本篇已加入《.NET Core on K8S学习实践系列文章索引》,可以点击查看更多容器化技术相关系列文章。上一篇介绍了Google开发的容器监控工具cAdvisor,但是其提供的操作界面较为简陋,且不支持监控多Host,实用性有待提高。因此,本篇会介绍一个流行的生产级监控工具,不,准确说来应该是一个监控方案,它就是Prometheus!
# 实验环境:阿里云ECS主机(两台),CentOS 7.4
一、Prometheus简介
1.1 关于Prometheus

Prometheus是由SoundCloud开发的开源监控系统的开源版本。2016年,由Google发起的云原生基金会CNCF (Cloud Native Computing Foundation) 将其纳入为其第二大开源项目(第一大开源项目是Kubernetes)。Prometheus提供了一整套的包括监控数据搜集、存储、处理、可视化和告警的完整解决方案。
Prometheus官网地址:https://prometheus.io/
Prometheus GitHub:https://github.com/prometheus/prometheus/
1.2 Prometheus架构
Prometheus在其官方github上贴出的其架构图如下:

为了更容易理解这个架构,这里我们采用园友Cloud Man(他也是本文参考资料《每天5分钟玩转Docker》作者)总结的下图,它去掉了一些部分,只保留了最重要的组件,可以帮助我们避免注意力分散。
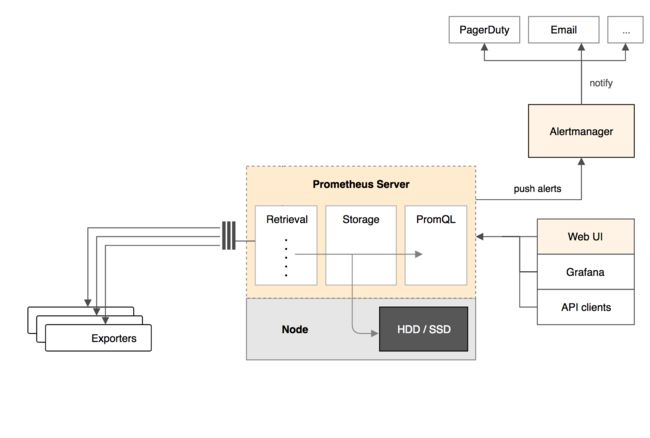
从上图看来,我们着重需要关注以下几个核心组件:
(1)Prometheus Server:负责从Exporter中拉取和存储监控数据,并提供一套查询语言(PromQL)供用户使用。
(2)Exporter:负责收集目标对象(如Host或Container)的性能数据,并通过HTTP接口供Prometheus Server获取。
(3)可视化组件 Grafana:获取Prometheus Server提供的监控数据并通过Web UI的方式完美展现数据。
(4)AlertManager:负责根据告警规则和预定义的告警方式发出例如Email、Webhook之类的告警。
1.3 Prometheus数据模型
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
- metric 名字:该名字应该具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总数。其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 标签:使同一个时间序列有了不同维度的识别。例如 http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及下划线组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
时间序列格式:
{
示例:
api_http_requests_total{method="POST", handler="/messages"}
之前有分享过另一个时序数据库InfluxDB,它也是一个不错的时序数据库,经常用来作为监控数据的存储。OK,关于Prometheus的简介就到这儿,下面那我们开始动手将Prometheus初步用起来。
二、Prometheus实践
2.1 实验环境说明
此次实验会搭建一个基于Prometheus的监控系统,用于监控两台阿里云ECS主机,监控目标为Host和容器两个层次。
| 主机 | IP | 运行组件 |
| 阿里云ECS1 | 47.102.140.100 | Prometheus Server、Grafana、Exporter(Node Exporter & cAdvisor) |
| 阿里云ECS2 | 47.102.140.101 | Exporter(Node Exporter & cAdvisor) |
Note:Prometheus支持多种Exporter,这里我们使用Node Exporter 和 cAdvisor。其中,Node Exporter用于收集Host相关数据,cAdvisor用于收集容器相关数据。Node Exporter 和 cAdvisor 会运行在所有实验主机上。
2.2 运行Node Exporter
在两台主机上执行以下命令运行Node Exporter:
docker run -d -p 9100:9100 \ -v "/proc:/host/proc" \ -v "/sys:/host/sys" \ -v "/:/rootfs" \ prom/node-exporter \ --path.procfs /host/proc \ --path.sysfs /host/sys \ --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
执行成功后,会创建一个Node Exporter的容器实例,访问两台主机的地址 http://[Your Host IPs]:9100/metrics,你可以看到如下图所示的信息:

