v Value) Pointer() uintptr {
// TODO: deprecate
k := v.kind()
switch k {
//省略无关代码
case Slice:
return (*SliceHeader)(v.ptr).Data
}
}
很明显了,当是slice类型的时候,返回是slice这个结构体里,字段Data第一个元素的地址。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
type slice struct {
array unsafe.Pointer
len int
cap int
}
所以我们通过%p打印的slice变量ages的地址其实就是内部存储数组元素的地址,slice是一种结构体+元素指针的混合类型,通过元素array(Data)的指针,可以达到修改slice里存储元素的目的。
所以修改类型的内容的办法有很多种,类型本身作为指针可以,类型里有指针类型的字段也可以。
单纯的从slice这个结构体看,我们可以通过modify修改存储元素的内容,但是永远修改不了len和cap,因为他们只是一个拷贝,如果要修改,那就要传递*slice作为参数才可以。
func main() {
i:=19
p:=Person{name:"张三",age:&i}
fmt.Println(p)
modify(p)
fmt.Println(p)
}
type Person struct {
name string
age *int
}
func (p Person) String() string{
return "姓名为:" + p.name + ",年龄为:"+ strconv.Itoa(*p.age)
}
func modify(p Person){
p.name = "李四"
*p.age = 20
}
运行打印输出结果为:
姓名为:张三,年龄为:19
姓名为:张三,年龄为:20
通过这个Person和slice对比,就更好理解了,Person的name字段就类似于slice的len和cap字段,age字段类似于array字段。在传参为非指针类型的情况下,只能修改age字段,name字段无法修改。要修改name字段,就要把传参改为指针,比如:
modify(&p)
func modify(p *Person){
p.name = "李四"
*p.age = 20
}
这样name和age字段双双都被修改了。
所以slice类型也是引用类型
5.golang新手容易犯的三个错误
在golang中,array和struct都是值类型的,而slice、map、chan是引用类型,所以我们写代码的时候,基本不使用array,而是用slice代替它,对于struct则尽量使用指针,这样避免传递变量时复制数据的时间和空间消耗,也避免了无法修改原数据的情况。
如果对这点认识不清,导致的后果可能是代码有瑕疵,更严重的是产生bug。考虑这段代码并运行一下:
package main
import "fmt"
type person struct {
name string
age byte
isDead bool
}
func main() {
p1 := person{name: "zzy", age: 100}
p2 := person{name: "dj", age: 99}
p3 := person{name: "px", age: 20}
people := []person{p1, p2, p3}
whoIsDead(people)
for _, p := range people {
if p.isDead {
fmt.Println("who is dead?", p.name)
}
}
}
func whoIsDead(people []person) {
for _, p := range people {
if p.age < 50 {
p.isDead = true
}
}
}
我相信很多人一看就看出问题在哪了,但肯定还有人不清楚for range语法的机制,我絮叨一下:golang中for range语法非常方便,可以轻松的遍历array、slice、map等结构,但是它有一个特点,就是会在遍历时把当前遍历到的元素,复制给内部变量,具体就是在whoIsDead函数中的for range里,会把people里的每个person,都复制给p这个变量,类似于这样的操作:p := person
上文说过,struct是值类型,所以在赋值给p的过程中,实际上需要重新生成一份person数据,便于for range内部使用,不信试试:
package main
import "fmt"
type person struct {
name string
age byte
isDead bool
}
func main() {
p1 := person{name: "zzy", age: 100}
p2 := p1
p1.name = "changed"
fmt.Println(p2.name)
}
所以p.isDead = true这个操作实际上更改的是新生成的p数据,而非people中原本的person,这里产生了一个bug。在for range内部只需读取数据而不需要修改的情况下,随便怎么写也无所谓,顶多就是代码不够完美,而需要修改数据时,则最好传递struct指针:
package main
import "fmt"
type person struct {
name string
age byte
isDead bool
}
func main() {
p1 := &person{name: "zzy", age: 100}
p2 := &person{name: "dj", age: 99}
p3 := &person{name: "px", age: 20}
people := []*person{p1, p2, p3}
whoIsDead(people)
for _, p := range people {
if p.isDead {
fmt.Println("who is dead?", p.name)
}
}
}
func whoIsDead(people []*person) {
for _, p := range people {
if p.age < 50 {
p.isDead = true
}
}
}
好,for range部分讲到这里,接下来说一说map结构中值的传递和修改问题。
这段代码将之前的people []person改成了map结构,大家觉得有错误吗,如果有错,错在哪:
package main
import "fmt"
type person struct {
name string
age byte
isDead bool
}
func main() {
p1 := person{name: "zzy", age: 100}
p2 := person{name: "dj", age: 99}
