前言:
最近在不定时的出差后,小编总结出来一个问题,自从2013年大数据火起来之后,到现在也经历了6年多,有些公司已经逐步废弃传统的关系型数据库,逐渐引入大数据平台,有些公司可能已经通过大数据平台从百亿基本数据中找到的其真正的价值,但是这个过程总是缓慢的,总要经历:数据的迁移、数仓的建设、基于数仓的上层开发、基于业务的报表分析...尤其是在数据的迁移的过程中,不同的项目根据需求不同会选择适合自己的数据库,从而导致,在将数据迁移到大数据平台上时多种多样的数据迁移方式,小编经历过的就有MySQL、DB2、PostgreSQL、Oracle,像这些数据库都是有直接的JDBC的驱动包,一般通过数据迁移工具sqoop或者一些ETL工具直接可以将数据抽取过来,但是也有些并非有JDBC的驱动包,有些数据迁移工具也并不支持的数据库;比如接下来小编要介绍的InfluxDB,他就是一个时序数据库,而且并没有相应比较好用的工具去抽取数据。只能先了解其原理,然后自己想办法,如何高效、简单的实现数据的迁移。
数据迁移总是一个头疼的问题,这里小编建议,先根据自己的业务和需求,在迁移数据之前,设计出适合各种场景的表,千万不要盲目的把数据迁移过来,之后再改表类型以及结构,否则后期的维护成本就相当高。好了,废话不多说了,以上是小编的一点愚见,接下来开始学习这个InfluxDB时序数据库!
一、InfluxDB 介绍
1. InfluxDB简介
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。 与 Elasticsearch 有些类似。
功能:
- 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等);
- 可度量性:你可以实时对大量数据进行计算;
- 基于事件:它支持任意的事件数据基于事件:它支持任意的事件数据。
主要特点:
- 无结构(无模式):可以是任意数量的列
- 可拓展的,支持min, max, sum, count, mean, median 等一系列函数,方便统计支持min, max, sum, count, mean, median 等一系列函数,方便统计
- 原生的HTTP支持,内置HTTP API原生的HTTP支持,内置HTTP API
- 强大的类SQL语法强大的类SQL语法
- 自带管理界面,方便使用自带管理界面,方便使用
InfluxDB与传统数据库的比较:
2. InfluxDB独有的概念
接下来通过一个insert操作,展开对InfluxDB独有概念的介绍,在 InfluxDB 中,我们可以粗略的将要存入的一条数据看作一个虚拟的 key 和其对应的 value(field value),格式如下:
insert cpu_usage,host=server01,region=us-west value=0.64 1434055562000000000`虚拟的 key 包括以下几个部分: database, retention policy, measurement, tag sets, field name, timestamp。
- database:数据库名,在 在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的 。
- retention policy : 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置
- measurement :类似于关系型数据库中的表。
- tag sets : tags 在 InfluxDB 中会按照字典序排序 ,例如: host=server01,region=us-west 和 host=server02,region=us-west 就是两个不同的 tag set 。
- tag :标签, 在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引,是“key-value”的形式 。
- ield name: 例如上面数据中的 value 就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName 。
- timestamp : 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作 。
(1)Point
Point 由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据 , 如下表所示: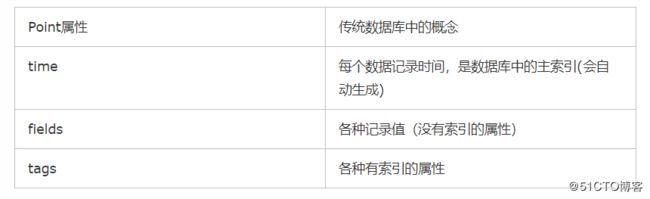
(2) Series
Series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
(3) Shard
Shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复 ; 例如 : 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
(4)组件
TSM 存储引擎主要由几个部分组成:cache、wal、tsm file、compactor 。
1)Cache :cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中 。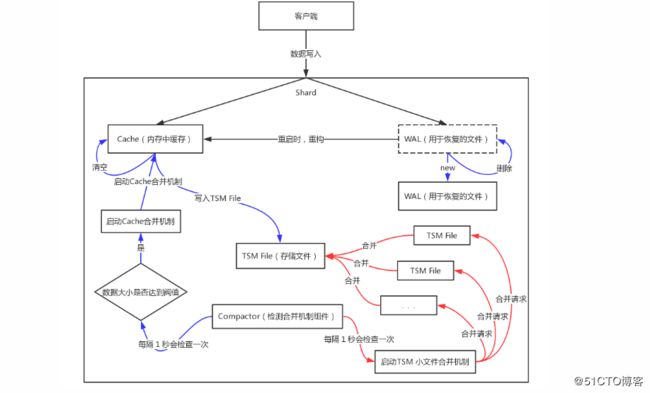
2)WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据 。
3) TSM File : 单个 tsm file 大小最大为 2GB,用于存放数据 。
4) Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据 。
主要进行两种操作 :
- 一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中 。
