- 单片机 - RAM 与内存、ROM 与硬盘 之间的详细对比总结
Peter_Deng.
单片机嵌入式硬件
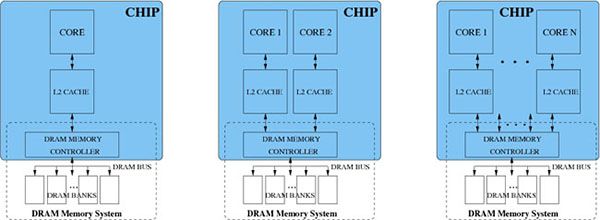
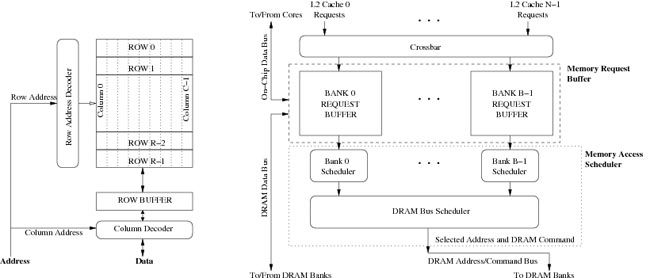
RAM与内存RAM(RandomAccessMemory,随机存取存储器)和内存这两个术语通常是同义词,即内存常常指的就是RAM。1.RAM(内存)定义:RAM是计算机中的主存储器,用于临时存储正在运行的程序和数据。所有正在进行的操作,包括正在运行的程序、操作系统和应用程序数据,都存储在RAM中。工作原理:RAM通过直接访问任何位置的方式存取数据,故称为随机存储。数据存取速度非常快,因此在计算机中
- 分布式中间件:Redisson 入门和分布式锁
顾北辰20
分布式中间件分布式中间件redisson
分布式中间件:Redisson入门和分布式锁在分布式系统的开发中,处理并发问题是一个常见且具有挑战性的任务。为了确保数据的一致性和完整性,我们常常需要使用分布式锁。Redisson作为一个强大的分布式Java驻内存数据网格(In-MemoryDataGrid)中间件,为我们提供了简单且高效的分布式锁解决方案。本文将带你入门Redisson,并介绍如何使用它实现分布式锁。1.引入Redisson依赖
- 每日一题--内存池
秋凉 づᐇ
java开发语言
内存池(MemoryPool)是一种高效的内存管理技术,通过预先分配并自主管理内存块,减少频繁申请/释放内存的系统开销,提升程序性能。它是高性能编程(如游戏引擎、数据库、网络服务器)中的核心优化手段。内存池的核心原理预先分配:初始化时一次性申请一大块内存(称为“池”),避免程序运行时频繁调用malloc/new。自主管理:将大块内存划分为多个固定或可变大小的内存单元,由程序自行分配和回收。复用机制
- pcie bar空间region [disable]无法访问
格局视界
PCIEarm开发
现象没有截图,下图[virtual]时需要重启host,为[disable]时可以用解决方案的命令解决方案setpcie-s01:00.0COMMAND=0x02解释thiswillenablememorymappedtransfersforyourpciedevice.In4.8kernelsomethingischanges,sodriversdoesnotenablemmtransfersb
- MTK ADSP
yyc_audio
嵌入式硬件
MTK音频硬件概念AFE:音频前端硬件audiofrontendhwAFEMEMIF(FE):PCMDMA,memoryread/writeAudiointerconnection:connectionfabricforaudiosubmodule。核心路由器件。负责FE和BE之间的连接和路由。DAI(BE):DigitalAudioI/F,eTDM/I2S/DMIC.–EnhancedTDM,c
- FIN41920 Sustainable Finance
后端
FIN41920SustainableFinanceGroupProject2025ThepurposeofthisprojectistoevaluatetheabilityofapplyingUStoxicemissiondataandaccountingdatatoanalysetheeffectoftoxicemissionsonfirms’financialperformance.Here
- MySQL 进阶学习文档
你曾经是少年
数据库
一、存储引擎1.1核心架构四层架构:连接层→服务层→引擎层→存储层插件式存储引擎:不同引擎独立管理数据存储,可动态选择1.2主流引擎对比特性InnoDB(默认)MyISAMMemory事务支持✅支持❌不支持❌不支持锁粒度行锁表锁表锁外键支持✅支持❌不支持❌不支持存储位置磁盘磁盘内存适用场景高并发事务读多写少临时数据缓存选择建议:优先选InnoDB(支持事务和外键)读多写少且无需事务选MyISAM临
