一、Fast R-CNN原理
在SPPNet中,实际上特征提取和区域分类两个步骤还是分离的。只是使用ROI池化层提取了每个区域的特征,在对这些区域分类时,还是使用传统的SVM作为分类器。Fast R-CNN相比SPPNet更进一步,不再使用SVM作为分类器,而是使用神经网络进行分类,这样就可以同时训练特征提取网络和分类网络,从而取得比SPPNet更高的准确度。Fast R-CNN的网络结构如下图所示
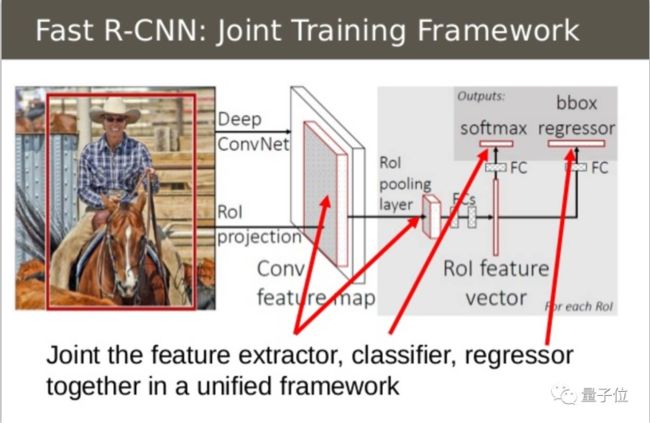
对于原始图片中的候选框区域,和SPPNet中的做法一样,都是将它映射到卷积特征的对应区域,即上图中的ROI projection,然后使用ROI池化层对该区域提取特征。在这之后,SPPNet是使用SVM对特征进行分类,而Fast R-CNN则是直接使用全连接层。全连接层有两个输出,一个输出负责分类,即上图中的softmax,另一个输出负责框回归,即上图中的bbox regressor。
先说分类,假设要在图像上检测K类物体,那么最终的输出应该是K+1个数,每个数都代表该区域为某个类别的概率。之所以是K+1个输出而不是K个输出,是因为还需要一类“背景类”,针对该区域无目标物体的情况。
再说框回归,框回归实际上要做的是对原始的检测框进行某种程度的“校准”。因为使用Selective Search获得的框有时存在一定偏差。设通过Selective Search得到的框的四个参数为(x,y,w,h),其中(x,y)表示框左上角的位置,而(w,h)表示框的宽度和高度。而真正的框的位置用(x',y',w',h')表示,框回归就是要学习参数[(x'-x)/w,(y'-y)/h,ln(w'/w),ln(h'/h)]其中(x'-x)/w,(y'-y)/h两个数表示与尺度无关的平移量,而ln(w'/w), ln(h'/h)两个数表示的是和尺度无关的缩放量。
Fast R-CNN 与SPPNet最大的区别就在于,Fast R-CNN不再使用SVM进行分类,而是使用一个网络同时完成了提取特征,判别类别和框回归三项任务。
二、Faster R-CNN原理
Fast R-CNN看似很完美了,但在Fast R-CNN中还存在着一个有点尴尬的问题:它需要先使用Selective Search提取框,这个方法比较慢,同时,检测一张图片,大部分时间不是花在计算神经网络分类上,而是花在Selective Search提取框上!在Fast R-CNN的升级版Faster R-CNN中,用RPN网络(Region Proposal Network)取代了Selective Search,不仅速度得到大大提高,而且还获得了更加精确的结果。
RPN网络的结构如下图所示

RPN还是需要先使用一个CNN网络对原始图片提取特征。为了方便读者理解,不妨设这个前置的CNN提取的特征为51x39x256,即高为51、宽为39、通道数为256。对这个卷积特征再进行一次卷积计算,保持宽、高、通道不变,再次得到一个51x39x256的特征。为了方便叙述,先来定义一个“位置”的概念:对于一个51x39x256的卷积特征,称它一共有51x39个“位置”。让新的卷积特征的每一个“位置”都“负责”原图中对应位置9种尺寸框的检测,检测的目标是判断框中是否存在这样一个物体,因此共有51x39x9个“框”。在Faster R-CNN的原论文中,将这些框都统一称为“anchor”。
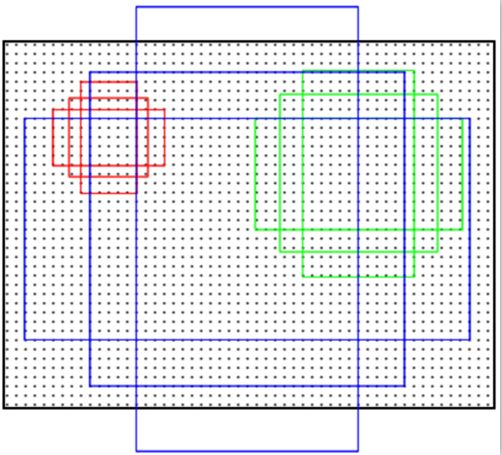
anchor的9种尺寸如下图所示,它们面积分别是1282,2562,5122。每个面积又分为3种长宽比,分别2:1、1:2、1:1。anchor的尺寸实际是属于可调的参数,不同任务可以选择不同的尺寸。
对于这51x39个位置和51x39x9个anchor,下面这张图展示了接下来每个位置的计算步骤。设k为单个位置对应的anchor的个数,此时k=9。首先使用一个3x3的滑动窗口,将每个位置转换为一个统一的256维的特征,这个特征对应了两部分的输出。一部分表示该位置的anchor为物体的概率,这部分的总输出长度为2xk(一个anchor对应两个输出:是物体的概率+不是物体的概率)。另一部分为框回归,框回归的含义与Fast R-CNN中一样,一个anchor对应4个框回归参数,因此框回归部分的总输出的长度为4xk。

Faster R-CNN使用RPN生成候选框后,剩下的网络结构和Fast R-CNN中的结构一模一样。在训练过程中,需要训练两个网络,一个是RPN网络,一个是在得到框之后使用的分类网络。通常的做法是交替训练,即在一个batch内,先训练RPN网络,再训练分类网络一次。
R-CNN、Fast R-CNN、Faster R-CNN的对比如下表所示

从R-CNN,到Fast R-CNN,再到Faster R-CNN,不仅检测速度越来越快,而且检测的精确度也在不断提升。在出现R-CNN方法前,VOC2007数据集上传统方法所能达到的最高平均精确度(mAP)为40%左右,R-CNN将该值提高到了58.5%,Fast R-CNN在VOC2007上的平均准确度为70%,Faster R-CNN又将该值提高到了78.8%。这几种方法既一脉相承,又不断改进,值得仔细研究。