Bitwise Operation导语
众所周知计算机是基于二进制01进行运算的,理所当然地,位运算相对于各种算术运算更加贴合计算机的二进制语义,运算效率会更快。这样计算机是舒服了,人类读起来就太生涩了,所以这是把双刃剑。好的代码本身就要Trade Off计算效率性和代码可读性。
我们经常会用移位运算(Bit Shift)比如左移或者右移来分别实现乘法或者除法运算,但是很多人会忽略左移是有可能造成数据越界,必然需要做好程序层面的控制,否则这种BUG太容易被掩盖。下面的章节我会列举一些常见的位运算场景,供大家参考。
基本概念
开始前先把Java位运算的基本概念提一下下:

运算符的优先级:~ 的优先级最高,其次是 <<、>> 和 >>>,再次是&,然后是 ^,优先级最低的是 |。
关于负数的二进制转换,采用的 补码 规则,有兴趣的同学可以研究一下它背后的数学意义。
Linux 权限控制

Linux的日常,无处不见上图中的文件权限,而这个权限控制的原理就是使用的二进制位运算。Linux中的权限有点像三权分立,分别是读、写、执行。
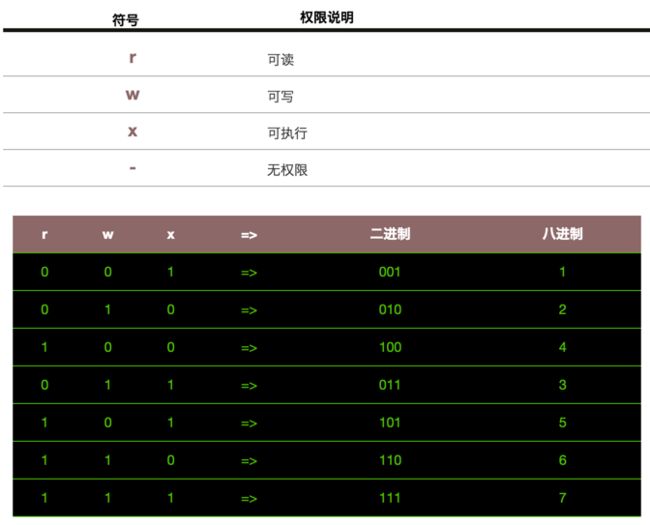
实现原理也很简单,r w x 三个权限分别对应三位的二进制标志位。如下图,“执行X”权限使用二进制为001,即:八进制1。“写入W”权限使用二进制为010,即:八进制2。“读取R”权限使用二进制为100,即:八进制4。
前面提到的三权分立也就是考虑到三者分别在不同的标志位上,相互完全独立。由此展开我们的权限管理ING:
1 添加权限
增加权限使用 或(|) 运算实现。
如,为某用户增加“读取”、“写入”两种权限。
“读写”两种权限,权限码为6(110),本质是由权限码2(010)和4(100)进行或(|)运算后实现,即6 = 2 | 4,当然直观也可以视作基本的算术加 6 = 2 + 4 计算得出。
2 判断权限
在需要判断用户权限时,可使用 与(&) 运算。
如,判断权限码为6用户是否有读取权限。权限码6(110)和4(100)的与运算结果为4,即:4 = 6 & 4。
如,判断权限码为6用户是否有执行权限。权限码6(110)和1(001)的与运算结果为0,即:0 = 6 & 1。
总结下就是,当与运算结果为所要判断权限的本身值时,我们可以认为用户具有这个权限。而当运算结果为 0 时,我们可以认为用户不具有这个权限。
3 移除权限
移除用户的权限可使用 异或(^) 运算。
如,将权限码为7的用户,移除执行权限。权限码7(111)和1(001)的异或运算结果为6,即:6 = 7 ^ 1,也可以由算术减 6 = 7 - 1计算得出。
Linux "umask"命令指定在建立文件时预设的权限掩码,而掩码就是用来移除权限的。比如大部分系统运行umask输出的是“002”或者“0002”, 表示默认去掉了其他用户的写权限。
从上面的介绍可以看出,在基于位运算的权限管理系统中,每种权限码都是唯一的;而且要求每个权限码的二进制数形式,都只能有一位值为1。简单的说,权限码都是2的幂数。
基于位运算的权限管理,优点很明显:运算速度快、效率高、节省存储空间、对权限控制非常灵活。而且扩展性也不错,随时可以扩展新的标志位。除了权限,有些可以组合的业务类型也可以通过这种独立位运算的方式来实现。
BitMask 位掩码
这里我们延展到另一个概念: 位掩码BitMask。Linux权限就是位掩码的一种特例。我们这里再看一种典型的位掩码实现。
搞研发的同学对于fastjson这个阿里巴巴的开源组件应该很熟悉吧? 我们经常会用它来做一些请求/应答数据的序列化和反序列化。在序列化的场景,我们可能会用一些特别的features来满足特定需求,比如:
// 按照类的属性名排序输出
JSON.toJSONString(obj, SerializerFeature.SortField)
// 输出标准格式的日期格式
JSON.toJSONString(obj, SerializerFeature.WriteDateUseDateFormat)
