WebSSH终端录像的实现终于来了
前边写了两篇文章『Asciinema:你的所有操作都将被录制』和『Asciinema文章勘误及Web端使用介绍』深入介绍了终端录制工具Asciinema,我们已经可以实现在终端下对操作过程的录制,那么在WebSSH中的操作该如何记录并提供后续的回放审计呢?
一种方式是『Asciinema:你的所有操作都将被录制』文章最后介绍的自动录制审计日志的方法,在主机上添加个脚本,每次连接自动进行录制,但这样不仅要在每台远程主机添加脚本,会很繁琐,而且录制的脚本文件都是放在远程主机上的,后续播放也很麻烦
那该如何更好处理呢?下文介绍一种优雅的方式来实现,核心思想是不通过录制命令进行录制,而在Webssh交互执行的过程中直接生成可播放的录像文件
设计思路
通过上边两篇文章的阅读,我们已经知道了Asciinema录像文件主要由两部分组成:header头和IO流数据
header头位于文件的第一行,定义了这个录像的版本、宽高、开始时间、环境变量等参数,我们可以在websocket连接创建时将这些参数按照需要的格式写入到文件
header头数据如下,只有开头一行,是一个字典形式
{"version": 2, "width": 213, "height": 55, "timestamp": 1574155029.1815443, "env": {"SHELL": "/bin/bash", "TERM": "xterm-256color"}, "title": "ops-coffee"}整个录像文件除了第一行的header头部分,剩下的就都是输入输出的IO流数据,从websocket连接建立开始,随着操作的进行,IO流数据是不断增加的,直到整个websocket长连接的结束,那就需要在整个WebSSH交互的过程中不断的往录像文件追加输入输出的内容
IO流数据如下,每一行一条,列表形式,分别表示操作时间,输入或输出(这里我们为了方便就写固定字符串输出),IO数据
[0.2341010570526123, "o", "Last login: Tue Nov 19 17:11:30 2019 from 192.168.105.91\r\r\n"]似乎很完美,按照上边的思路录像文件就应该没有问题了,但还有一些细节需要处理
首先是需要历史连接列表,在这个列表里可以看到什么时间,哪个用户连接了哪台主机,当然也需要提供回放功能,新建一张表来记录这些信息
class Record(models.Model):
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
host = models.ForeignKey(Host, on_delete=models.CASCADE, verbose_name='主机')
user = models.ForeignKey(User, on_delete=models.CASCADE, verbose_name='用户')
filename = models.CharField(max_length=128, verbose_name='录像文件名称')
def __str__(self):
return self.host其次还需要考虑的一个问题是header和后续IO数据流要写入同一个文件,这就需要在整个websocket的连接过程中有一个固定的文件名可被读取,这里我使用了主机+用户+当前时间作为文件名,同一用户在同一时间不能多次连接同一主机,这样可保证文件名不重复,同时避免操作写入错误的录像文件,文件名在websocket建立时初始化
def __init__(self, host, user, websocket):
self.host = host
self.user = user
self.time = time.time()
self.filename = '%s.%s.%d.cast' % (host, user, self.time)IO流数据会持续不断的写入文件,这里以一个独立的方法来处理写入
def record(self, type, data):
RECORD_DIR = settings.BASE_DIR + '/static/record/'
if not os.path.isdir(RECORD_DIR):
os.makedirs(RECORD_DIR)
if type == 'header':
Record.objects.create(
host=Host.objects.get(id=self.host),
user=self.user,
filename=self.filename
)
with open(RECORD_DIR + self.filename, 'w') as f:
f.write(json.dumps(data) + '\n')
else:
iodata = [time.time() - self.time, 'o', data]
with open(RECORD_DIR + self.filename, 'a', buffering=1) as f:
f.write((json.dumps(iodata) + '\n'))record接收两个参数type和data,type标识本次写入的是header头还是IO流,data则是具体的数据
header只需要执行一次写入,所以将其放在ssh的connect方法中,只在ssh连接建立时执行一次,在执行header写入时同时往数据库插入新的历史记录数据
调用record方法写入header
def connect(self, host, port, username, authtype, password=None, pkey=None,
term='xterm-256color', cols=80, rows=24):
...