- 《Operating System Concepts》阅读笔记:p449-p459
操作系统
《OperatingSystemConcepts》学习第35天,p449-p459总结,总计11页。一、技术总结1.NVM&SSDFlash-memory-basedNVMisfrequentlyusedinadisk-drive-likecontainer,inwhichcaseitiscalledasolid-statedisk(SSD)(Figure11.3)。2.HDDScheduling
- 【存储中间件】Redis核心技术与实战(六):Redis的设计与实现(缓存淘汰算法、过期策略与惰性删除)
道友老李
#Redis核心技术与实战架构师进阶-存储中间件缓存中间件redis
文章目录Redis的设计与实现缓存淘汰算法maxmemoryNoevictionvolatile-lruvolatile-ttlvolatile-randomallkeys-lruallkeys-randomLRU算法近似LRU算法LFU算法为什么Redis要缓存系统时间戳过期策略和惰性删除过期惰性删除lazyfree个人主页:道友老李欢迎加入社区:道友老李的学习社区Redis的设计与实现缓存淘汰
- JVM OOM问题如何排查和解决
昔我往昔
jvmjvm
在Java开发中,JVMOOM(OutOfMemoryError)问题通常是指程序运行时,JVM无法为对象分配足够的内存空间,导致发生内存溢出的错误。这个问题往往和内存的配置、内存泄漏、或者资源过度使用等因素有关。1.OOM错误类型JVM中的OOM错误主要包括以下几种类型:java.lang.OutOfMemoryError:Javaheapspace:堆内存不足。堆内存用于存储对象,发生此错误时
- [科普] SRAM 和 PSRAM 易失性存储器(断电后数据丢失)(由DS-R1生成)
兴趣使然_
嵌入式硬件相关fpga开发
在易失性存储器(断电后数据丢失)中,SRAM和PSRAM是两种常见的高速存储方案,但它们的技术原理和应用场景有明显差异。以下是详细对比和扩展说明:1.SRAM(StaticRandom-AccessMemory)核心特性静态存储:通过6晶体管(6T)锁存结构存储数据,无需外部刷新电路,数据在通电时永久保持。速度:读写速度极快(纳秒级延迟),远高于DRAM或Flash,常见于高速缓存场景。功耗:静态
- 鸿蒙NEXT开发之开屏广告实现
怀男孩
harmonyosharmonyos华为
1.广告请求服务的实现首先,你需要创建一个广告请求服务来处理广告的加载和展示。你已经在代码中实现了requestAd函数,接下来需要处理广告加载、显示、点击等事件。可以考虑以下结构:1.1创建广告加载函数import{advertising,identifier}from'@kit.AdsKit';import{hilog}from'@kit.PerformanceAnalysisKit';imp
- Lodash源码分析-every,some,size,includes
初学者7.
Loadsh源码分析javascript前端
collection相关的函数,collection指的是一组用于处理集合(如数组或对象)的工具函数。lodash源码研读之every,some,size,includes一、源码地址GitHub地址:GitHub-lodash/lodash:AmodernJavaScriptutilitylibrarydeliveringmodularity,performance,&extras.官方文档地址
- Lodash源码分析-uniq,uniqBy,uniqWith
初学者7.
