1.大数据概述
大数据是指无法利用传统计算技术进行处理的大规模数据集合。大数据概念不再只是数据,大数据已经成为一个全面的主题概念,包含各类工具、技术以及框架。
大数据包括各类信息设备以及应用程序所产生的数据。大数据所涵盖的一些数据领域如下:
黑盒子数据:是指直升机、普通飞机及喷气式飞机等的组成部分。该数据采集了飞行机组人员的声音、麦克风和耳机的录音以及飞机的性能信息。
社交媒体数据:社交媒体诸如Facebook和Twitter,拥有人们发布的信息和观点。
证券交易数据:证券交易数据包括不同公司客户做出的“买入”和“卖出”决策信息。
电网数据:电网数据是指一个特定节点相对于基站的耗电信息。
搜索引擎数据:搜索引擎从不同数据库中抽取的大规模数据。
因此,大数据包括巨大规模、超高速度、类型可扩展的数据。大数据包括三种类型的数据:
结构化数据:关系型数据。
半结构化数据:XML数据。
非结构化数据:Word文档、PDF文档、文本、媒体日志。
2.大数据技术
大数据技术对于提供更精确分析是非常重要的。更精确地分析将会导致更具体地决策,从而大大提高工作效率、降低成本,减少业务风险。
要充分利用大数据,就需要一个基础架构,能够实时管理和处理大规模结构化、非结构化数据,并能够保障数据隐私和安全。
市场上存在有不同公司提供的技术,用来处理大数据。下面介绍其中的两类技术:
(1)运营大数据
这类技术产品,如MongoDB,针对已采集和存储的数据,提供实时管理、交互式处理功能。
NoSQL大数据系统,充分利用过去十年流行的新型云计算架构,支持大规模计算,提供高效、廉价的计算能力。基于这种方案,大数据管理的实施工作更容易、更便宜、更快速。
一些NoSQL系统能够支持模式识别、实时数据处理,就不再需要数据专家和其他基础架构的支持。
(2)分析大数据
这类技术产品包括大规模并行处理(MPP)数据库系统和MapReduce,提供支持回溯和复杂分析的分析功能,可能会涉及到绝大多数数据。
MapReduce提供一种新型的数据分析方式,与SQL数据分析能力互补。基于MapReduce的系统能够实现扩充,从单一服务器扩充到成千上万台不同等级的终端机器。
3.大数据解决方案
3.1 传统方案
在该方案中,企业单位利用一台计算机来存储和处理大数据。数据被保存在一个关系型数据库(RDBMS)系统中,诸如Oracle数据库、MS SQL Server或者DB2;同时,还需要编写复杂软件与这些数据库进行交互,处理所需数据,并向用户展示数据,以及数据分析。

该方案存在一定的限制。当所拥有数据规模不大,能够被标准数据库服务器处理时,该方案能够运行良好。但是,当面对超大规模数据时,传统数据库服务器将难以处理。
3.2 Google方案
Google利用MapReduce算法来处理大数据。该算法把大数据分解为很多、很小的部分,并把这些部分分派给网络相连的计算机进行处理,之后收集处理结果,汇总形成最终结果数据集。
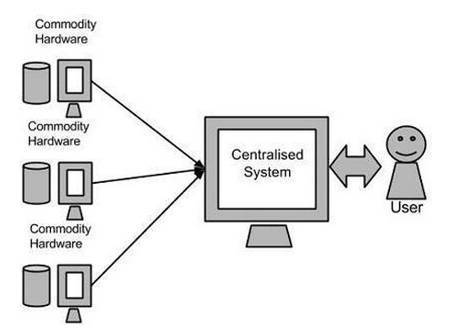
上图展示了基于硬件产品的解决方案示意图,这些硬件产品可能是单一CPU的机器或者是功能更强大的服务器。
3.3 Hadoop
2005年,Doug Cutting、Mike Cafarella及其团队,基于Google方案,开始设计研发一种开放式源代码项目,名为HADOOP。Hadoop利用MapReduce算法来运行程序,以并行处理方式在不同CPU节点上处理数据。总之,Hadoop框架能够研发基于计算机集群运行的应用程序;并能够针对大规模数据进行全部统计分析。
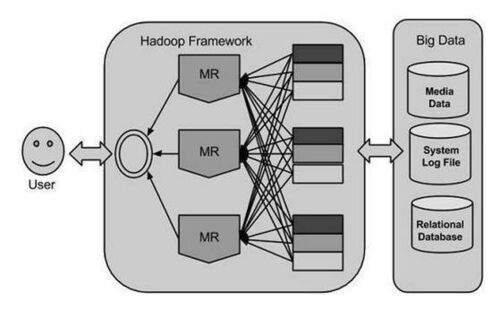
4.Hadoop介绍
Hadoop是基于JAVA语言开发的Apache开源框架,支持跨计算机集群的大规模数据集的分布式处理。基于Hadoop框架的应用程序,能够支持跨计算机集群的分布式存储和计算。Hadoop框架设计旨在从单一服务器扩展到上千台机器,每一台机器能够提供本地计算和存储。
4.1 Hadoop架构
Hadoop框架包括以下四个模块:
Hadoop通用:这些模块是其他Hadoop模块所需要的Java类库和工具。这些类库提供文件系统和操作系统级别的抽象,包含启动Hadoop必须的Java文件和脚本。
Hadoop YARN:这是一个用于任务排班和集群资源管理的框架。