- 另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成 。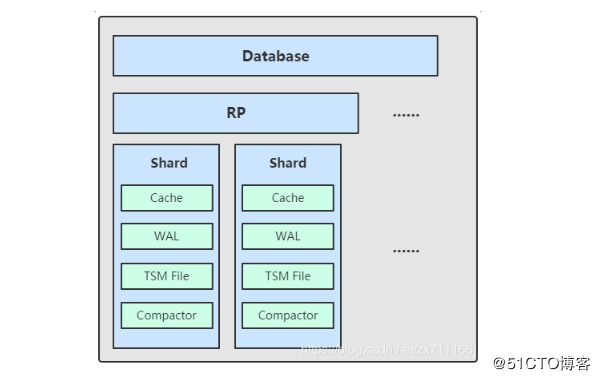
二、Influx部署安装
1. Influx下载
官网地址:https://dl.influxdata.com
#1.本地下载
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.1.0.x86_64.rpm
yum localinstall influxdb-1.1.0.x86_64.rpm
#2.在线yum 安装
#2.1配置yum源
cat <2. 启动Influx
#启动服务
systemctl start influxdb.service
#查看服务是否正常
systemctl status influxdb
#查看服务对应进程
ps aux | grep influx
Ps:
(1)8086端口:HTTP API的端口
(2)8088:备份和恢复时使用,默认是8088
3. Influx目录介绍
由于是使用yum 安装的所以安装后,Influx的目录会分布在 /usr/bin 、 /var/lib/influxdb/ 、 /etc/influxdb/ 下,下面我们一一介绍:
(1)/usr/bin 该目录下是存放相应命令操作的目录:
influxd influxdb服务器
influx influxdb命令行客户端
influx_inspect 查看工具
influx_stress 压力测试工具
influx_tsm 数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式)(2)/var/lib/influxdb/ 存放数据的目录
data 存放最终存储的数据,文件以.tsm结尾
meta 存放数据库元数据
wal 存放预写日志文件(3)/etc/influxdb/influxdb.conf 存放配置文件的目录
influxdb.conf 就是 influxdb的配置文件。
4. 配置参数介绍
Ps:在阅读配置参数的时,最好是对该数据库各个概念以及原理有一些了解,再去细看配置参数。
#编辑配置文件
vim /etc/influxdb/influxdb.conf
#以下=后面的都是默认值
reporting-disabled = false -- 该选项用于上报influxdb的使用信息给InfluxData公司
bind-address = "127.0.0.1:8088" -- 备份恢复时使用,默认值为8088
[meta]下
dir = "/var/lib/influxdb/meta" -- meta数据存放目录
retention-autocreate = true -- 用于控制默认存储策略
logging-enabled = true -- 是否开启meta日志
[data]下
dir = "/var/lib/influxdb/data" -- 最终数据(TSM文件)存储目录
wal-dir = "/var/lib/influxdb/wal" -- 预写日志存储目录
query-log-enabled = true -- 是否开启tsm引擎查询日志
cache-max-memory-size = "1g" -- 用于限定shard最大值,大于该值时会拒绝写入
cache-snapshot-memory-size = "25m" -- 用于设置快照大小,大于该值时数据会刷新到tsm文件
cache-snapshot-write-cold-duration = "10m" -- tsm1引擎 snapshot写盘延迟
compact-full-write-cold-duration = "4h" -- tsm文件在压缩前可以存储的最大时间
max-series-per-database = 1000000 -- 限制数据库的级数,该值为0时取消限制
trace-logging-enabled = false -- 是否开启trace日志
[coordinator] 下
write-timeout = "10s" -- 写操作超时时间
max-concurrent-queries = 0 -- 最大并发查询数,0无限制
query-timeout = "0s" -- 查询操作超时时间,0无限制
log-queries-after = "0s" -- 慢查询超时时间,0无限制
max-select-point = 0 -- SELECT语句可以处理的最大点数(points)0无限制
max-select-series = 0 -- SELECT语句可以处理的最大级数(series),0无限制
max-select-buckets = 0 -- SELECT语句可以处理的最大"GROUP BY time()"的时间周期,0无限制
[retention]下 ,旧数据的保留策略
enabled = true -- 是否开启该模块
check-interval = "30m" -- 检查时间间隔
[http] 下,influxdb的http接口配置
enabled = true -- 是否开启该模块
bind-address = ":8086" --绑定地址
auth-enabled = false -- 是否开启认证
log-enabled = true -- 是否开启日志
max-row-limit = 0 -- 配置查询返回最大行数
max-connection-limit = 0 -- 配置最大连接数,0无限制 以上是常见操作配置,具体细节请参考:
https://www.cnblogs.com/MikeZhang/p/InfluxDBInstall20170206.html
三、Influx常见操作
1. 常见DDL操作
Ps:以下操作可能与关系型数据库操作不同,如果对Influx不了解,请先阅读Influx介绍之后,在继续往下阅读。
#进入Influx数据库
[root@iZbp19ujl2isnn8zc1hqirZ ~]# influx