Loadsh源码分析javascript前端
lodash源码研读之uniq,uniqBy,uniqWith一、源码地址GitHub地址:GitHub-lodash/lodash:AmodernJavaScriptutilitylibrarydeliveringmodularity,performance,&extras.官方文档地址:Lodash官方文档二、结构分析uniq,uniqBy,uniqWith基于baseUniq模块。三、函数介
- 指令系统和计算机体系结构——一文解析冯·诺依曼架构
点滴汇聚江河
软考-软件设计师架构
文章目录一、核心思想二、核心组成部分1.中央处理器(CPU)2.内存(Memory)3.输入/输出(I/O)设备4.总线(Bus)三、工作流程四、冯·诺依曼架构的局限性五、现代计算机的改进1.流水线技术(Pipeline)关键机制2.高速缓存(Cache)关键机制3.多核CPU(Multi-Core)关键挑战与解决方案4.乱序执行(Out-of-OrderExecution)关键技术5.其他关键改
- Starrocks 命令 Alter table DISTRIBUTED 重分布数据的实现
鸿乃江边鸟
大数据StarRocksstarrocks大数据
背景在前文Starrocks写入报错primarykeymemoryusageexceedsthelimit中,可以通过ALTERTABLExxxxDISTRIBUTEDBYHASH(xx)BUCKETS50;来改变数据的分布状态,具体的执行过程是怎么样的呢?分析首先对应的g4文件中为alterTableStatement,这里最终的调用是AlterJobExecutor.visitAlterTa
- mybatis plus sql性能分析插件
asvxc324deas
程序员mybatissqlandroid
在MybatisPlusConfig加入sql性能分析插件一、mybatis-plus自带的性能分析/**SQL执行效率插件性能分析插件*/@Bean@Profile({“dev”,“test”})//设置devtest环境开启publicPerformanceInterceptorperformanceInterceptor(){PerformanceInterceptorperformance
- JVM内存溢出(OOM)的场景
KBkongbaiKB
jvmjava开发语言
一、JVM内存结构快速复盘1.1运行时数据区核心架构JVMMemory线程私有区线程共享区程序计数器虚拟机栈本地方法栈堆内存方法区/元空间1.2各区域默认容量(JDK8)内存区域默认最大值调整参数堆内存(Heap)物理内存1/4-Xmx元空间(Metaspace)无限制(受物理内存约束)-XX:MaxMetaspaceSize栈内存(Stack)1MB(不同OS有差异)-Xss直接内存(Direc
- 史上最全JVM面试八股文合集
Java小海.
面试java职场和发展程序人生后端
简述JVM内存模型线程私有的运行时数据区:程序计数器、Java虚拟机栈、本地方法栈。线程共享的运行时数据区:Java堆、方法区。简述程序计数器程序计数器表示当前线程所执行的字节码的行号指示器。程序计数器不会产生StackOverflowError和OutOfMemoryError。简述虚拟机栈Java虚拟机栈用来描述Java方法执行的内存模型。线程创建时就会分配一个栈空间,线程结束后栈空间被回收。
- 决策树算法全解析:从零基础到Titanic实战,一文搞定机器学习经典模型
吴师兄大模型
0基础实现机器学习入门到精通算法机器学习决策树人工智能深度学习编程开发语言
Langchain系列文章目录01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南02-玩转LangChainMemory模块:四种记忆类型详解及应用场景全覆盖03-全面掌握LangChain:从核心链条构建到动态任务分配的实战指南04-玩转LangChain:从文档加载到高效问答系统构建的全程实战05-玩转LangChain:深度评估问答系统的三种高效方法(示例生成、手
- 杭州宇树科技有限公司(Hangzhou Yushu Science And Technology Co., Ltd.) [19],简称宇树,是一家从事软件和信息技术服务业民用机器人公司 [19-20]
分享是一种传递,一种快乐
杂学百货铺-啥都学人工智能
UnitreeRoboticsisaworld-renownedcivilianroboticscompany,whichisfocusingontheR&D,production,andsalesofconsumerandindustry-classhigh-performancegeneral-purposeleggedandhumanoidrobots,six-axismanipulator
- 【Autosar】MCAL - 从零开始【干货分享】
蓝白小手套
【Autosar】MCAL-从零开始【干货分享】汽车单片机学习
文章目录MCAL-汇总1.概述2.环境2.1开发环境搭建2.2工程创建2.3参考手册3.驱动(缓慢更新)3.1Microcontroller3.1.1MCU3.1.2WDG3.1.3GPT3.2Memory3.2.1FLS3.2.2I2C3.3Communication3.3.1SPI3.3.2LIN3.3.3CAN3.4I/O3.4.1PORT3.4.2DIO3.4.3ADC3.4.4PWM3.