Hadoop分布式文件系统(HDFS):一个分布式文件系统,提供高吞吐量的应用程序数据访问方式。
Hadoop MapReduce:这是一个基于YARN的系统,用于大规模数据集的并行处理。
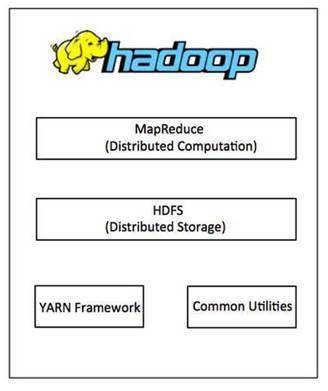
自2012年以来,术语“Hadoop”不仅仅是指以上介绍的基础模块,还包括基于Hadoop或者与Hadoop一起安装的附加软件包,诸如Apache Pig, Apache Hive, Apache HBase, Apache Spark等。
4.2 MapReduce
Hadoop MapReduce是一个易于编写程序的软件框架,基于大型硬件集群(上千个节点)、以并行方式处理大规模数据,并确保系统拥有高可靠性和容错性。
术语MapReduce实际是指以下Hadoop程序运行的两项不同任务:
映射任务/Map Task:这是首要任务,把输入数据转换成一系列数据,把个体元素分解为元组(键/值对)。
缩减任务/Reduce:该任务把映射任务的输出数据作为输入,把这些数据元组合并为更小的元组集合。缩减任务总是在映射任务之后执行。
通常情况下,输入和输出数据都存储在一个文件系统中。该框架负责任务调度,监控任务,并重新运行失败任务。
MapReduce框架由每个集群节点的一个单一主控JobTracker和一个从属TaskTracker构成。主控JobTracker负责资源管理,跟踪资源消耗/可用性,调度从属TaskTracker上的作业组件任务,监控这些任务,并重新运行失败任务。从属TaskTracker按照主控JobTracker的指示执行任务,并定期向主控JobTracker提供任务状态信息。
4.3 Hadoop分布式文件系统
Hadoop可以直接与任何可安装的分布式文件系统一起工作,诸如Local FS、HFTP FS、S3 FS,还有其他文件系统,但是Hadoop经常使用的还是Hadoop分布式文件系统(HDFS)。
Hadoop分布式文件系统(HDFS)是基于Google文件系统(GFS)构建的,并提供一种分布式文件系统,旨在以可靠、容错的方式,在小型机的大规模集群(数千台计算机)上运行。
HDFS是一个主/从架构,主控服务器包括一个单一命名节点(NameNode),用来管理文件系统元数据;一个或多个从属数据节点(DataNodes)存储实际数据。
HDFS命名空间中的一个文件将会被拆分成几个区块(Block),这些区块被存储到一组数据节点(DataNodes)中。命名节点(NameNode)决定着这些区块和数据节点之间的映射关系。数据节点(DataNode)负责文件系统的读取操作。数据节点(DataNodes)还要基于命名节点(NameNode)给定的指令来处理区块的创建、删除和复制。
HDFS提供了一个类似其他文件系统的内核(shell)以及一个命令清单,可用于与文件系统的交互。
4.4 Hadoop如何工作
第一阶段:一个用户/应用程序能够提交一项作业给Hadoop(hadoop作业客户端),需要指定以下条目进行后续处理。
(1)分布式系统中输入和输出文件的位置。
(2)以jar文件形式存在的java类,包含映射(Map)和缩减(Reduce)功能的实现。
(3)通过设定不同的作业参数来进行作业配置。
第二阶段:接着,Hadoop作业客户端提交一个作业(jar/可执行文件等)和配置给JobTracker。然后,JobTracker负责将软件/配置分发给从属服务器、调度任务,并进行监控,向作业客户端提供状态和运行诊断信息。
第三阶段:不同节点上的TaskTracker根据每一个MapReduce的实现运行任务,减量功能的输出被存储到文件系统的输出文件中。
4.5 Hadoop的优势
Hadoop框架允许用户快速编写和测试分布式系统。该框架是高效的,在计算机之间自动分布数据和工作,利用CPU内核的底层并行机制。
Hadoop不依赖于硬件来提供容错和高可用性(FTHA),相反,Hadoop库本身的设计就是用于在应用层级探测和处理故障的发生。能够动态地向集群添加服务器、或者从集群中删除服务器,Hadoop持续运行状态不会被打断。
Hadoop另一个大优势是,除了开源之外,由于是基于Java技术研发的,所以对于所有平台都兼容。