> show databases #显示所有数据库
> create database tes #创建数据库
> drop database test #删除数据库
> use test #进入数据库
> insert disk_free,hostname=server01 value=442221834240i #创建&& 插入数据
> select * from disk_free #查询数据
> show measurement #显示库中的所有表
> drop measurement disk_free #删除表我们发现以上猛如虎的操作中,进入没有类似create table的命令,这是为什么呢?
原来是因为: InfluxDB中没有显示的创建表的语句,只能通过insert数据的房还是来建立新表 。
insert disk_free,hostname=server01 value=442221834240i
-- 剖析以上命令的含义
disk_free 就是表名,hostname 是索引(tag),value=xx 是记录值(field),记录值可以有多个,系统自带追加时间戳。
-- 也可以手动添加时间戳
insert disk_free,hostname=server01 value=442221834240i 14353621895756921822. 数据保存策略(Retention Policies)
介绍: InfluxDB 是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
#查看当前数据库中的Retention Policies
>show retention policies on test
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false解释:
- name:名称,此示例名称为 default。
- duration:持续时间,0代表无限制。
- shardGroupDuration:shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
- replicaN:全称是replication,副本个数。
- default:是否是默认策略。
#创建新的Retention Policies
> create retention policy "rp_name" on "test" duration 3w replication 1 default
#修改Retention Policies
> alter retention policy "rp_name" on "test" duration 30d default
> show retention policies on test
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
rp_name 720h0m0s 24h0m0s 1 true
#删除Retention Policies
drop retention policy "rp_name" on "test"创建语句剖析:
create retention policy "rp_name" on "test" duration 3w replication 1 default- rp_name:保存策略名称
- test:所针对的数据库
- 3w : 保存3周,3周之前的数据将被删除,influxdb 具备各种事件参数,持续时间必须至少为1小时;比如:h(小时)、d(天)、w(星期) 。
- replication : 副本个数,一般为1即可。
3. 连续查询(Continuous Queries)
介绍: InfluxDB 的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 select 关键字 和 group by time() 关键字。 InfluxDB 会将查询结果放在指定的数据表中。
目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
创建语句:
CREATE CONTINUOUS QUERY ON
[RESAMPLE [EVERY ] [FOR ]]
BEGIN SELECT ()[,()] INTO
FROM [WHERE ] GROUP BY time()[,]
END 举例:
CREATE CONTINUOUS QUERY wj_30m ON test BEGIN SELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients) INTO redis_clients_30m FROM redis_clients GROUP BY ip,port,time(30m)
--解释:
在test数据库中新建了一个名为 wj_30m 的连续查询,每三十分钟取一个 connected_clients 字段的平均值、中位值、最大值、最小值从redis_clients表中并且插入到redis_clients_30m表中,使用的数据保留策略都是default。连续查询的其他操作:
#查看库中的连续查询
> show continuous queries
name: _internal
name query
---- -----
name: test
name query
---- -----
#删除Continuous Queries
> drop continuous query on 4. 用户管理与权限操作
用户管理:
#以xxx用户登录
$influx -username useer -password abcd
#显示所有用户
> show users
user admin
---- -----
zy true
#创建普通用户
> CREATE USER "username" WITH PASSWORD 'password'
#创建管理员用户
