工作中对于列表的输出最常用到是List,有时候也不免要用到Map,罗列一下一些心得和体会。
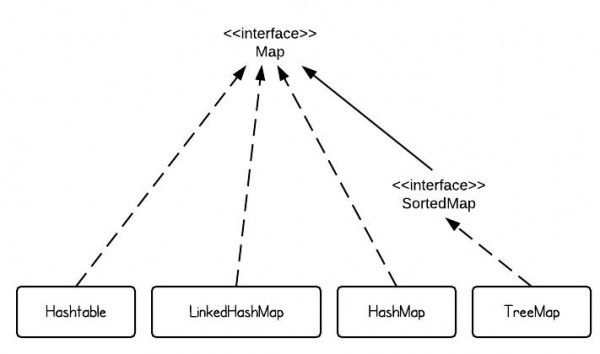
1. Map HashMap LinkedHashMap TreeMap Hashtable
HashMap和LinkedHashMap都是实现Map接口,功能上近乎是一样的,最大的区别在于HashMap并不是按插入次序顺序存放的,其中元素的顺序有可能是完全打乱的,TreeMap 则是依据key的compareTo()方法或者一个外部Comparator 确定的自然排序存放的。LinkedHashMap是依据元素put的顺序存放的。
“Hashtable”是所有基于散列映射的结构的通用名称。在Java API的情况下,Hashtable是从Java1.1的collections 集合框架之前存在一个过时的类。它不应该再被使用,因为它的API被堆满了过时的方法和重复的功能,其方法是synchronized 的(这会降低性能,并且通常无用的)。在需要同步操作的时候用ConcurrrentHashMap替代。
All three classes implement the Map interface and offer mostly the same functionality. The most important difference is the order in which iteration through the entries will happen:
HashMap makes absolutely no guarantees about the iteration order. It can (and will) even change completely when new elements are added.
TreeMap will iterate according to the "natural ordering" of the keys according to their compareTo() method (or an externally supplied Comparator). Additionally, it implements the SortedMap interface, which contains methods that depend on this sort order.
LinkedHashMap will iterate in the order in which the entries were put into the map.
"Hashtable" is the generic name for hash-based maps. In the context of the Java API, Hashtable is an obsolete class from the days of Java 1.1 before the collections framework existed. It should not be used anymore, because its API is cluttered with obsolete methods that duplicate functionality, and its methods are synchronized (which can decrease performance and is generally useless). Use ConcurrrentHashMapinstead of Hashtable.

2. List ArrayList LinkedList Vector
LinkedList and ArrayList 是List的两种完全不同实现,LinkedList 是通过一个双向列表,而ArrayList 是通过一个可动态扩展的数组实现的。也正是由于基于链表和数组之间不同的操作,它们之间的很多方法拥有不同的算法执行时间。
LinkedList and ArrayList are two different implementations of the List interface. LinkedList implements it with a doubly-linked list. ArrayList implements it with a dynamically resizing array.
As with standard linked list and array operations, the various methods will have different algorithmic runtimes.
For LinkedList
get(int index) is O(n)add(E element) is O(1)add(int index, E element) is O(n)remove(int index) is O(n)Iterator.remove() is O(1) <--- main benefit of LinkedList
For ArrayList
get(int index) is O(1) <--- main benefit of ArrayList
LinkedList
ArrayList
So depending on the operations you intend to do, you should choose the implementations accordingly. Iterating over either kind of List is practically equally cheap. (Iterating over an ArrayList is technically faster, but unless you're doing something really performance-sensitive, you shouldn't worry about this -- they're both constants.)
The main benefits of using a LinkedList arise when you re-use existing iterators to insert and remove elements. These operations can then be done in O(1) by changing the list locally only. In an array list, the remainder of the array needs to be moved (i.e. copied). On the other side, seeking in a LinkedList means following the links in O(n), whereas in an ArrayList the desired position can be computed mathematically and accessed in O(1).
Also, if you have large lists, keep in mind that memory usage is also different. Each element of a LinkedList has more overhead since pointers to the next and previous elements are also stored. ArrayLists don't have this overhead. However, ArrayLists take up as much memory as is allocated for the capacity, regardless of whether elements have actually been added.
The default initial capacity of an ArrayList is pretty small (10 from Java 1.4 - 1.7). But since the underlying implementation is an array, the array must be resized if you add a lot of elements. To avoid the high cost of resizing when you know you're going to add a lot of elements, construct the ArrayList with a higher initial capacity.
It's worth noting that Vector also implements the List interface and is almost identical to ArrayList. The difference is that Vector is synchronized, so it is thread-safe. Because of this, it is also slightly slower than ArrayList. So as far as I understand, most Java programmers avoid Vector in favor of ArrayList since they will probably synchronize explicitly anyway if they care about that.
3. Set HashSet Treeset LinkedHashSet
HashSet is much faster than TreeSet (constant-time versus log-time for most operations like add, remove and contains) but offers no ordering guarantees like TreeSet.
HashSet:
class offers constant time performance for the basic operations (add, remove, contains and size).it does not guarantee that the order of elements will remain constant over time iteration performance depends on the initial capacity and the load factor of the HashSet. It's quite safe to accept default load factor but you may want to specify an initial capacity that's about twice the size to which you expect the set to grow.
TreeSet:
guarantees log(n) time cost for the basic operations (add, remove and contains)guarantees that elements of set will be sorted (ascending, natural, or the one specified by you via it's constructor)doesn't offer any tuning parameters for iteration performance offers a few handy methods to deal with the ordered set like first(), last(), headSet(), and tailSet() etc
Important points:
Both guarantee duplicate-free collection of elementsIt is generally faster to add elements to the HashSet and then convert the collection to a TreeSet for a duplicate-free sorted traversal.None of these implementation are synchronized. That is if multiple threads access a set concurrently, and at least one of the threads modifies the set, it must be synchronized externally.LinkedHashSet is in some sense intermediate between HashSet and TreeSet. Implemented as a hash table with a linked list running through it, however it provides insertion-ordered iteration which is not same as sorted traversal guaranteed by TreeSet.
So choice of usage depends entirely on your needs but I feel that even if you need an ordered collection then you should still prefer HashSet to create the Set and then convert it into TreeSet.
e.g. Set