A3C算法是Google DeepMind提出的一种基于Actor-Critic的深度强化学习算法。A3C是一种轻量级的异步学习框架,这种框架使用了异步梯度下降来最优化神经网络,相对于AC算法不但收敛性能好而且训练速度也快。
在DQN、DDPG算法中均用到了一个非常重要的思想经验回放,而使用经验回放的一个重要原因就是打乱数据之间的相关性,使得强化学习的序列满足独立同分布。然而有优点点的背后也是有代价的,就是它使用了更多的资源和每次交互过程的计算,并且他需要一个off-policy学习算法去更新由旧策略产生的数据。而A3C算法能够在online学习的同时仍然打破这种高度相关性,并且消耗的资源更少。
Paper:
A3C:Asynchronous Methods for Deep Reinforcement Learning
Github:https://github.com/xiaochus/Deep-Reinforcement-Learning-Practice
算法原理
A3C算法的思想其实很简答,实际上就是将Actor-Critic放在了多个线程中进行同步训练。训练的时候,同时为多个线程上分配task,完成任务的线程将自己学习到的参数更新(这里就是异步的思想)到全局网络上,下一次学习的时候同步全局参数到各个线程,然后继续学习。网络结构如图:
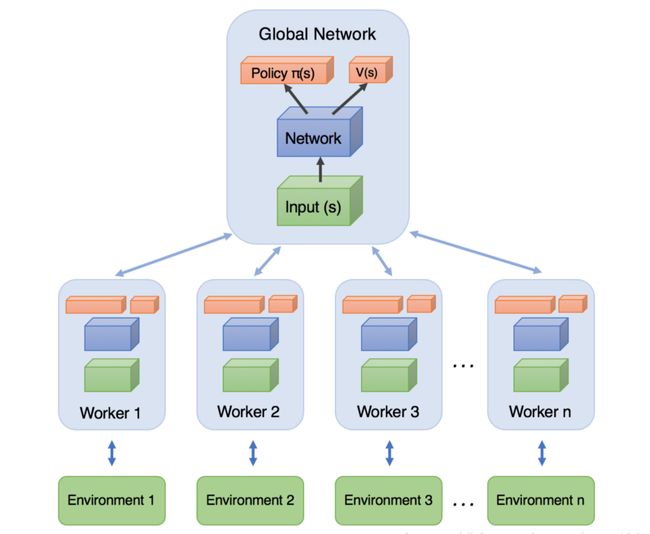
这种异步更新好处是:全局网络需要打破连续性的更新,通过不同线程推送更新的方式能打消这种连续性,使网络不必有用像DQN,DDPG那样的记忆库也能很好的更新。
A3C的算法流程如下所示:

算法的执行流程如下所示:
1.各个worker重置为全局网络;
2.各个worker与环境交互;
3.各个worker开始对自身的Actor和Critic进行训练并获得梯度;
4.使用各个worker的梯度对全局网络进行更新。
算法实现
各个线程worker的梯度能对全局网络进行更新的原因在于每个线程上模型的训练数据是互相不相关的,因此在每个线程上进行训练并推送梯度的思想可以转换为使用不同线程上的数据训练全局网络。
基于Keras实现的A3C如下所示,完整代码参考github:
A3C
A3C类的主要功能是定义网络结构,定义Loss函数、重写训练方法以及启动多线程训练。
_build_actor:定义actor的结构。
_build_critic:定义critic的结构。
_build_model:构建全局网络的结构。
_build_optimizer:定义Loss和重写优化方法。
train:通过多线程的方式更新全局网络。
class A3C:
"""A3C Algorithms with sparse action.
"""
def __init__(self):
self.gamma = 0.95
self.actor_lr = 0.001
self.critic_lr = 0.01
self._build_model()
self.optimizer = self._build_optimizer()
# handle error
self.sess = tf.InteractiveSession()
K.set_session(self.sess)
self.sess.run(tf.global_variables_initializer())
def _build_actor(self):
"""actor model.
"""
inputs = Input(shape=(4,))
x = Dense(20, activation='relu')(inputs)
x = Dense(20, activation='relu')(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=x)
return model
def _build_critic(self):
"""critic model.
"""
inputs = Input(shape=(4,))
x = Dense(20, activation='relu')(inputs)
x = Dense(20, activation='relu')(x)
x = Dense(1, activation='linear')(x)
model = Model(inputs=inputs, outputs=x)
return model
def _build_model(self):
"""build model for multi threading training.
"""
self.actor = self._build_actor()
self.critic = self._build_critic()
# Pre-compile for threading
self.actor._make_predict_function()
self.critic._make_predict_function()
def _build_optimizer(self):
"""build optimizer and loss method.
Returns:
[actor optimizer, critic optimizer].
"""
# actor optimizer
actions = K.placeholder(shape=(None, 1))
advantages = K.placeholder(shape=(None, 1))
action_pred = self.actor.output
entropy = K.sum(action_pred * K.log(action_pred + 1e-10), axis=1)
closs = K.binary_crossentropy(actions, action_pred)
actor_loss = K.mean(closs * K.flatten(advantages)) - 0.01 * entropy
actor_optimizer = Adam(lr=self.actor_lr)
actor_updates = actor_optimizer.get_updates(self.actor.trainable_weights, [], actor_loss)
actor_train = K.function([self.actor.input, actions, advantages], [], updates=actor_updates)
# critic optimizer
discounted_reward = K.placeholder(shape=(None, 1))
value = self.critic.output
critic_loss = K.mean(K.square(discounted_reward - value))
critic_optimizer = Adam(lr=self.critic_lr)
critic_updates = critic_optimizer.get_updates(self.critic.trainable_weights, [], critic_loss)
critic_train = K.function([self.critic.input, discounted_reward], [], updates=critic_updates)
return [actor_train, critic_train]
def train(self, episode, n_thread, update_iter):
"""training A3C.