如果需要多种feature组合的话,只要传入一个feature数组即可。那么fastjson如何做到对feature的管理有如Linux权限那般的灵活和可扩展的呢?我们先看下 SerializerFeature 这个枚举类的实现:
public enum SerializerFeature {
QuoteFieldNames,
UseSingleQuotes,
WriteMapNullValue,
IgnoreErrorGetter;
SerializerFeature(){
mask = (1 << ordinal());
}
public final int mask;
public final int getMask() {
return mask;
}
public static boolean isEnabled(int features, SerializerFeature feature) {
return (features & feature.mask) != 0;
}
Java枚举类中的 ordinal() 方法会返回枚举常量的声明顺序,如SerializerFeature.QuoteFieldNames.ordinal()返回 0,以此类推。所以,mask这个掩码会按照枚举常量的顺序进行移位。
也就是每个Feature都会有自己的标志位,以后就算新增一个新的Feature,依序声明即可,原有的变量声明为了保持兼容性顺序尽量不要更改,以防有人直接使用了mask的值进行逻辑判断之类。当然,如果没有暴露接口让调用方直接传入hardcode的mask整型值,新增Feature塞到任何一个位置,理论上也不影响服务升级。
QuoteFieldNames.getMask() = 001(二进制)
UseSingleQuotes.getMask() = 010(二进制)
WriteMapNullValue,getMask() = 100(二进制)
.......
我们再看下 isEnabled() 这个方法,用来判断所有的Features中是否包含某个Feature, 与Linux权限的玩法是不是类似呢?
JSON.toString() 本质上其实就是构造了一个对象 SerializeWriter,而它就会把传入Feature数组运用简单的 或 运算最终合成了一个 int 类型的 features 值。后续对于feature的判断和过滤就和上文的权限大同小异了。
Redis Bitmap
开始前我先抛出一个需求:实时统计当日在线的用户数。你可能会想这个需求太简单啦,redis里面存一个简单的计数器键值对,登入就+1,登出就-1。
真就这么简单么?OK, 再延伸出第二个需求:实时统计近七日内登入过的用户数(活跃数),和近一个月登入过的用户数。若仍旧使用计数器的方式,那就需要 online_users_today, online_users_7days, online_users_30days三个KEY,而且每次用户的登入登出都需要同时维护三个KEY。See, 计数器方案已经暴露出无法扩展的缺点了。
话不多少,我们直接切入Bitmap这个Redis里在某些场景算作“神器”的数据类型。事实上Bitmap(或者官方说的Bit arrays)只是String类型的一种特例,即value是一个类似位的数组,配合特定的Redis指令达到高效位运算的效果。
摘自Redis官方说明:
https://redis.io/topics/data-types-introBit arrays (or simply bitmaps): it is possible, using special commands, to handle String values like an array of bits: you can set and clear individual bits, count all the bits set to 1, find the first set or unset bit, and so forth.