# 构建录像文件header
self.record('header', {
"version": 2,
"width": cols,
"height": rows,
"timestamp": self.time,
"env": {
"SHELL": "/bin/bash",
"TERM": term
},
"title": "ops-coffee"
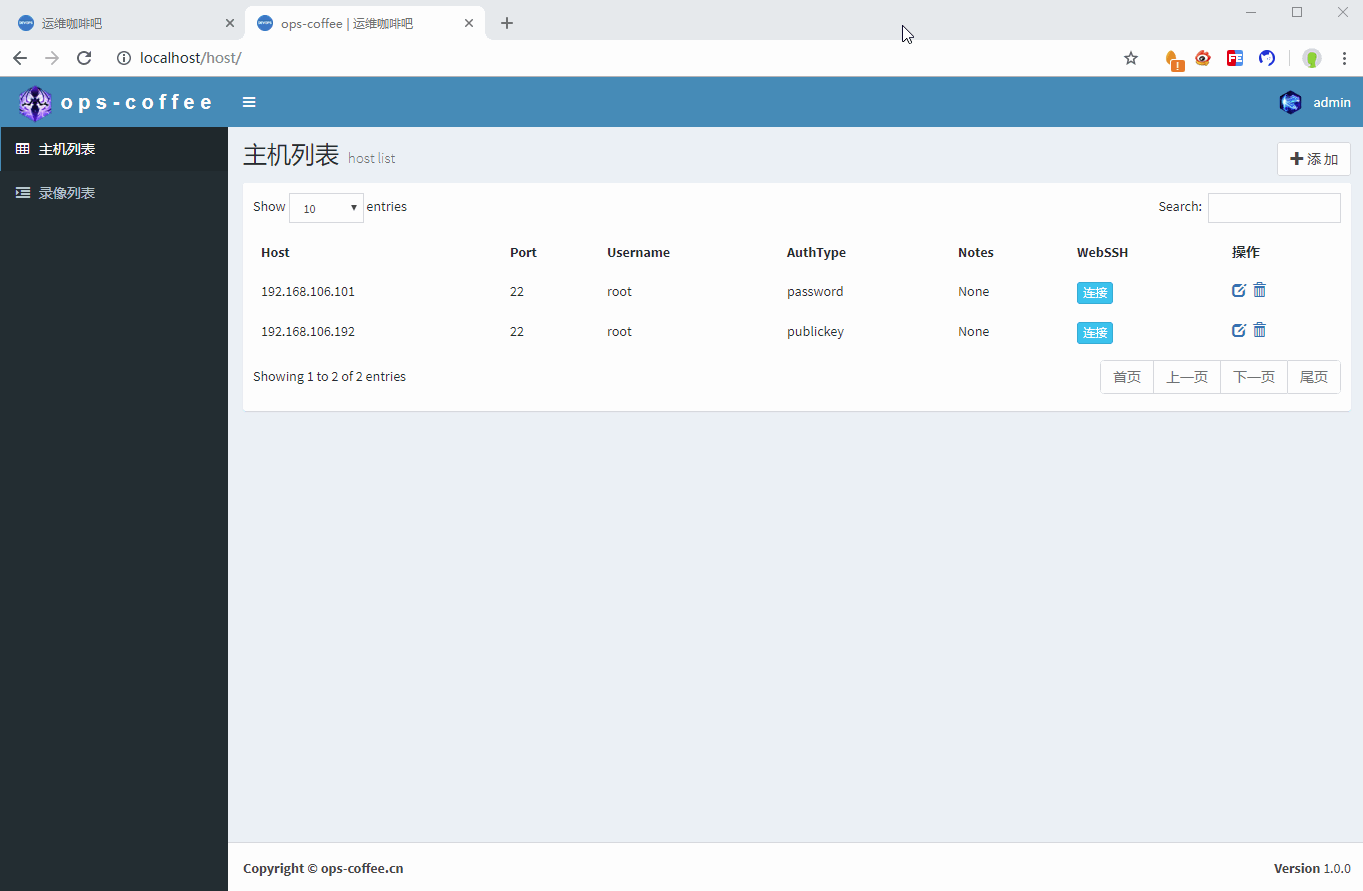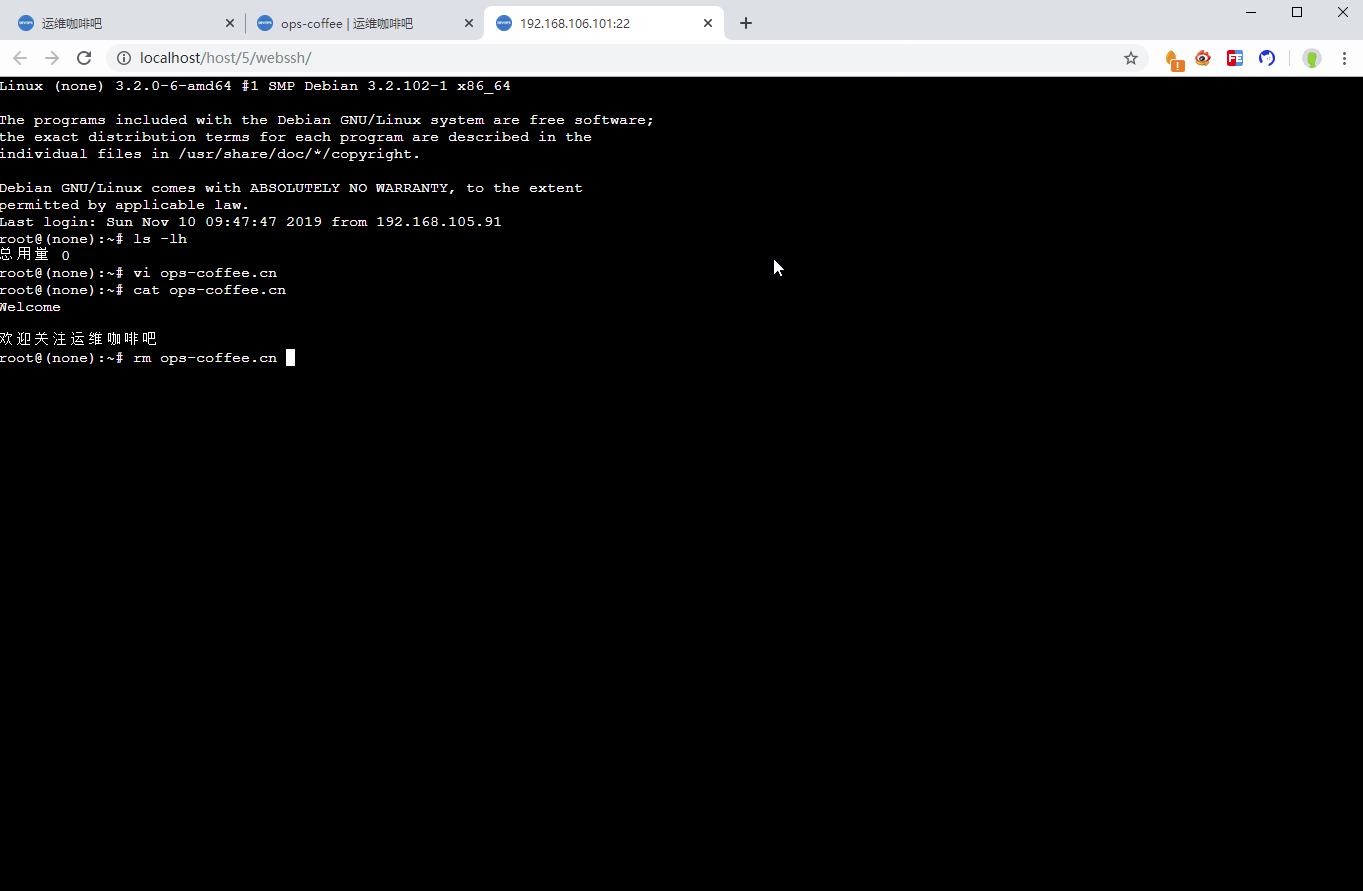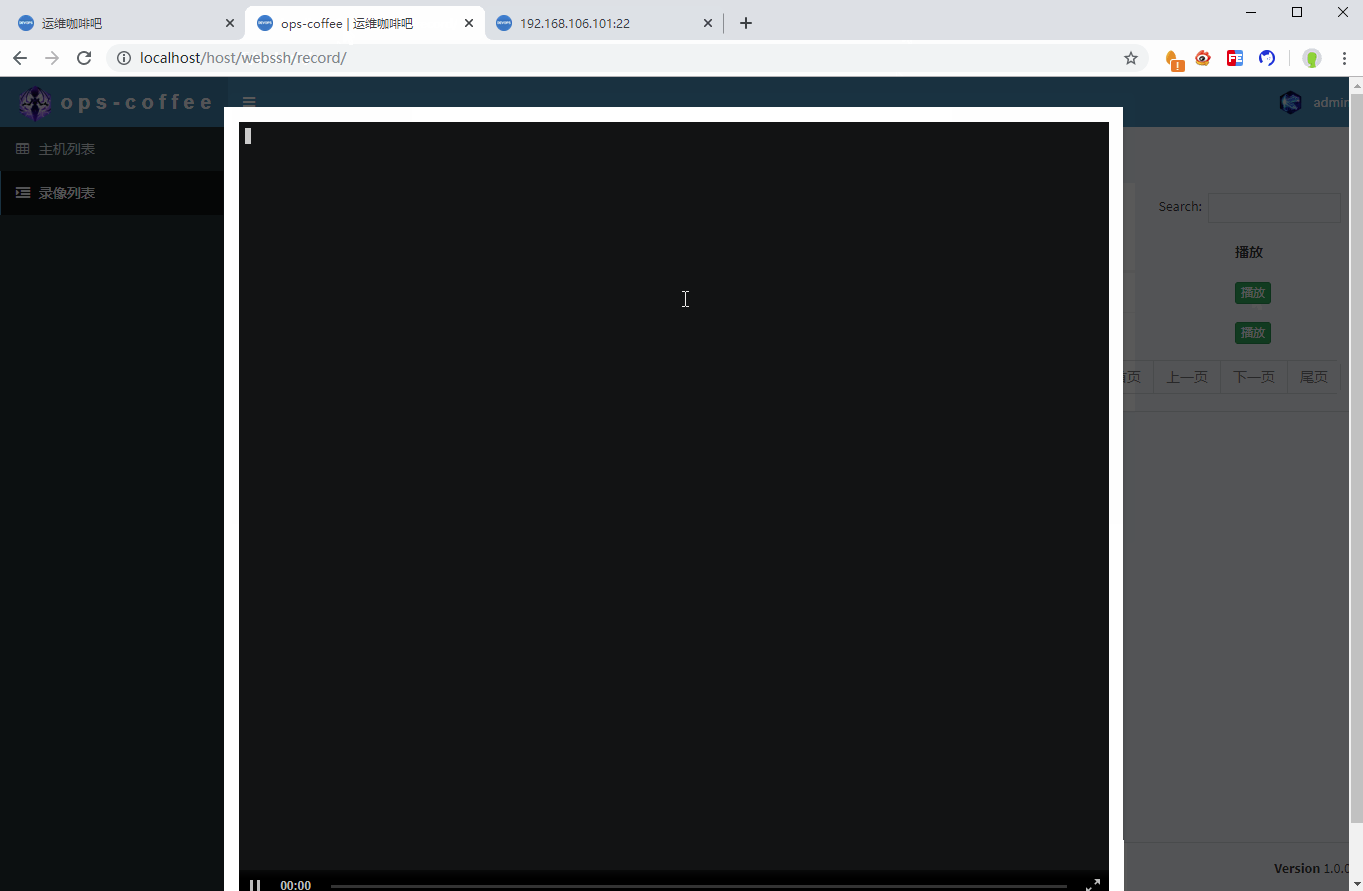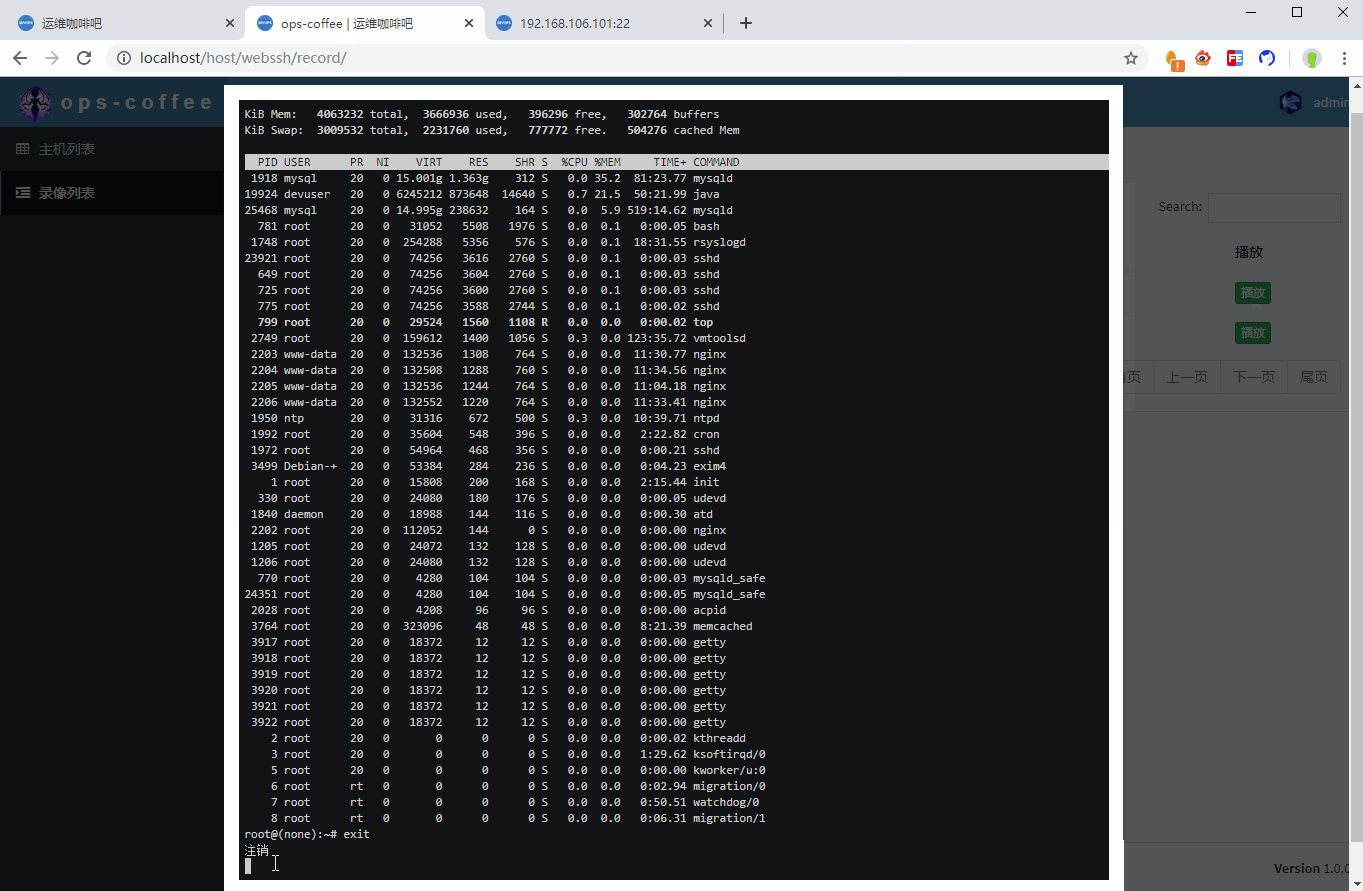
})IO流数据则需要与返回给前端的数据保持一致,这样就能保证前端显示什么录像就播放什么了,所以所有需要返回前端数据的地方都同时写入录像文件即可
调用record方法写入io流数据