p3 := person{name: "px", age: 20}
people := map[string]person{
p1.name: p1,
p2.name: p2,
p3.name: p3,
}
whoIsDead(people)
if p3.isDead {
fmt.Println("who is dead?", p3.name)
}
}
func whoIsDead(people map[string]person) {
for name, _ := range people {
if people[name].age < 50 {
people[name].isDead = true
}
}
}
go run一下,报错:
cannot assign to struct field people[name].isDead in map
这个报错有点迷,我估计很多人都看不懂了。我解答下,map底层使用了array存储数据,并且没有容量限制,随着map元素的增多,需要创建更大的array来存储数据,那么之前的地址就无效了,因为数据被复制到了新的更大的array中,所以map中元素是不可取址的,也是不可修改的。这个报错的意思其实就是不允许修改map中的元素。
即便map中元素没有以上限制,这段代码依然是错误的,想一想,为什么?答案之前已经说过了。
那么,怎么改才能正确呢,老套路,依然是使用指针:
package main
import "fmt"
type person struct {
name string
age byte
isDead bool
}
func main() {
p1 := &person{name: "zzy", age: 100}
p2 := &person{name: "dj", age: 99}
p3 := &person{name: "px", age: 20}
people := map[string]*person{
p1.name: p1,
p2.name: p2,
p3.name: p3,
}
whoIsDead(people)
if p3.isDead {
fmt.Println("who is dead?", p3.name)
}
}
func whoIsDead(people map[string]*person) {
for name, _ := range people {
if people[name].age < 50 {
people[name].isDead = true
}
}
}
三、方法
1.定义
在函数声明时,在其名字之前放上一个变量,即是一个方法。这个附加的参数会将该函数附加到这种类型上,即相当于为这种类型定义了一个独占的方法。
package geometry
import "math"
type Point struct{ X, Y float64 }
// traditional function
func Distance(p, q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
// same thing, but as a method of the Point type
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
上面的代码里,那个在关键字func和函数名之间附加的参数p,叫做方法的接收器(receiver),早期的面向对象语言留下的遗产将调用一个方法称为“向一个对象发送消息”。在Go语言中,我们并不会像其它语言那样用this或者self作为接收器;我们可以任意的选择接收器的名字。
p := Point{1, 2}
q := Point{4, 6}
fmt.Println(Distance(p, q)) // "5", function call
fmt.Println(p.Distance(q)) // "5", method call
可以看到,上面的两个函数调用都是Distance,但是却没有发生冲突。第一个Distance的调用实际上用的是包级别的函数geometry.Distance,而第二个则是使用刚刚声明的Point,调用的是Point类下声明的Point.Distance方法。
2.接收者有两种类型:值接收者和指针接收者
值接收者,在调用时,会使用这个值的一个副本来执行。
type user struct{
name string
email string
}
func (u user) notify(){
fmt.Printf("Sending user email to %s <%s>\n",
u.name,
u.email
);
}
//
bill := user("Bill","[email protected]");
bill.notify()
//
lisa := &user("Lisa","[email protected]");
lisa.notify()
这里lisa使用了指针变量来调用notify方法,可以认为go语言执行了如下代码
(*lisa).notify()
go编译器为了支持这种方法调用,将指针解引用为值,这样就符合了notify方法的值接收者要求。再强调一次,notify操作的是一个副本,只不过这次操作的是从lisa指针指向的值的副本。
3.指针接收者
func (u *user) changeEmail(email string){
u.email = email
}
lisa := &user{"Lisa","[email protected]"}
lisa.changeEmail("[email protected]");
当调用使用指针接收者声明的方法时,这个方法会共享调用方法时接收者所指向的值。也就是说,值接收者使用值的副本来调用方法,而指针接收者使用实际值来调用方法。
也可以使用一个值来调用使用指针接收者声明的方法
bill := user{"Bill","[email protected]"}
bill.changeEmail("[email protected]");
实际上,go编译器为了支持这种方法,在背后这样做
(&bill).changeEmail("[email protected]");
go语言既允许使用值,也允许使用指针来调用方法,不必严格符合接收者的类型。
4.总结
- 不管你的method的receiver是指针类型还是非指针类型,都是可以通过指针/非指针类型进行调用的,编译器会帮你做类型转换。涉及到接口类型时,规则有所不同。可参考Golang 学习笔记七 接口
- 在声明一个method的receiver该是指针还是非指针类型时,你需要考虑两方面的内部,第一方面是这个对象本身是不是特别大,如果声明为非指针变量时,调用会产生一次拷贝;第二方面是如果你用指针类型作为receiver,那么你一定要注意,这种指针类型指向的始终是一块内存地址,就算你对其进行了拷贝。熟悉C或者C艹的人这里应该很快能明白。