Arguments:
episode: total training episode.
n_thread: number of thread.
update_iter: update iter.
"""
# Multi threading training.
threads = [Agent(i, self.actor, self.critic, self.optimizer, self.gamma, episode, update_iter) for i in range(n_thread)]
for t in threads:
t.start()
time.sleep(1)
try:
[t.join() for t in threads]
except KeyboardInterrupt:
print("Exiting all threads...")
self.save()
def load(self):
"""Load model weights.
"""
if os.path.exists('model/actor_a3cs.h5') and os.path.exists('model/critic_a3cs.h5'):
self.actor.load_weights('model/actor_a3cs.h5')
self.critic.load_weights('model/critic_a3cs.h5')
def save(self):
"""Save model weights.
"""
self.actor.save_weights('model/actor_a3cs.h5')
self.critic.save_weights('model/critic_a3cs.h5')
多线程训练
Agent类是一个多线程类,继承自threading.Thread。其主要作用是在每个线程上设置A3C与env的交互行为以及reward计算和训练过程。
run:多线程主函数,actor与环境交互并获取数据,在固定的间隔进行模型更新。
discount_reward:计算折扣奖励。
train_episode:网络更新函数。
class Agent(threading.Thread):
"""Multi threading training agent.
"""
def __init__(self, index, actor, critic, optimizer, gamma, episode, update_iter):
threading.Thread.__init__(self)
self.index = index
self.actor = actor
self.critic = critic
self.optimizer = optimizer
self.gamma = gamma
self.episode = episode
self.update_iter = update_iter
self.env = gym.make('CartPole-v0')
def run(self):
"""training model.
"""
global history
global step
while step < self.episode:
observation = self.env.reset()
states = []
actions = []
rewards = []
while True:
x = observation.reshape(-1, 4)
states.append(x)
# choice action with prob.
prob = self.actor.predict(x)[0][0]
action = np.random.choice(np.array(range(2)), p=[1 - prob, prob])
actions.append(action)
next_observation, reward, done, _ = self.env.step(action)
next_observation = next_observation.reshape(-1, 4)
rewards.append(reward)
observation = next_observation[0]
if ((step + 1) % self.update_iter == 0) or done:
lock.acquire()
try:
self.train_episode(states, actions, rewards, next_observation, done)
if done:
episode_reward = sum(rewards)
history['episode'].append(step)
history['Episode_reward'].append(episode_reward)
print('Thread: {} | Episode: {} | Episode reward: {}'.format(self.index, step, episode_reward))
step += 1
finally:
lock.release()
if done:
break
def discount_reward(self, rewards, next_state, done):
"""Discount reward
Arguments:
rewards: rewards in a episode.
next_states: next state of current game step.
done: if epsiode done.
Returns:
discount_reward: n-step discount rewards.
"""
# compute the discounted reward backwards through time.
discount_rewards = np.zeros_like(rewards, dtype=np.float32)
if done:
cumulative = 0.
else:
cumulative = self.critic.predict(next_state)[0][0]
for i in reversed(range(len(rewards))):
cumulative = cumulative * self.gamma + rewards[i]
discount_rewards[i] = cumulative
return discount_rewards
def train_episode(self, states, actions, rewards, next_observation, done):
"""training algorithm in an epsiode.
"""
states = np.concatenate(states, axis=0)
actions = np.array(actions).reshape(-1, 1)
rewards = np.array(rewards)
# Q_values
values = self.critic.predict(states)
# discounted rewards
discounted_rewards = self.discount_reward(rewards, next_observation, done)
discounted_rewards = discounted_rewards.reshape(-1, 1)
# advantages
advantages = discounted_rewards - values
self.optimizer[1]([states, discounted_rewards])
self.optimizer[0]([states, actions, advantages])
几个问题:
问题1:_build_model中使用_make_predict_function。
该函数的作用如下,在多线程启动前进行预编译能够加快运行速度。
Using theano or tensorflow is a two step process: build and compile the function on the GPU, then run it as necessary. make predict function performs that first step.
Keras builds the GPU function the first time you call predict(). That way, if you never call predict, you save some time and resources. However, the first time you call predict is slightly slower than every other time.
This isn't safe if you're calling predict from several threads, so you need to build the function ahead of time. That line gets everything ready to run on the GPU ahead of time.
问题2:为什么使用session。
不使用session会出现下列错误。这个错误与keras的多模型加载有关。
Invalid argument: specified in either feed_devices or fetch_devices was not found in the Graph
问题3:为什么不使用model.fit()。
使用这个方法更新模型会出现下列问题。keras的训练函数适用于单模型,在多线程任务中通过backend使用更加底层的方法进行优化能解决这个问题。
ValueError: Tensor("training/Adam/Const:0", shape=(), dtype=float32) must be from the same graph as Tensor("sub_2:0", shape=(), dtype=float32).
实验结果
实验结果如下所示,可以看出A3C算法基本收敛,能够很好地解决这个问题。在实验中发现,由于启用了多线程模式,A3C的训练速度非常快。

训练过程中,不同的线程异步更新模型并达到收敛:
...
Thread: 1 | Episode: 1997 | Episode reward: 200.0
Thread: 0 | Episode: 1998 | Episode reward: 200.0
Thread: 2 | Episode: 1999 | Episode reward: 200.0
Thread: 3 | Episode: 2000 | Episode reward: 200.0
Thread: 1 | Episode: 2001 | Episode reward: 200.0
Thread: 0 | Episode: 2002 | Episode reward: 200.0
10次测试结果,A3C基本能够解决问题:
play...
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 199.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 199.0
Reward for this episode was: 200.0