哪里描述不正确望指正. 欢迎转载
大纲
| 知识点 | 概括 |
|---|---|
ByteBuf的数据模型 |
描述ByteBuf基本概念 |
来自不同地区的ByteBuf |
介绍存储在不同内存区域的ByteBuf及其优缺点 |
byte级别的操作 |
ByteBuf基本的读写查操作 |
派生ByteBuf |
为ByetBuf创建不同类型的副本 |
多种方式分配ByteBuf |
介绍池化/非池化ByteBuf以及如何分配池化/非池化的ByteBuf |
释放ByteBuf |
基于引用计数, 释放资源 |
数据容器的选择
- Java NIO使用
ByteBuffer.class- Netty使用
ByteBuf.class
Netty官方声称ByteBuf比ByteBuffer更加方便使用
- 读和写使用了不同的索引(读写模式切换不需要调用
ByteBuffer::filp方法) - 支持方法的链式调用
- 支持引用计数(释放ByteBuf资源)
- 支持池化(避免冗余)
- 可以被用户自定义的缓冲区类型扩展
- 通过内置的复合缓冲区类型实现了透明的零拷贝
- 容量可以按需增长
ByteBuf的数据模型

与NIO
ByteBuffer不同的是Netty
ByteBuf维护了两个索引
-
readerIndex
调用read*()方法时,index+
调用get*()方法时,index不变 -
writerIndex
调用write*()方法时,index+
调用set*()方法时,index不变
调用skip*()方法时,index+
index的变化只与read*()和write*()和skip*()方法有关
来自不同地区的ByteBuf
- 堆缓冲区
将数据存储在 JVM 的堆空间中, 该模式被称为支撑数组(backing array), 最常用.
- 优点
能在没有使用池化的情况下提供快速的分配和释放(在堆上直接调用JAVA的API, 不用调用操作系统的接口)- 缺点
传输时, 会先拷贝到直接缓冲区
声明一个支撑数组
ByteBuf buf = new UnpooledHeapByteBuf(ByteBufAllocator.DEFAULT, initalCapacity, maxCapacity);
//默认capacity是256
ByteBuf buf = Unpooled.buffer(capacity);
//建议池化方式创建, 下文将讲到如何分配ByteBuf
判断ByteBuf是否在JVM heap中, 并处理数组
ByteBuf heapBuf = Unpooled.copiedBuffer("Hello Netty", CharsetUtil.UTF_8);
if (heapBuf.hasArray()) { //检查支撑数组(true)
byte[] array = heapBuf.array();
handleArray(array);//处理
}
如果ByteBuf::hasArray返回false时再次访问ByteBuf::array则抛出异常UnsupportedOperationException
调用ByteBuf::array之前总是要判断ByteBuf::hasArray
- 直接缓冲区
通过本地调用来为
ByteBuf分配内存(非JVM heap)
- 优点
直接缓冲区对于网络数据传输是理想的选择, 传输时ByteBuf不用经过中间缓存区- 缺点
分配和释放代价大(调用操作系统API), 下文中池化的缓冲区可以缓解这个缺点
声明一个直接缓冲区数组
ByteBuf buf = new UnpooledDirectByteBuf(ByteBufAllocator.DEFAULT, initialCapacity, maxCapacity);
//默认capacity是256
ByteBuf buf = Unpooled.directBuffer(capacity);
//建议池化方式创建, 下文将讲到如何分配ByteBuf
直接缓冲区的用法ByteBuf就如同其名字, 可以直接传输(无需经过中间缓存区)
- 复合缓冲区
聚合多个
ByteBuf, Netty 通过一个ByteBuf.class子类——CompositeByteBuf.class——实现了这个模式,将多个ByteBuf聚合在一起提供统一操作
CompositeByteBuf中可能同时存在直接内存分配和非直接内存分配. 如果只有一个ByteBuf则调用CompositeByteBuf::hasArray时相当于调用ByteBuf::hasArray, 否则存在多个实例时, 调用CompositeByteBuf::hasArray时直接返回falseCompositeByteBuf.class内部维护了一个arrayList用来存放ByteBuf
使用场景
Http请求由header和(1或n个)content组成, 我们可以将header
ByteBuf和contentByteBuf聚合为一个CompositeByteBuf
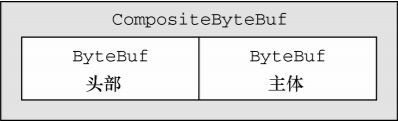 image.png
image.png
构建我们的Http请求主体
class HttpMessage{
//聚合器
CompositeByteBuf message;
//使用不同内存模型的ByteBuf
ByteBuf header;
ByteBuf content;
public HttpMessage(){
message = Unpooled.compositeBuffer();
header = Unpooled.directBuffer();
content = Unpooled.buffer();
//聚合
message.addComponents(header, content);
//也可以移除
//message.removeComponent(0);
}
}
访问我们的聚合器
//循环遍历每个component
message.forEach(byteBuf -> System.out.println(byteBuf.toString(CharsetUtil.UTF_8)));
//逐个获取component
ByteBuf header2 = message.component(0);
ByteBuf content2 = message.component(1);
//处理消息
handle(header2, content2);
//...