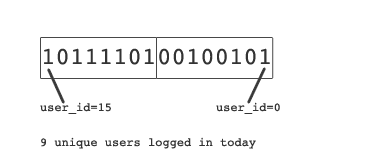
$redis = new Redis();
$redis->connect('127.0.0.1');//设置今日的在线Key
$redisKey = 'online_users_20170707';//用户userId=0登入, 更新Bitmap
$offset = 0;
$redis->setBit($redisKey, $offset, 1);//用户userId=15登入, 更新Bitmap
$offset = 15;
$redis->setBit($redisKey, $offset, 1);//用户userId=7登出, 更新Bitmap
$offset = 7;
$redis->setBit($redisKey, $offset, 0);//计算今日实时在线总人数
echo $redis->bitCount($redisKey)//计算最近7天的总登入人数
//注意: 该统计不需要考虑登出的情况
echo $redis->bitOp('AND', 'online_users', ''online_users_20170701', 'online_users_20170702', 'online_users_20170703','online_users_20170704','online_users_20170705','online_users_20170706','online_users_20170707')echo $redis->bitCount('online_users')
结合图示和伪代码,该需求实现应该是比较容易理解的方案,不再花篇幅说明。使用Bitmap的方案的关键两个要素是如何选择设计redis key和value中的offset。
示例中key选择了天这个维度,value中的offset采用了用户的userId(这个id对应的是数据库中的自增长主键)。然后我们评估下这个方案的占用内存大小:假设我们有1亿用户,那么每日活跃用户数占用内存是 1亿/8 = 12.5M字节,一个月的占用量也就是12.5M*30=375M,这个容量理论上是可以接受的。如果1亿用户里面有不少僵尸用户,即在这12.5M的每日Bitmap数据里0的占比要远远大于1,那你可以key选择用户userId这个维度,value中的offset采用一年中的第几天作为偏移量,读者请自行考虑下如何实现,有何优劣。
BloomFilter 布隆过滤器
Hash哈希函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广。其作用是将一个大的数据集映射到一个小的比如散列表等数据集上面。引用一下吴军博士的《数学之美》中所言,哈希表的空间效率还是不够高。如果用哈希表存储一亿个垃圾邮件地址,每个Email地址对应8bytes, 而哈希表的存储效率一般不超过50%,因此一个Email地址需要占用16bytes. 因此一亿个Email地址占用1.6GB,如果存储几十亿个Email地址则需要上百GB的内存。
所以要引入本节的Bloom Filter。如果想判断一个元素是不是在一个集合里,通常想到的是将通过Iterate集合中的元素通过比较来确定。可以选择List、Map、HashTable等等数据结构。但是如果随着集合中元素的增加,数据量级指数上升,它需要的存储空间也就越来越大,同时检索速度也越来越慢。
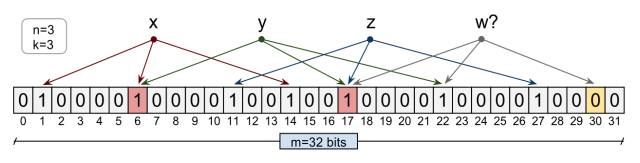
Bloom Filter 是一种空间效率很高的随机数据结构,可以看做是对 Bitmap 的扩展,它只需要哈希表 1/8 到 1/4 的大小就能解决同样的问题。优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
说白了就是原理很简单,用位数组和k个不同的HASH函数。将HASH函数对应的值的位数组置1,查找时如果发现所有HASH函数对应位都是1说明存在。
Bloom Filter一般适用于大数据量的对精确度要求不是100%的去重或者匹配场景。像上面提到的垃圾邮箱过滤(黑名单匹配),敏感词过滤(或者AC自动机),爬虫系统的URL去重(已爬网址去重),网站的UV统计(同一用户去重)。
有趣的位算法
10个老鼠1000个瓶子中找到有毒的
(铺垫:3个老鼠8个瓶子)
https://www.zhihu.com/question/19676641leetcode 位运算算法
数组A中,除了某一个数字X之外,其他数字都出现了三次,而X只出现了一次。请给出最快的方法找到X。(铺垫:其他数字出现两次)
http://blog.csdn.net/morewindows/article/details/12684497
http://blog.csdn.net/morewindows/article/details/8214003常见加解密算法
很有趣的位运算资料分享
《Hacker's Delight》- 各种位运算黑科技
http://www.hackersdelight.org/
《你可曾听过位运算的天籁》- "听见"位运算
https://zhuanlan.zhihu.com/p/24912672
本文篇幅有限,不可能穷举出所有的位运算场景,但已经是本人目前脑子里最近可以巴拉出来的大部分应用场景了。如有您有其它更好的场景说明,可留言给我。