在项目中经常会有对象拷贝属性的需求,类之间属性的拷贝,看似是一个简单的操作,其实通常也是工程里最花费时间的事情,毕竟这个年代不能老是不停地写setter和getter方法吧。
orika 给自己的定义是
simpler, lighter and faster Java bean mapping framework.
通过orika确实可以节约项目中大量的setter和getter方法。
这里假设我有这样两个类 BookEntity.java 和 BookDTO.java
public class BookEntity {
private String bookName;
private String authorName;
private Date authorBirthday;
// 一个Json字符串
private String bookInformation;
private Byte type;
// setter and getter
.......
}
public class BookDTO {
//
private String bookName;
// 有两个属性 name 和 birthday
private AuthorDTO author;
// 一个枚举类型
private BookType bookType;
// 一个类包含 ISBN 和 page
private BookInfo bookInfo;
// setter and getter
... ...
}
假设我们什么都不做只是最基本的使用orika进行默认地对象拷贝。
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
MapperFacade mapper = mapperFactory.getMapperFacade();
BookEntity bookEntity = new BookEntity(
"银河系漫游指南",
"道格拉斯·亚当斯",
Date.from(LocalDate.of(1952, Month.MARCH, 11).atStartOfDay(ZoneId.systemDefault()).toInstant()),
"{\"ISBN\": \"9787532754687\", \n \"page\": 279\n }",
new Integer(15).byteValue());
final BookDTO bookDTO = mapper.map(bookEntity, BookDTO.class);
得到的情况将会如下:

默认情况下,orika只会把两个类,名称相同的两个属性做相应的拷贝,当名称不相同的时候,可以通过配置来做对应的匹配。
首先是基本的类型匹配,在AuthorDTO中的两个属性 name 和 birthday 分别对应AuthorEntity的 authorName和 authorBirthday,那就可以在Orika中配置好
mapperFactory
.classMap(BookEntity.class, BookDTO.class)
.field("authorName", "author.name")
.field("authorBirthday", "author.birthday")
.byDefault()
.register();
这样配置之后,再次运行得到的结果就是:
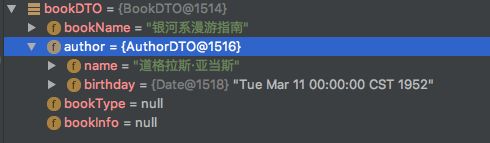
但是。。。。上面依旧还有两个属性的值是null, 其中bookType在BookDTO中是一个枚举类型,这种设计非常常见,在数据库中存tinyint类型的字段,而在表现层需要将这个数值转换成一个具体意义的枚举类型.另外一个属性bookInfo是一个类对象,而在BookEntity中是一个Json字符串,它也需要进行一番转换才能变成对应的数据。
这个时候需要额外多做一些配置才能让orika找到对应的数据了。
首先是 BookType 和 java.lang.Byte类型的转换,利用BidirectionalConverter类,定义他们的转换关系:
mapperFactory
.getConverterFactory()
.registerConverter("bookTypeConvert", new BidirectionalConverter() {
@Override
public Byte convertTo(BookType bookType, Type type, MappingContext mappingContext) {
return bookType.getVal();
}
@Override
public BookType convertFrom(Byte aByte, Type type, MappingContext mappingContext) {
return BookType.getSelf(aByte);
}
});
这样orika每次看到 BookType和 Byte之间的转化就会使用这个转换器来“拷贝”值了。
对于Json 和 String类型的转换,我定义了一个更加通用的Convert,这里Json的序列化工具使用的是fastjson
public class JsonConfigConvert extends BidirectionalConverter {
@Override
public String convertTo(T source, Type destinationType, MappingContext mappingContext) {
return JSON.toJSONString(source);
}
@Override
public T convertFrom(String source, Type destinationType, MappingContext mappingContext) {
return JSON.parseObject(source, destinationType.getRawType());
}
}
在配置中这样写:
mapperFactory
.getConverterFactory()
.registerConverter("bookInfoConvert", new JsonConfigConvert());
mapperFactory
.classMap(BookEntity.class, BookDTO.class)
.field("authorName", "author.name")
.field("authorBirthday", "author.birthday")
.fieldMap("type", "bookType").converter("bookTypeConvert").add()
.fieldMap("bookInformation", "bookInfo").converter("bookInfoConvert").add()
.byDefault()
.register();
再执行刚刚的代码就能得到完整的类了:

相比项目中大量的setter和getter,利用orika这种操作方式显然会节约大量的代码。