> CREATE USER "admin" WITH PASSWORD 'admin' WITH ALL PRIVILEGES
#为用户设置密码
> SET PASSWORD FOR = ''
#删除用户
> DROP USER "username" 权限设置:
#为一个已有用户授权管理员权限
> GRANT ALL PRIVILEGES TO
#取消用户权限
> REVOKE ALL PRIVILEGES FROM
#展示用户在不同数据库上的权限
> SHOW GRANTS FOR 5. Influxdb查询
关于Influxdb支持两种方式:类SQL查询和Http接口查询:
-- 类SQL查询(询最新的三条数据)
SELECT * FROM weather ORDER BY time DESC LIMIT 3
#Http接口查询
$curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=test" --data-urlencode "q=SELECT * FROM weather ORDER BY time DESC LIMIT 3"四、Influx的JAVA_API
1. InfluxDB的增删改查
这里小编以maven项目的结构,测试关于InfluxDB数据库的增删改查。
org.influxdb
influxdb-java
2.5
InfluxDBUtils:
import org.influxdb.InfluxDB;
import org.influxdb.InfluxDBFactory;
import org.influxdb.dto.Point;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
import java.util.Map;
/**
* * Created with IntelliJ IDEA.
* * User: ZZY
* * Date: 2019/11/15
* * Time: 10:10
* * Description:
*/
public class InfluxDBConnect {
private String username;//用户名
private String password;//密码
private String openurl;//连接地址
private String database;//数据库
private InfluxDB influxDB;
public InfluxDBConnect(String username, String password, String openurl, String database){
this.username = username;
this.password = password;
this.openurl = openurl;
this.database = database;
}
/**连接时序数据库;获得InfluxDB**/
public InfluxDB getConnect(){
if(influxDB==null){
influxDB=InfluxDBFactory.connect(openurl,username,password);
influxDB.createDatabase(database);
}
return influxDB;
}
/**
* 设置数据保存策略
* defalut 策略名 /database 数据库名/ 30d 数据保存时限30天/ 1 副本个数为1/ 结尾DEFAULT 表示 设为默认的策略
*/
public void setRetentionPolicy(){
String command=String.format("CREATE RETENTION POLICY \"%s\" ON \"%s\" DURATION %s REPLICATION %s DEFAULT",
"defalut", database, "30d", 1);
this.query(command);
}
/**
* 查询
* @param command 查询语句
* @return
*/
public QueryResult query(String command){
return influxDB.query(new Query(command,database));
}
/**
* 插入
* @param measurement 表
* @param tags 标签
* @param fields 字段
*/
public void insert(String measurement, Map tags, Map fields){
Point.Builder builder =Point.measurement(measurement);
builder.tag(tags);
builder.fields(fields);
influxDB.write(database,"",builder.build());
}
/**
* 删除
* @param command 删除语句
* @return 返回错误信息
*/
public String deleteMeasurementData(String command){
QueryResult query = influxDB.query(new Query(command, database));
return query.getError();
}
/**
* 创建数据库
* @param dbName
*/
public void createDB(String dbName){
influxDB.createDatabase(dbName);
}
/**
* 删除数据库
* @param dbName
*/
public void deleteDB(String dbName){
influxDB.deleteDatabase(dbName);
}
} pojo:
import java.io.Serializable;
/**
* * Created with IntelliJ IDEA.