- 焊接性能分析代码(Python)
骑蜗牛上月亮
python开发语言
welding_performance_data.xls数据文件。welding_strengthtoughness5001052012480855015490953013510115401447075601690018600121500139111578115importpandasaspdimportmatplotlib.pyplotaspltimporttkinterastkfrommatp
- SQL分类
penglaifei
Websql数据库
DDL(DataDefiationLanguage)数据定义语言,用来定义数据库对象(数据库、表、字段)数据库操作——查询所有数据库:show.databases;注:information_schemamysqlperformance_schemasys是系统自带的数据库——查询当前数据库selectdatabase();——使用/切换数据库usename#数据库名;——创建数据库(数据库名不可
- 《Operating System Concepts》阅读笔记:p359-p388
操作系统
《OperatingSystemConcepts》学习第32天,p359-p388总结,总计30页。一、技术总结1.paging(1)定义Acommonmemorymanagementschemethatavoidsexternalfragmentationbysplittingphysicalmemoryintofixed-sizedframesandlogicalmemoryintoblock
- iOS进程增加内存上限的接口
memory
1)iOS进程增加内存上限的接口2).sommap内存占用排查的问题3)在使用RecastNavigation遇到的两个问题这是第420篇UWA技术知识分享的推送,精选了UWA社区的热门话题,涵盖了UWA问答、社区帖子等技术知识点,助力大家更全面地掌握和学习。UWA社区主页:community.uwa4d.comUWAQQ群:793972859MemoryQ:在打iOS包的时候注意到Xcode里有
- 《Operating System Concepts》阅读笔记:p389-p407
操作系统
《OperatingSystemConcepts》学习第33天,p389-p407总结,总计19页。一、技术总结1.virtualmemeory(1)定义Atechniquethatallowstheexecutionofaprocessthatisnotcompletelyinmemory.Also,separationofcomputermemoryaddressspacefromphysic
- 5. MYSQL_存储引擎二多实例安装
q375923078
MYSQL存储引擎slow_loggeneric_logaudit
文章目录一.MyISAM存储引擎(下)1.MyISAM还在使用的原因2.MyISAM文件组成3.myisamchk二.Memory存储引擎1.Memory介绍2.Memory特性3.Memory的物理特性三.CSV存储引擎1.CSV介绍2.CSV文件组成2.CSV特性四.Federated存储引擎1.Federated介绍2.Federated语法五.多实例安装1.多实例介绍2.安装要求3.安装操
- 从零精通机器学习:线性回归入门
吴师兄大模型
0基础实现机器学习入门到精通机器学习线性回归人工智能python算法回归开发语言
Langchain系列文章目录01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南02-玩转LangChainMemory模块:四种记忆类型详解及应用场景全覆盖03-全面掌握LangChain:从核心链条构建到动态任务分配的实战指南04-玩转LangChain:从文档加载到高效问答系统构建的全程实战05-玩转LangChain:深度评估问答系统的三种高效方法(示例生成、手
- C#运算符与表达式:从入门到游戏伤害计算实践
吴师兄大模型
C#编程从入门到进阶c#游戏开发语言运算符表达式变成游戏程序