def connect(self, host, port, username, authtype, password=None, pkey=None,
term='xterm-256color', cols=80, rows=24):
...
# 连接建立一次,之后交互数据不会再进入该方法
for i in range(2):
recv = self.ssh_channel.recv(65535).decode('utf-8', 'ignore')
message = json.dumps({'flag': 'success', 'message': recv})
self.websocket.send(message)
self.record('iodata', recv)
...
def _ssh_to_ws(self):
try:
with self.lock:
while not self.ssh_channel.exit_status_ready():
data = self.ssh_channel.recv(1024).decode('utf-8', 'ignore')
if len(data) != 0:
message = {'flag': 'success', 'message': data}
self.websocket.send(json.dumps(message))
self.record('iodata', data)
else:
break
except Exception as e:
message = {'flag': 'error', 'message': str(e)}
self.websocket.send(json.dumps(message))
self.record('iodata', str(e))
self.close()由于命令执行与返回都是多线程的操作,这就会导致在写入文件时出现文件乱序影响播放的问题,典型的操作有vim、top等,通过加锁self.lock可以顺利解决
最后历史记录页面,当用户点击播放按钮时,调用js弹出播放窗口
// 播放录像
function play(host,user,time,file) {
$('#play').html(
'asciinema-player标签的详细参数介绍可以看这篇文章『Asciinema文章勘误及Web端使用介绍』
演示与总结
在写入文件的方案中,考虑了实时写入和一次性写入,实时写入就像上边这样,所有的操作都会实时写入录像文件,好处是录像不丢失,且能在操作的过程中进行实时的播放,缺点也很明显,就是会频繁的写文件,造成IO开销
一次性写入可以在用户操作的过程中将录像数据写入内存,在websocket关闭时一次性异步写入到文件中,这种方案在最终写入文件时可能因为种种原因而失败,从而导致录像丢失,还有个缺点是当你WebSSH操作时间过长时,会导致内存的持续增加
两种方案一种是对磁盘的消耗另一种是对内存的消耗,各有利弊,当然你也可以考虑批量写入,例如每分钟写一次文件,一分钟之内的保存在内存中,平衡内存和磁盘的消耗,期待你的实现

相关文章推荐阅读:
- Django实现WebSSH操作Kubernetes Pod
- Django实现WebSSH操作物理机或虚拟机