如果能看到上图,说明你的Node Exporter可以为Prometheus提供该Host的监控数据了。
2.3 运行cAdvisor
这部分我们在上一篇《容器监控(2)cAdvisor》中已经介绍过了,这里我们继续在这两台主机中执行以下命令安装运行cAdvisor(如果已经运行了,就不必再执行了):
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
同样,我们也可以通过访问 http://[Your Host IPs]:8080/metrics 来查看cAdvisor提供的监控数据,如下图所示:

如果能看到上图,说明你的cAdvisor可以为Prometheus提供该Host的监控数据了。
2.4 运行Prometheus Server
这里我们在主机A(表中的ECS1)上执行以下命令来运行Prometheus Server:
docker run -d -p 9090:9090 \ -v /edc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \ --name prometheus \ prom/prometheus
此外,这里的prometheus.yml 是Prometheus Server的配置文件,需要事先编辑好并放到指定目录下(这里是/edc/prometheus/目录下)让docker可以读取到,内容如下:
global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: 'edc-lab-monitor' alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 rule_files: # - "first.rules" # - "second.rules" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['47.102.140.100:9090'] - job_name: 'host' static_configs: - targets: ['47.102.140.100:9100','47.102.140.101:9100'] - job_name: 'container' static_configs: - targets: ['47.102.140.100:8080','47.102.140.101:8080']
这里需要注意的配置是scrape_configs中的static_configs,里面定义了Prometheus会从哪些Exporter中抓取监控数据,这里指定了两台云主机的Node Exporter与cAdvisor。
执行成功后,Prometheus容器已经创建好了,访问这台ECS1的地址:http://[ECS1 Host IP]:9090/metrics,如下图所示: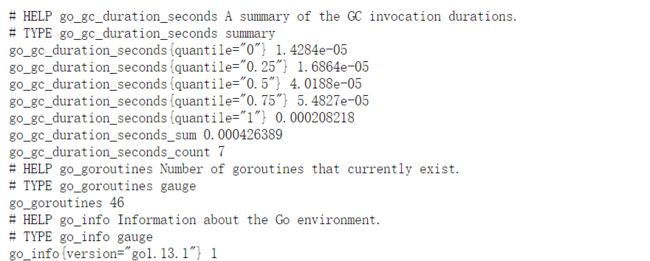
然后,我们直接访问http://[ECS1 Host IP]:9090,会进入Prometheus主页:
单击菜单Status => Targets,会看到所有监控的目标Exporters:

可以看到所有监控目标的状态都是Up,表示Prometheus Server可以正常获取监控数据。
2.5 运行Grafana
这里我们继续在主机A(ECS1)上执行以下命令运行Grafana:
docker run -d -i -p 3000:3000 \ -e "GF_SERVER_ROOT_URL=http://grafana.server.name" \ -e "GF_SECURITY_ADMIN_PASSWORD=secret" \ grafana/grafana
-e "GF_SECURITY_ADMIN_PASSWORD=secret" 则指定了Admin用户的密码为secret,这里你也可以随你的意愿改为你可以记得住的。
执行成功后,我们可以通过访问:http://[ECS1 Host IP]:3000 看到以下Grafana的登录界面

下面几个步骤用于初始化配置Grafana让其可以展示监控数据仪表盘Dashboard:
Step1.登陆之后进入主页,选择引导页,从"add data source"开始,第一步选择时序数据库,这里选择Prometheus

Step2.配置Prometheus Server地址及Name,完成后点击“Save&Test”:

Step3.回到引导主页,选择Add Dashboard按钮,进入Dashboard页,选择Import Dashboard,进入下图:

这里选择的Dashboard,你可以在grafana的dashboard官网的搜索你喜欢的关于Docker监控主题的各种Dashboard样式。这里我们要做的就是将其ID(这里我选择的一个Docker监控的dashboard ID是193,其余的我不记得了)复制到图中的文本框中(当然,你也可以下载json并粘贴进去)。
Step4.Grafana识别之后,就会显示其详情让你确认。在确认页选择Prometheus的数据源,这里选择我们刚刚添加的数据源,然后点击Import即可完成导入。

完成以上导入Dashboard步骤之后,这里我的Dashboard列表有了三个Dashboard:
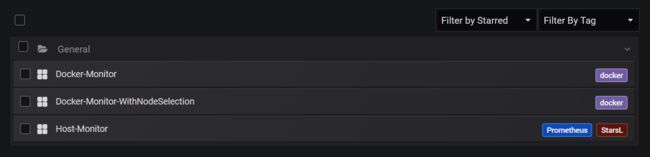
这里我们主要关注第一个(Docker-Monitor)和第三个(Host-Monitor),先来看第一个Dashboard,它主要是为我们展示Docker层次的监控面板:
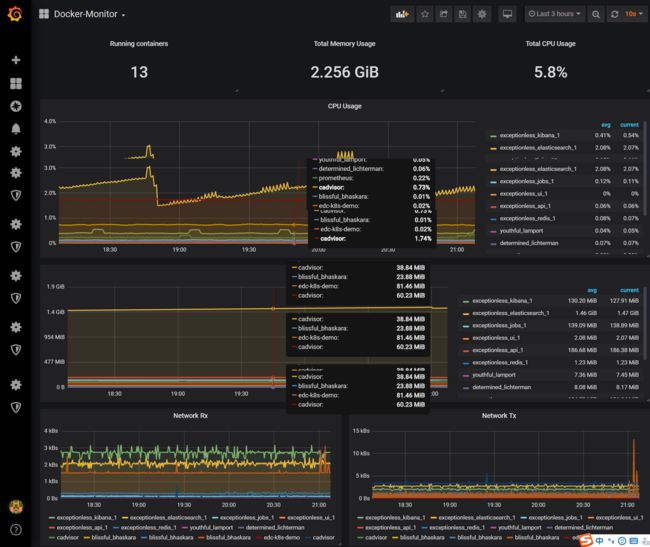
从上图可以看到两台Host中的所有容器监控数据一览无遗。
第三个面板(Host-Monitor)的展示面板如下图所示:

在上图中,我们选择的分组是Host,它主要是收集来自Node-Exporter中反馈的基于Host的监控数据,可以实时展示Host的关键指标。不过,它每次只能显示单台Host的数据,我们可以通过切换Host IP下拉列表查看不同Host的性能数据。
此外,我们一般会将其投屏到工作区的电视上,所以我们可以点击下面这个按钮以投屏模式显示在电视上,供整个团队及时查看。

三、监控工具大比较
这里我们仍然引用Cloud Man总结的一张表来看看:

毫无疑问,Prometheus作为生产级的监控方案,对其他几个工具形成了压倒性的优势。而事实上,Prometheus + Grafana + cAdvisor这一套方案也是大家广泛采用的结构。
四、小结
本文首先简单介绍了Prometheus及其架构,然后通过搭建基于Prometheus + cAdvisor + Grafana的监控系统,能够实现对于多台云主机的性能监控(包括Host和容器两个层次的数据)。当然,Prometheus还有很多的配置和好玩的地方例如Alert Manager可以及时发送告警通知等,笔者也只是初步把玩,还有很多东西不知道。后面我会分享引入K8S后,结合Prometheus + cAdvisor + Grafana实现K8S集群的监控,敬请期待。
参考资料
Cloud Man,《每天5分钟玩转Docker容器技术》
无涯,《从零开始搭建Prometheus自动监控告警系统》
三无程序员,《Prometheus》
虎纠卫,《监控神器-普罗米修斯Prometheus》
项思凯,《Prometheus介绍详解》
rj-bai,《Prometheus+Grafana打造全方位监控系统》
GeekerLou,《云原生监控系统Prometheus》
Cloud Man,《一文搞懂各种容器监控方案》
作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。