* * User: ZZY
* * Date: 2019/11/15
* * Time: 10:07
* * Description:
*/
public class CodeInfo implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
private String code;
private String descr;
private String descrE;
private String createdBy;
private Long createdAt;
private String time;
private String tagCode;
private String tagName;
public static long getSerialVersionUID() {
return serialVersionUID;
}
}
//set and get method ...测试:
import org.influxdb.InfluxDB;
import org.influxdb.dto.QueryResult;
import java.util.*;
/**
* * Created with IntelliJ IDEA.
* * User: ZZY
* * Date: 2019/11/15
* * Time: 11:45
* * Description: 测试influxDB的增删改查
*/
public class Client {
public static void main(String[] args) {
String username = "admin";//用户名
String password = "admin";//密码
String openurl = "http://192.168.254.100:8086";//连接地址
String database = "test";//数据库
InfluxDBConnect influxDBConnect = new InfluxDBConnect(username, password, openurl, database);
influxDBConnect.getConnect();
//insertInfluxDB(influxDBConnect);
testQuery(influxDBConnect);
}
//向Measurement中插入数据
public static void insertInfluxDB(InfluxDBConnect influxDB) {
Map tags = new HashMap();
Map fields = new HashMap();
List list = new ArrayList();
CodeInfo info1 = new CodeInfo();
info1.setId(1L);
info1.setName("BANKS");
info1.setCode("ABC");
info1.setDescr("中国农业银行");
info1.setDescrE("ABC");
info1.setCreatedBy("system");
info1.setCreatedAt(new Date().getTime());
CodeInfo info2 = new CodeInfo();
info2.setId(2L);
info2.setName("BANKS");
info2.setCode("CCB");
info2.setDescr("中国建设银行");
info2.setDescrE("CCB");
info2.setCreatedBy("system");
info2.setCreatedAt(new Date().getTime());
list.add(info1);
list.add(info2);
String measurement = "sys_code";
for (CodeInfo info : list) {
tags.put("TAG_CODE", info.getCode());
tags.put("TAG_NAME", info.getName());
fields.put("ID", info.getId());
fields.put("NAME", info.getName());
fields.put("CODE", info.getCode());
fields.put("DESCR", info.getDescr());
fields.put("DESCR_E", info.getDescrE());
fields.put("CREATED_BY", info.getCreatedBy());
fields.put("CREATED_AT", info.getCreatedAt());
influxDB.insert(measurement, tags, fields);
}
}
//查询Measurement中的数据
public static void testQuery(InfluxDBConnect influxDB) {
String command = "select * from sys_code";
QueryResult results = influxDB.query(command);
if (results == null) {
return;
}
for(QueryResult.Result result:results.getResults()){
List series = result.getSeries();
for(QueryResult.Series serie :series){
System.out.println("serie:"+serie.getName()); //表名
Map tags =serie.getTags();
if(tags !=null){
System.out.println("tags:-------------------------");
tags.forEach((key, value)->{
System.out.println(key + ":" + value);
});
}
System.out.println("values:-----------------------");
List> values = serie.getValues(); //列出每个serie中所有的列--value 列为全大写
List columns =serie.getColumns(); //列出每个serie中所有的列
for(List 五、InfluxDB 导入导出数据
1. 数据导出
(1)普通导出
$influx_inspect export -datadir "/var/lib/influxdb/data" -waldir "/var/lib/influxdb/wal" -out "test_sys" -database "test" -start 2019-07-21T08:00:01Z
#命令解释
influx_inspect export
-datadir "/data/influxdb/data" # 勿动,influxdb 默认的数据存储位置
-waldir "/data/influxdb/wal" # 勿动,influxdb 默认的数据交换位置
-out "telemetry_vcdu_time" # 导出数据文件的文件名
-database telemetry_vcdu_time # 指定要导出数据的数据库
-start 2019-07-21T08:00:01Z # 指定要导出的数据的起始时间此时在当前目录下会出现一个名为test_sys的文件,查看文件内容:
(2)导出成CSV格式文件
$influx -database 'test' -execute 'select * from sys_code' -format='csv' > sys_code.csv此时在当前目录下就多出一个sys_code.csv的文件,查看文件内容:
2. 导入数据
$influx -import -path=telemetry_sat_time -precision=ns
#命令解释
influx
-import # 无参,勿动
-path=telemetry_sat_time # 指定导入数据的文件
-precision=ns # 指定导入数据的时间精度