一、概述
在数据分析中,我们经常讨论如何才能从数据中进行挖掘和分析出其中有价值的地方。一直是每一个学习机器学习和数据挖机的从业人员,不得不思考的问题。如果用DIKW体系讨论 数据、信息、知识、智慧之间的关系,我们可以从下图清洗的看到每一层之间的逻辑关系。
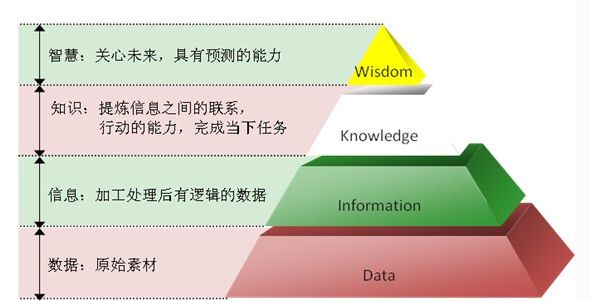
数据是记录下来的图形符号数字。它是原始的素材,未被加工解释,没有回答特定的问题,没有任何意义;
信息是已经被处理、具有逻辑关系的数据,是对数据的解释,这种信息对其接收者具有意义;
知识是从信息中过滤、提炼及加工而得到的,我们能从其中抽象出一个本质的东西,原则的东西,规律的东西;
智慧是从知识的积累与创新中凝华而成的,体现了一定的人生哲理。
二、认识数据
数据是我们生活中无时无刻不在产生的,每时每刻我们发布的新闻,头条,链接,分享,语音等等,现今的时代已经是信息爆炸的时代,我们如何认识数据,如何定义数据,如何分析数据今天又好像特别陌生。所以我们需要一些方法、策略、技术去帮助我们理解数据以及数据的抽象。
定性和定量属性
在数据分析中,属性、维(Dimension)、特征(feature)和变量(Variable)可以互换使用,按照属性值功能的不同,可以把属性分位定性属性和定量属性。
(1)定性属性是指用文本描述对象的特征,定性属性主要分为三类:
标称属性:也叫做类别属性,用于对数据对象分类(Category),比如,头发的颜色、职业;
二元属性:只有两个类别的属性,两个属性之间有对称和不对称的,对称的属性比如性别,非对称的属性比如是否喝酒开车更不安全的权重不同。
序数属性:属性的顺序是有意义的,通常用于等级评定。序数属性也可以通过把数值属性分割成不同的区间来得到,比如,年龄段。
在序数属性中,有一类重要的属性,叫做时间属性,一些常见的分析方法,比如时序分析,周期性分析等都是基于时间属性的。
(2)定量属性是指用数值描述对象,可以比较大小,是可以量化的属性,定量属性主要分为两个标度:
区间标度:可度量的数值,用整数或实数表示,比如,年纪、薪水
比率标度:比例数值,比如,速度、留存率
定量属性通常含有量纲,例如,身高的量纲是cm,而薪水的量纲是元,同一量纲的数据可以比较大小,
不同量纲的数据,需要通过归一化去量纲之后,比较大小才有意义。定性数据通常是分析数据的一个角度,
增加维度,从不同的角度来看待问题,能够细分指标,增加分析的深度。
二、机器学习三要素
(1)模型
在机器学习的过程中,我们一般要先定义模型,什么是模型? 我们借用知乎(https://www.zhihu.com/question/285520177)上的一段话,可以简要的理解一下。模型本质上是一个函数。是一个什么函数呢? 是从一个样本 到样本的标记值 的映射,即 。因为在机器学习中,如果我没有假设前提是存在的,那么我们不可能从未知到已知的过程中解脱出来,我们面临的是一个未知的世界,但我们假设一些前提或者因果,通过推到论证,一步一步去逼近拟合我们的真实世界。所以我们要进行模型的定义。
(2)策略
由于假设的前提存在,客观世界并不存在我们理想化的模型函数,否则我们不必要进行相应的假设前提,那么我们如何逼近真实的世界呢,这里我们需要引用一些策略去逼近我们的真实情况。在这里我们通常的做法有以下两种策略方法:损失函数与风险函数。
损失函数
损失函数用来度量预测错误的程度。常用的损失函数有0-1损失函数(等于设定值损失为零,不等于损失为1),平方损失函数(设定值与预测值的差的平方),绝对损失函数(设定值与预测值的差的绝对值)。但是损失函数一般是用来度量模型对于一个样本的预测与分类的准确度。一般我们进行训练时,需要很多样本。
风险函数
若有多个样本,则可以通过求出每个样本的损失,然后求这些样本的平均损失,这个平均损失,就是模型的经验风险。风险函数可以度量模型对于多个样本的预测的准确度,除了经验风险,还有结构风险。结构化风险是为了防止模型的过拟合,加入了一个正则化项,这个正则化项是关于结构的函数。
(3)算法
机器学习中的算法,主要是为了求解我们假设的模型的变量,我们需要通过一些算法如:决策树方法、SVM、朴素贝叶斯方法、KNN 、K均值、随机森林方法等。
三、监督学习
机器学习的主要任务便是聚焦于几个常见的问题:分类、回归和标注。
机器学习在不同的维度会有不同的划分,最普遍的划分大致可以分为监督学习、非监督学习、半监督学习、强化学习。
监督学习的数据集拥有既定的标签,即训练的数据集已经有了某种特定的属性,
非监督学习的数据集没有任何既定标签,完全让算法去分析这些数据,找出一些特殊情况,大多数聚类算法都是非监督学习。
半监督学习,虽然数据集有既定标签,但是有时候有些数据会有缺失,例如银行信用体系中,有些人的年龄数据缺失、有些人性别数据缺失等等。
强化学习,即根据当下的环境不断的去学习,不断的发现数据集,不断的训练自己,例如阿尔法狗以及无人驾驶等,都是增强学习的应用。