byte级别的操作
在高并发项目开发中, 如果能让我们灵活地操作字节(分配和释放), 系统性能和吞吐量将会有所提升
- 随机读写
ByteBuf::getByte(int)读取任意位置的字节
ByteBuf::setByte(int)写入任意位置的字节 - 顺序读写
由于
ByteBuf有两个索引, 所以一个ByteBuf的数据可被两个索引拆分为三个部分, 对应顺序访问中三个重要的概念
- 可丢弃字节
- 可读字节
- 可写字节
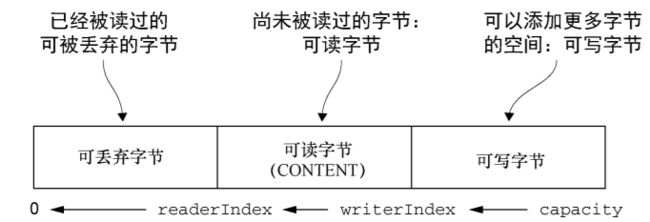 image.png
image.png
丢弃可丢弃字节, 通过调用ByteBuf::discardReadBytes方法, readerIndex会变为0, writerIndex会减少, 从而将可丢弃字节抛弃, 不过这会导致内存复制, 因为要把readerIndex到writerIndex之间的内容往左移动. 这里要注意的是writerIndex到capacity之间的数据不会移动也不会改变, 除非ByteBuf容量很紧凑, 否则应该少用该方法
read*()和skip*()方法会增加当前readerIndex. 注意特例readBytes(ByteBuf dest)方法(将读取的byte写入dest)会增加当前ByteBuf的readerIndex也会增加dest的writerIndex, 但readBytes(ByteBuf dest, int dstIndex, int length )不会改变dest的writerIndex, 因为指定了下标参数(具体请查看netty官方文档)
同上, writeBytes(ByteBuf dest)如果没有自定下标参数, 同样会增加dest的writerIndex
ByteBuf提供了一系列的字节级别读写, 举个简单的例子
readByte: 读取1个byte 然后 readerIndex+1
readInt: 读取4个byte 然后readerIndex+4
writeByte:写入1个byte 然后 writerIndex+1
writeInt:写入4个byte 然后 writerIndex+4
注意: 为了养成一个好的习惯, 读写时要随时注意ByteBuf::readableBytes和ByteBuf::writableBytes是否大于0, 否则抛出IndexOutOfBoundException
- 管理索引(
readerIndex,writerIndex)
在操作
ByteBuf的时候, 可能需要暂时存下当前索引的位置, 稍后返回该索引位置. 或者需要根据协议自定义跳转到指定索引位置
- 保存和重置索引:
ByteBuf::markReaderIndex和ByteBuf::resetReaderIndex, 同理有ByteBuf::markWriterIndex和ByteBuf::resetWriterIndex - 将索引移动到指定位置:
ByteBuf::readerIndex和ByteBuf::writerIndex(都接收int参数) - 清空
ByteBuf:ByteBuf::clear(注意此方法不是将内容删除,而是将readerIndex和writerIndex重置为0)
- 查找
简单查找:
ByteBuf::indexOf, 接收一个byte参数, 返回第一个出现的index
高级查找:
已经在新版本中被弃用, 所以这里只关注ByteBufProcessorByteProcessor
ByteBufProcessor接口定义了多个常量并且内部有两个实现类IndexOfProcessor和IndexNotOfProcessor
IndexOfProcessor用来查找第一个出现的字符下标, IndexNotOfProcessor用来查找第一个不一样的字符下标.