Langchain系列文章目录01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南02-玩转LangChainMemory模块:四种记忆类型详解及应用场景全覆盖03-全面掌握LangChain:从核心链条构建到动态任务分配的实战指南04-玩转LangChain:从文档加载到高效问答系统构建的全程实战05-玩转LangChain:深度评估问答系统的三种高效方法(示例生成、手
- Spring中@Value注解,需要注意的地方
无量
springbean@Valuexml
Spring 3以后,支持@Value注解的方式获取properties文件中的配置值,简化了读取配置文件的复杂操作
1、在applicationContext.xml文件(或引用文件中)中配置properties文件
<bean id="appProperty"
class="org.springframework.beans.fac
- mongoDB 分片
开窍的石头
mongodb
mongoDB的分片。要mongos查询数据时候 先查询configsvr看数据在那台shard上,configsvr上边放的是metar信息,指的是那条数据在那个片上。由此可以看出mongo在做分片的时候咱们至少要有一个configsvr,和两个以上的shard(片)信息。
第一步启动两台以上的mongo服务
&nb
- OVER(PARTITION BY)函数用法
0624chenhong
oracle
这篇写得很好,引自
http://www.cnblogs.com/lanzi/archive/2010/10/26/1861338.html
OVER(PARTITION BY)函数用法
2010年10月26日
OVER(PARTITION BY)函数介绍
开窗函数 &nb
- Android开发中,ADB server didn't ACK 解决方法
一炮送你回车库
Android开发
首先通知:凡是安装360、豌豆荚、腾讯管家的全部卸载,然后再尝试。
一直没搞明白这个问题咋出现的,但今天看到一个方法,搞定了!原来是豌豆荚占用了 5037 端口导致。
参见原文章:一个豌豆荚引发的血案——关于ADB server didn't ACK的问题
简单来讲,首先将Windows任务进程中的豌豆荚干掉,如果还是不行,再继续按下列步骤排查。
&nb
- canvas中的像素绘制问题
换个号韩国红果果
JavaScriptcanvas
pixl的绘制,1.如果绘制点正处于相邻像素交叉线,绘制x像素的线宽,则从交叉线分别向前向后绘制x/2个像素,如果x/2是整数,则刚好填满x个像素,如果是小数,则先把整数格填满,再去绘制剩下的小数部分,绘制时,是将小数部分的颜色用来除以一个像素的宽度,颜色会变淡。所以要用整数坐标来画的话(即绘制点正处于相邻像素交叉线时),线宽必须是2的整数倍。否则会出现不饱满的像素。
2.如果绘制点为一个像素的
- 编码乱码问题
灵静志远
javajvmjsp编码
1、JVM中单个字符占用的字节长度跟编码方式有关,而默认编码方式又跟平台是一一对应的或说平台决定了默认字符编码方式;2、对于单个字符:ISO-8859-1单字节编码,GBK双字节编码,UTF-8三字节编码;因此中文平台(中文平台默认字符集编码GBK)下一个中文字符占2个字节,而英文平台(英文平台默认字符集编码Cp1252(类似于ISO-8859-1))。
3、getBytes()、getByte
- java 求几个月后的日期
darkranger
calendargetinstance
Date plandate = planDate.toDate();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
Calendar cal = Calendar.getInstance();
cal.setTime(plandate);
// 取得三个月后时间
cal.add(Calendar.M
- 数据库设计的三大范式(通俗易懂)
aijuans
数据库复习
关系数据库中的关系必须满足一定的要求。满足不同程度要求的为不同范式。数据库的设计范式是数据库设计所需要满足的规范。只有理解数据库的设计范式,才能设计出高效率、优雅的数据库,否则可能会设计出错误的数据库.
目前,主要有六种范式:第一范式、第二范式、第三范式、BC范式、第四范式和第五范式。满足最低要求的叫第一范式,简称1NF。在第一范式基础上进一步满足一些要求的为第二范式,简称2NF。其余依此类推。
- 想学工作流怎么入手
atongyeye
jbpm
工作流在工作中变得越来越重要,很多朋友想学工作流却不知如何入手。 很多朋友习惯性的这看一点,那了解一点,既不系统,也容易半途而废。好比学武功,最好的办法是有一本武功秘籍。研究明白,则犹如打通任督二脉。
系统学习工作流,很重要的一本书《JBPM工作流开发指南》。
本人苦苦学习两个月,基本上可以解决大部分流程问题。整理一下学习思路,有兴趣的朋友可以参考下。
1 首先要
- Context和SQLiteOpenHelper创建数据库
百合不是茶
androidContext创建数据库
一直以为安卓数据库的创建就是使用SQLiteOpenHelper创建,但是最近在android的一本书上看到了Context也可以创建数据库,下面我们一起分析这两种方式创建数据库的方式和区别,重点在SQLiteOpenHelper
一:SQLiteOpenHelper创建数据库:
1,SQLi
- 浅谈group by和distinct
bijian1013
oracle数据库group bydistinct
group by和distinct只了去重意义一样,但是group by应用范围更广泛些,如分组汇总或者从聚合函数里筛选数据等。
譬如:统计每id数并且只显示数大于3
select id ,count(id) from ta
- vi opertion
征客丶
macoprationvi
进入 command mode (命令行模式)
按 esc 键
再按 shift + 冒号
注:以下命令中 带 $ 【在命令行模式下进行】,不带 $ 【在非命令行模式下进行】
一、文件操作
1.1、强制退出不保存
$ q!
1.2、保存
$ w
1.3、保存并退出
$ wq
1.4、刷新或重新加载已打开的文件
$ e
二、光标移动
2.1、跳到指定行
数字
- 【Spark十四】深入Spark RDD第三部分RDD基本API
bit1129
spark
对于K/V类型的RDD,如下操作是什么含义?
val rdd = sc.parallelize(List(("A",3),("C",6),("A",1),("B",5))
rdd.reduceByKey(_+_).collect
reduceByKey在这里的操作,是把
- java类加载机制
BlueSkator
java虚拟机
java类加载机制
1.java类加载器的树状结构
引导类加载器
^
|
扩展类加载器
^
|
系统类加载器
java使用代理模式来完成类加载,java的类加载器也有类似于继承的关系,引导类是最顶层的加载器,它是所有类的根加载器,它负责加载java核心库。当一个类加载器接到装载类到虚拟机的请求时,通常会代理给父类加载器,若已经是根加载器了,就自己完成加载。
虚拟机区分一个Cla
- 动态添加文本框
BreakingBad
文本框
<script> var num=1; function AddInput() { var str=""; str+="<input
- 读《研磨设计模式》-代码笔记-单例模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
public class Singleton {
}
/*
* 懒汉模式。注意,getInstance如果在多线程环境中调用,需要加上synchronized,否则存在线程不安全问题
*/
class LazySingleton
- iOS应用打包发布常见问题
chenhbc
iosiOS发布iOS上传iOS打包
这个月公司安排我一个人做iOS客户端开发,由于急着用,我先发布一个版本,由于第一次发布iOS应用,期间出了不少问题,记录于此。
1、使用Application Loader 发布时报错:Communication error.please use diagnostic mode to check connectivity.you need to have outbound acc
- 工作流复杂拓扑结构处理新思路
comsci
设计模式工作算法企业应用OO
我们走的设计路线和国外的产品不太一样,不一样在哪里呢? 国外的流程的设计思路是通过事先定义一整套规则(类似XPDL)来约束和控制流程图的复杂度(我对国外的产品了解不够多,仅仅是在有限的了解程度上面提出这样的看法),从而避免在流程引擎中处理这些复杂的图的问题,而我们却没有通过事先定义这样的复杂的规则来约束和降低用户自定义流程图的灵活性,这样一来,在引擎和流程流转控制这一个层面就会遇到很
- oracle 11g新特性Flashback data archive
daizj
oracle
1. 什么是flashback data archive
Flashback data archive是oracle 11g中引入的一个新特性。Flashback archive是一个新的数据库对象,用于存储一个或多表的历史数据。Flashback archive是一个逻辑对象,概念上类似于表空间。实际上flashback archive可以看作是存储一个或多个表的所有事务变化的逻辑空间。