为了区分上面两个类的作用, 简单举个例子:
假设我们有ByteBuf内容: Netty
//找出'N'出现的第一个下标
int indexOf = buf.forEachByte(new ByteProcessor.IndexOfProcessor((byte)'N'));
上面语句的结果: indexOf = 0
//找出第一个不是'N'的下标
int indexNotOf = buf.forEachByte(new ByteProcessor.IndexNotOfProcessor(((byte) 'N')));
上面语句的结果: indexNotOf = 1
ByteBufProcessor还定义了一些常量, 下面简单地示范
//查找 LF ('\n')
buf.forEachByte(ByteProcessor.FIND_LF);
派生ByteBuf
以下方法用来获取
ByteBuf的一个新实例, 这些实例拥有自己独立的索引(标记和读写指针), 但数据内容共享(同一个引用)
-
ByteBuf::duplicate返回所有内容 -
Bytebuf::slice返回readerIndex至writerIndex之间的内容 Bytebuf::slice(int, int)ByteBuf::orderUnpooled::unmodifiableBuffer
如果要生成一个数据独立的副本, 使用
ByteBuf::copy
另外一种派生
ByteBuf的方式是ByteBufHolder. 每个ByteBufHolder维护一个ByteBuf, 我们可以将ByteBufHolder看作一个池, 用户可以向ByteBufHolder借用ByteBuf, 并在没用的时候释放. 关于ByteBufHolder的实际用途, 本人目前尚未了解清楚, 希望了解的读者可以向我反馈
多种方式分配ByteBuf
什么是池化/非池化的
ByteBuf?
Netty预先向操作系统申请一块内存, 用来存放池化的数据, 当我们创建一个池化的ByteBuf时, 一般不会创建新的ByteBuf, 而是复用了之前创建好的, 当我们的ByteBuf使用完, 释放完之后,ByteBuf不会被销毁, 而是被Netty放回了池中, 等待下一个请求, 继续分配这个ByteBuf, 这就是池化的ByteBuf
而非池化的ByteBuf, 每次被请求时, 都会创建新的, 被释放时, 对象都会被销毁为什么要使用池化的
ByteBuf?
池化ByteBuf是为了避免创建/销毁ByteBuf造成的开销, 在许多Netty应用中, 一个请求所生成的ByteBuf在逻辑上是转瞬即逝的, 请求返回之后, 这些数据就成了GC回收的目标, 如果没有及时清理, 那么内存将会无限增加(Netty太快了).
下面介绍两种分配ByteBuf的途径, 通过获取到的分配器, 我们就可以根据需求分配池化/非池化的ByteBuf
-
ByteBufAllocator
一般从Channel::alloc或者ChannelHandlerContext::alloc中获取
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc();
....
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator2 = ctx.alloc();
...
ByteBufAllocator提供了一系列方法, 可以用来创建来自不同地区的ByteBuf, 基于堆内存, 基于直接内存, 聚合器, 还有阻塞型(I/O)的ByteBuf
ByteBufAllocator有两个实现类PooledByteBufAllocator和UnpooledByteBufAllocator
PooledByteBufAllocator池化了ByteBuf以用来减少内存碎片, 提高性能
UnpooledByteBufAllocator创建的ByteBuf都是一个新实例
- Netty默认使用了池化的
Allocator, 但我们可以在引导中自定使用池化还是非池化分配器
-
Unpooled
当无法在Channel或者ChannelHandlerContext获取ByteBufAllocator时, 推荐使用Unpooled(静态工具类)来创建未池化的ByteBuf
释放ByteBuf
- 引用计数
Netty在第4版中为
ByteBuf和ByteBufHolder引入了引用计数技术, 它们都实现了ReferenceCounted接口
当一个对象所持有的资源被多个对象引用, 假设引用计数为n, 每个对象释放引用之后, 引用计数减1, 当引用计数等于0时, 说明对象已经没有用途, 对象持有的资源会被释放.
- 释放引用
realease()