- 多叉树:2-3-4树
dieslrae
树
平衡树多叉树,每个节点最多有4个子节点和3个数据项,2,3,4的含义是指一个节点可能含有的子节点的个数,效率比红黑树稍差.一般不允许出现重复关键字值.2-3-4树有以下特征:
1、有一个数据项的节点总是有2个子节点(称为2-节点)
2、有两个数据项的节点总是有3个子节点(称为3-节
- C语言学习七动态分配 malloc的使用
dcj3sjt126com
clanguagemalloc
/*
2013年3月15日15:16:24
malloc 就memory(内存) allocate(分配)的缩写
本程序没有实际含义,只是理解使用
*/
# include <stdio.h>
# include <malloc.h>
int main(void)
{
int i = 5; //分配了4个字节 静态分配
int * p
- Objective-C编码规范[译]
dcj3sjt126com
代码规范
原文链接 : The official raywenderlich.com Objective-C style guide
原文作者 : raywenderlich.com Team
译文出自 : raywenderlich.com Objective-C编码规范
译者 : Sam Lau
- 0.性能优化-目录
frank1234
性能优化
从今天开始笔者陆续发表一些性能测试相关的文章,主要是对自己前段时间学习的总结,由于水平有限,性能测试领域很深,本人理解的也比较浅,欢迎各位大咖批评指正。
主要内容包括:
一、性能测试指标
吞吐量、TPS、响应时间、负载、可扩展性、PV、思考时间
http://frank1234.iteye.com/blog/2180305
二、性能测试策略
生产环境相同 基准测试 预热等
htt
- Java父类取得子类传递的泛型参数Class类型
happyqing
java泛型父类子类Class
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import org.junit.Test;
abstract class BaseDao<T> {
public void getType() {
//Class<E> clazz =
- 跟我学SpringMVC目录汇总贴、PDF下载、源码下载
jinnianshilongnian
springMVC
----广告--------------------------------------------------------------
网站核心商详页开发
掌握Java技术,掌握并发/异步工具使用,熟悉spring、ibatis框架;
掌握数据库技术,表设计和索引优化,分库分表/读写分离;
了解缓存技术,熟练使用如Redis/Memcached等主流技术;
了解Ngin
- the HTTP rewrite module requires the PCRE library
流浪鱼
rewrite
./configure: error: the HTTP rewrite module requires the PCRE library.
模块依赖性Nginx需要依赖下面3个包
1. gzip 模块需要 zlib 库 ( 下载: http://www.zlib.net/ )
2. rewrite 模块需要 pcre 库 ( 下载: http://www.pcre.org/ )
3. s
- 第12章 Ajax(中)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Optimize query with Query Stripping in Web Intelligence
blueoxygen
BO
http://wiki.sdn.sap.com/wiki/display/BOBJ/Optimize+query+with+Query+Stripping+in+Web+Intelligence
and a very straightfoward video
http://www.sdn.sap.com/irj/scn/events?rid=/library/uuid/40ec3a0c-936
- Java开发者写SQL时常犯的10个错误
tomcat_oracle
javasql
1、不用PreparedStatements 有意思的是,在JDBC出现了许多年后的今天,这个错误依然出现在博客、论坛和邮件列表中,即便要记住和理解它是一件很简单的事。开发者不使用PreparedStatements的原因可能有如下几个: 他们对PreparedStatements不了解 他们认为使用PreparedStatements太慢了 他们认为写Prepar
- 世纪互联与结盟有感
阿尔萨斯
10月10日,世纪互联与(Foxcon)签约成立合资公司,有感。
全球电子制造业巨头(全球500强企业)与世纪互联共同看好IDC、云计算等业务在中国的增长空间,双方迅速果断出手,在资本层面上达成合作,此举体现了全球电子制造业巨头对世纪互联IDC业务的欣赏与信任,另一方面反映出世纪互联目前良好的运营状况与广阔的发展前景。
众所周知,精于电子产品制造(世界第一),对于世纪互联而言,能够与结盟